linux安装hadoop集群(3)-运行Java程序
第一篇 linux安装hadoop集群(1)-准备工作
第二篇 linux安装hadoop集群(2)-配置安装
本篇 linux安装hadoop集群(3)-运行Java程序
1 准备文件
[root@hpmaster chy]# pwd
/usr/chy
[root@hpmaster chy]# ls
temperature-01
2 文件内容
[root@hpmaster chy]# cat /usr/chy/temperature-01
1985 07 31 02 200
1985 07 31 03 172
1985 07 31 04 156
1985 07 31 05 133
1985 07 31 06 122
1985 07 31 07 117
1985 07 31 08 111
1985 07 31 09 111
1985 07 31 10 106
1985 07 31 11 100
3 上传hdfs
[root@hpmaster sbin]# hdfs dfs -mkdir /chy-data/input
[root@hpmaster sbin]# hdfs dfs -put /usr/chy/temperature-01 /chy-data/input/temperature-014
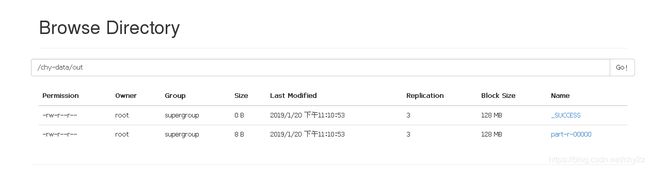
5 浏览文件
http://hpmaster:50070/explorer.html

6 编写java程序
public class Temperature extends Configured implements Tool {
public static class TemperatureMapper extends Mapper< LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//数据示例:1985 07 31 02 200
String line = value.toString(); //读取每行数据
int temperature = Integer.parseInt(line.substring(14, 16).trim());//气温值
FileSplit fileSplit = (FileSplit) context.getInputSplit();
//通过文件名称获取气象站id
String weatherStationId = fileSplit.getPath().getName();
//map 输出
context.write(new Text(weatherStationId), new IntWritable(temperature));
}
}
public static class TemperatureReducer extends
Reducer< Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable< IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
//循环values,对统一气象站的所有气温值求和
for (IntWritable val : values) {
sum += val.get();
count++;
}
//求每个气象站的平均值
result.set(sum / count);
//reduce输出 key=weatherStationId value=mean(temperature)
context.write(key, result);
}
}
/**
* @function 任务驱动方法
* @param args
* @return
* @throws Exception
*/
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();//读取配置文件
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {//删除已经存在的输出目录
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "temperature");//新建一个任务
job.setJarByClass(Temperature.class);// 主类
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.setMapperClass(TemperatureMapper.class);// Mapper
job.setReducerClass(TemperatureReducer.class);// Reducer
job.setOutputKeyClass(Text.class);//输出结果的key类型
job.setOutputValueClass(IntWritable.class);//输出结果的value类型
job.waitForCompletion(true);//提交任务
return 0;
}
/**
* @function main 方法
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String[] args0 = {
"/chy-data/input", //输入文件
"/chy-data/out" //输出结果
};
int ec = ToolRunner.run(new Configuration(), new Temperature(), args0);
System.exit(ec);
}
}注意:
String[] args0 = {
"/chy-data/input", //输入文件目录,也可以指定文件
"/chy-data/out" //输出结果目录
};
8 程序打包 jar
firstApp-1.0-SNAPSHOT.jar
9 上传hadoop集群服务器
[root@hpmaster java]# pwd
/usr/local/hadoop-2.7.6/bin/java
[root@hpmaster java]# ls
firstApp-1.0-SNAPSHOT.jar
10 执行程序
[root@hpmaster bin]# pwd
/usr/local/hadoop-2.7.6/bin
[root@hpmaster bin]# hadoop jar java/firstApp-1.0-SNAPSHOT.jar com.chy.Temperature.Temperature
[root@hpmaster bin]# hadoop jar java/firstApp-1.0-SNAPSHOT.jar com.chy.Temperature.Temperature
19/01/21 00:00:36 INFO client.RMProxy: Connecting to ResourceManager at hpslave1/192.168.199.211:8032
19/01/21 00:00:37 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/01/21 00:00:38 INFO input.FileInputFormat: Total input paths to process : 2
19/01/21 00:00:38 INFO mapreduce.JobSubmitter: number of splits:2
19/01/21 00:00:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1547990789982_0005
19/01/21 00:00:39 INFO impl.YarnClientImpl: Submitted application application_1547990789982_0005
19/01/21 00:00:39 INFO mapreduce.Job: The url to track the job: http://hpslave1:8088/proxy/application_1547990789982_0005/
19/01/21 00:00:39 INFO mapreduce.Job: Running job: job_1547990789982_0005
19/01/21 00:00:51 INFO mapreduce.Job: Job job_1547990789982_0005 running in uber mode : false
19/01/21 00:00:51 INFO mapreduce.Job: map 0% reduce 0%
19/01/21 00:01:03 INFO mapreduce.Job: map 50% reduce 0%
19/01/21 00:01:05 INFO mapreduce.Job: map 100% reduce 0%
19/01/21 00:01:17 INFO mapreduce.Job: map 100% reduce 100%
19/01/21 00:01:17 INFO mapreduce.Job: Job job_1547990789982_0005 completed successfully
19/01/21 00:01:18 INFO mapreduce.Job: Counters: 50
File System Counters
.......
Job Counters
.......
Map-Reduce Framework
.......
Shuffle Errors
.......
File Input Format Counters
Bytes Read=360
File Output Format Counters
Bytes Written=3611 查看执行结果
[root@hpmaster sbin]# hadoop fs -ls /chy-data/out
Found 2 items
-rw-r--r-- 3 root supergroup 0 2019-01-20 23:10 /chy-data/out/_SUCCESS
-rw-r--r-- 3 root supergroup 8 2019-01-20 23:10 /chy-data/out/part-r-00000
[root@hpmaster sbin]# hdfs dfs -cat /chy-data/out/part-r-00000
temperature-01 13
temperature-02 16
http://hpmaster:50070/explorer.html
http://hpslave1:8088/cluster
