前言
大规模集群,通常是一家公司经过多年发展积累起来的,机器规模达到数万台,服务类型涉及接入、web、业务逻辑、cache、大数据、机器学习等,有以下特点,
| 特点 |
现象&问题 |
| 机器规模大, 过保机器多,故障率高 |
数万台机器的集群,过保机器超过30%,硬件故障率约1.3%,其中磁盘故障率约7.5% |
| 业务模块数目多,上下游关联复杂 |
处理机器问题需要同步处理上下游关系,包括监控、变更系统、状态同步等 |
| 机器环境差异大,故障处理、环境部署方式各异 |
环境设置不一样,包括系统、内核参数,基础环境依赖等 |
| 机器利用率不合理 |
A业务机器资源紧缺,B业务机器空闲,却无法快速调配使用 |
| 机器归属管理困难 |
不同业务的机器,借用、归还、环境清理、过保下架等流程冗长,沟通成本高 |
| 机器自动化处理工具不具备通用性,复用性低 |
A业务机器的自动处理工具,无法直接在B业务使用,运维工程师重复开发,无沉淀 |
这些问题,存在于整个机器生命周期里,从上架通电到下架报废,不定期制造业务故障,例如因机器故障导致的部署失败、版本不一致、读写异常、性能陡降等;日常消耗一线运维10%~20%的时间,还造成大量的机器、机架资源浪费,得不到有效利用。
本系列文章目录如下,讲述了解决这些问题的方案和实现,实际效果,踩过的坑,希望对读者有帮助。
-
机器运维相关的数据
-
机器运维模式的思考
-
机器故障自动处理
-
机器基础环境管理
-
大规模集群机器快速交付
-
机器日常运维效率
注: 运维工程师= SRE = OP,这三个名词有各自的定义,为表述方便,这里简单地认为是同义词。
1. 机器运维相关的数据
一切从一次机器“摸底排查”开始。
排查的结果是: 数万台机器的集群,过保机器约占30%,硬件故障率约1.3%,其中磁盘故障率约7.5%,这意味着近千台整机,几千块磁盘处于故障状态,还有数量不小的过保机器、无主机器无人跟进处理,机器资源浪费严重。
同时,我们访谈了各业务线运维同事,从前端web到后端存储,从在线到离线,询问“关于机器运维存在什么问题”,得到了各式各样无法量化的“苦水”;
-
“Oncall 每周都要重启、报修十几台机器,又摘服务又传数据又恢复服务什么的,烦死了”
-
“上线部署时,老是有一些机器部署失败,都是些死机、根目录读写失败的,处理这些长尾要几个小时”
-
“这次case study 是机器坏了修好后忘了同步程序,版本不一致,部署时把老版本程序带起来了,这太坑了!”
-
“喂,键盘仔,limits参数没改,服务起不来啊”
-
“你这自动处理系统不行啊,把有数据的机器重装了,数据丢了,你发故障报告吧!”“谁叫你不认真看我的文档啊,我这是前端机器故障处理系统,你有业务数据就不能用! 你发!”
-
“业务紧急扩容,借我们50台机器吧”, 1个小时过去了,sre还在确认这些机器上各个服务都是谁的,要停服
-
…
这个苦水列表还可以再列好多条,我反问他们为什么平时不反馈出来,原因大体都是:
这些问题都是零碎的,平时这几台机器死机,那几台机器掉块盘,还有些机器处于薛定谔状态,内存报CE\UE信息, 不知道什么时候会出问题;
反馈出来,经理强调一下,大家集中处理一波,故障数量暂时下去之后,积攒一段时间又上来,如此反复,endless。
通过统计机器故障、细化机器操作任务耗时、历史故障case的方式,我们得到了以下数据:
-
过保机器约占30%,硬件故障率约1.3%,其中磁盘故障率约7.5%
-
机器运维任务占一线运维工程师总时间的20%左右
-
因机器故障导致的业务故障,平均每个月有1~3次
所以我们要从业务稳定性、运维效率、硬件成本出发,解决这些问题。
1. 机器运维模式的思考

在传统的运维模式里,机器归属天然是按业务来分的,即某个业务的运维工程师负责本业务机器的运维工作。这种划分方式存在以下问题,
-
- 重复投入人力,如机器故障维修,各业务工程师都要做故障检测、服务离线、硬件维修、环境初始化、服务上线等相同流程的工作,且由于业务的差异(如无状态的web服务,有状态的存储、模型计算服务),实现的方案不具备通用性
- 工程师的主要工作是业务运维,没有精力去解决机器任务长尾、自动化安全性、通用性、扩展性问题,已实现的方案无法复用,机器运维效率没有真正提高

针对传统运维模式存在的问题, 我们在运维人员和机器之间加入了“机器管理系统”,消除机器环境、故障修复流程等差异,统一提供故障管理、环境管理、归属管理、任务管理、统计管理的功能组件,向运维工程师屏蔽机器运维细节,提高机器运维操作效率、机器资源利用率;
同时考虑了可扩展性、通用性,即新业务机器可低成本地纳入管理、不同业务类型的处理逻辑可通过插件的方式集成到系统中,有利于自动化程度的提升,工具的复用,自动化任务的沉淀。
通过这种方式,逐步提高机器运维效率,减少故障机器的积攒,而故障机器的减少,间接提高了稳定性。
2. 机器故障自动处理
我们从最大的痛点开始,一线运维日常要花费大量人力处理机器故障,如下图所示,
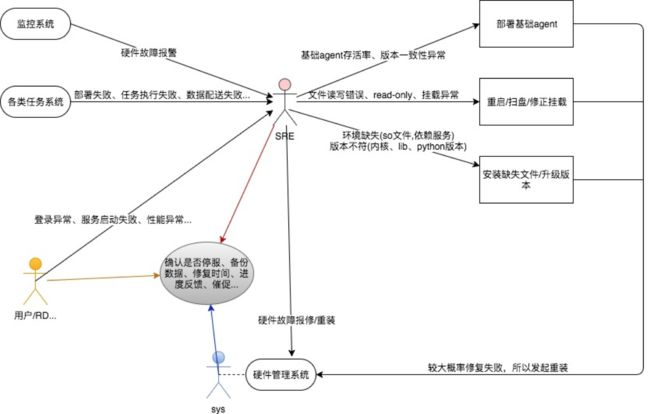
监控系统监控到硬件故障、任务系统执行失败、rd使用机器时的异常,都需要运维工程师来处理。
为什么做不到自动化?我们围绕以下4方面来分析。
- 通用性与差异化
- 通用设计与具体实现的关联
- 自动化与安全
- 流程、闭环、扩展性
通用性与差异化
在不同的环境里,故障自动处理过程的差异化是非常大的。
1. 如果是无状态服务,比如 nginx web服务、java application服务,通常只需要重启机器、重刷环境、重新部署服务就可以,如果是硬件故障,可以直接报修,不用处理上下游。
2. 如果是有状态服务,比如索引服务、推荐服务、模型训练服务,业务方是希望尽可能在不重启机器的情况下修复,更不能直接报修重装,因为这涉及上下游关系更新、部署系统摘除、数据迁移等一系列工作,耗时从几个小时到几天都有可能。
3. 对于不同故障,不同业务的处理方式也不一样。例如,
内存、cpu、风扇这些硬件故障,不一定会马上死机,但存在宕机风险,无状态服务可以接受一旦出现这些风险就直接停服报修,而有状态服务不允许;
对于系统故障,比如文件系统异常,出现 Input/Output Error,此时系统已经异常,基础agent 已经无法正常工作,部署、执行任务都会失败,但服务还正常跑着,所以业务不希望停机;
对于基础环境文件缺失,业务更是希望不停机。
4. 机器修复后,服务恢复的方式也不一样,无状态服务只要保证和线上版本一致就行; 而有状态服务,涉及从哪里拷数据,拷完后启动加载数据,确认加载完之后,才能引流。
可以看到,这么多的差异,是各业务线的机器运维工具无法复用的原因,
如果仍然按现有模式来做自动维修,可以预见的结果是,新系统也会陷入一大堆的复杂修复逻辑的泥潭里,所以我们第一个要解决的就是通用性问题。
经过分析抽象不同业务的维修流程,得到一个通用的维修流程:故障检测、服务离线、故障维修、环境初始化、服务上线,如下图,
![]()
这个流程,不管是有状态服务,还是无状态服务,以何种方式维修,都可以覆盖。
通用设计与具体实现的关联
第二个问题,通用流程如何与具体的差异化逻辑关联。
比如针对“故障维修”这个环节,“磁盘硬件故障修复”和“文件系统异常修复”是不同的,如何关联起来,有两个思路:
1按现有模式,各自写一个修复工具,遇到什么样的问题,就调用那个修复工具。这种方式,效率、成本、效果都不好,因为总会有新的问题出现,就得写新的修复工具,写完后还得重新加载注册修复工具,设置问题与工具的对应关系,然后还得保证修复工具的成功率,这些都是成本。
2 经过运维工程师们讨论,最终的修复方法是两个原子操作:重启、重装。
因为,修复工具也有较大的概率修复失败,当修复工具也修不好时,只能重装,还不如一开始就选择重装。
比如磁盘文件系统故障,选择单盘在线修复重新挂载,这个过程异常艰难,lsof找出占用磁盘的服务,kill / fuser 停服,umount磁盘,修改fstab,fsck/fdisk,mount,这么复杂且耗时的操作下来,可能大概率修不好,真是一顿操作猛如虎,一看成功率二点五; 而选择重装,无硬件问题的,基本30分钟内交付,有硬件故障需要更换配件的,也有SLA 约定的交付时间。
据此我们得到一张“简单粗暴”的表格,
| 故障类型 |
处理方式 |
备注 |
| 宕机故障 |
重启 |
如果重启失败,当作硬件故障,走重装 |
| 硬件故障 |
重装 |
硬件故障包括:cpu/内存/磁盘/风扇/电源故障 |
注: 系统部在重装机器时,会对硬件进行检测,如果有硬件故障,会先修复再重装
自动化与安全
这个问题,是从稳定性、安全角度考虑的。
如果自动化之后,效率是提高了,但是重启/重装错了机器,那还不如不搞自动化,所以自动任务的安全策略也作为重点考虑,在真正开始执行自动任务之前,设置多道防线,例如白名单/阈值/服务容量等,更多安全策略细节,将在后续章节中阐述。
加入安全策略后的流程:
![]()
流程、闭环、扩展性
如何把上述流程衔接起来? 工作流天然就是干这个的。
但是这里的“衔接”,有运维角度看重的要求: 闭环 和 扩展性。
下面这张图展示了 闭环、扩展性的特性。
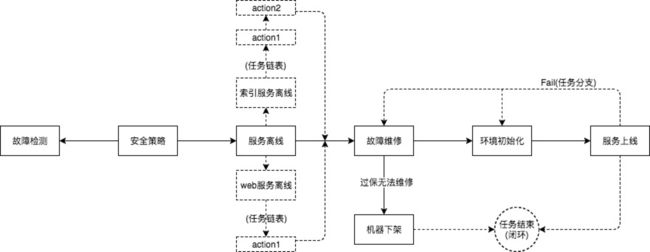
1 闭环
在以往的机器自动化工具中,始终面临一个棘手问题,就是自动化任务的“中断”,
比如,
自动任务发起重启,超过1小时未启动
发起硬件维修的机器,超过规定时间仍未交付
中断之后,往往没有后续的处理动作,通常都是机器的使用方催促了,才去人工介入处理,这使得rd、sre都觉得“自动化工具并不自动,非常挫!”。
我们通过 “任务分支“ 来解决“中断”的问题。
一台机器出现故障后,是有明确的状态的,要么机器修复,恢复上线;要么机器不可修复(通常是过保),下架处理;从图中可以看到,如果“故障维修”环节无法完成,则系统可以执行“机器下架”分支,最终达到流程结束的状态,而不是“机器发起维修了,但是很久也没有交付“的中间状态。
有了任务分支,就无需人工介入,形成闭环,最大程度地保证了自动化。
2 扩展性
服务上下线,是一个复杂的过程,涉及新部署一个实例,数据拷贝,从上游摘除等操作, 这就要求系统能方便地、低成本地增加任务节点。
我们通过任务链表来实现,从图中“服务离线”环节可以看到,action 是可以扩展数量和指定顺序的,实现细节会在后续章节中阐述。
经过上面的分析,可知自动维修系统由几个关键子系统组成,
1 工作流系统
2 故障检测
3 安全策略
4 维修工具及SLA
下一篇开始阐述具体的实现。