Spark架构、原理、缓存
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌
1、 Spark 组件架构
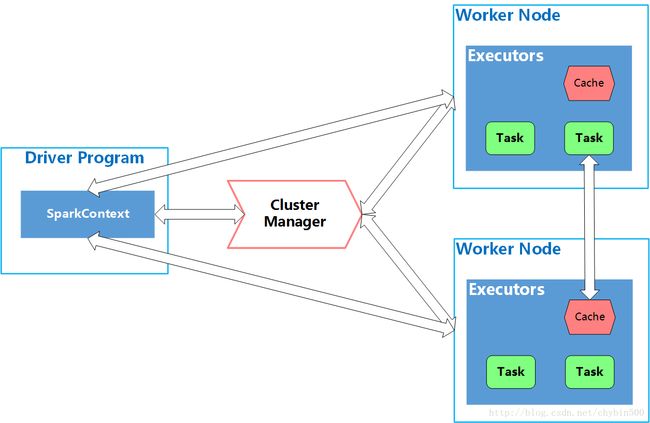
Spark应用的运行架构主要分三部分:Driver、Worker Node、ClusterManager Manager。一个job是从driver开始的,driver本质上起监督的作用,保持与集群中其他实体之间的联系,并将任务提交给worker节点执行,worker节点执行executors进程,这些进程有一个或多个task。ClusterManager集群管理器负责对Application所需资源进行管理。
(1)Driver
Driver Program负责启动和管理运行Spark Job,Spark在Driver Program的main函数中,创建一个SparkContext的实例,使用SparkContext来提交Job。Driver是维护所有worker node连接的实体,并将Spark job的逻辑代码转换为物理命令。
另外,Driver维护Spark运行的上下文(context),维护程序状态、设置、可用资源等。
还有,Driver处理与集群管理器ClusterManager(比如YARN)进行通信,请求资源,一旦获得资源,Driver就会根据程序逻辑创建一个执行计划,把它提交到所分配的worker节点上,这个执行计划是包括action操作和transformation转换操作的有向无环图DAG。然后将这个DAG分解为一个个的stage(步骤),再分解为task(任务),在分解为task时候,是根据RDD数据的分区进行分解的,一个分区创建一个task。分解成了task后将这些task分配给各个worker node上executor上执行。假若Spark运行在YARN上,Driver就起Appliction Master的左右。
(2)Worker Node
Spark中,Worker Node是集群中用来运行代码的机器,一个Worker Node上运行一个或者多个executor进程,每个executor进程运行一个JVM虚拟机,封装了对CPU、内存、磁盘资源的操作,每个executor进程中创建一个或者多个task线程。
(3)Cluster Manager
Cluster Manager是个外部的服务,主要起管理资源的作用,它可能是standalone manager、Mesos,YARN。
2、 Spark Application组成结构图

(1) Application Jar:一个jar包包含了用户的Spark Application,一个jar包可以有很多Spark Application。
(2) Spark Application只指创建在Spark上的用户程序,包括集群上的Driver Program和Executors两部分。一个Spark Application有多个Job,Job是一个并行的计算,包含多个task,通常RDD一个Action执行时就触发一个Job。
(3) 每个Job有多个stage,每个Stage之间是相互依赖的
(4) 每个stage有多个task,每个task是一个线程,每个task业务逻辑相同,数据不同
3、 Spark 缓存
Spark执行计算后得到的RDD结果数据,可以缓存到内存或者硬盘中,以便之后直接使用而不必再次进行计算。有两个方法可以实现缓存:cache()和persist(),二者之间的区别是cache()是将数据只是缓存到内存中,如果存不下,就只存一部分分区的数据,没有存下的数据需要重新计算。persist()方法提供了一个用于指定存储级别的API,能更加灵活地控制缓存方式。清除缓存使用unpersist()方法。
(1) persist()可以指定的存储级别有:
- 仅存于内存:使用这种类型的存储级别时,会将Rdd数据以为序列化Java对象的形式存储于内存中,如果Spark发现不能将所有rdd分区数据都存储内存,那就存储一部分,当要使用未存储的部分数据时,会重新计算他们。这个存储级别优点是读取速度快,缺点是占用内存大。使用这种缓存方式,代码如下:
splitDataRdd.cache();
splitDataRdd.persist(StorageLevel.MEMORY_ONLY());- 序列化形式仅存于内存:这种存储级别下,Rdd数据也存于内存中,但是是以java序列化对象形式保存的,同仅存于内存,如果内存中不够,就将一部分丢弃,使用时重新计算那部分。优点是数据序列化后数据更紧凑,占用内存更小。缺点是每次读取都需要进行序列化或者反序列化,占用更多的CPU运算。使用这种缓存方式,代码如下:
splitDataRdd.persist(StorageLevel.MEMORY_ONLY_SER());- 存于内存和磁盘:这种存储级别下,Spark尝试将在内存中存储整个未序列化的Rdd数据,当如果不能全部存进内存时,就溢写到磁盘中。优点是后续读取数据不会再重新计算,缺点是也要占据大量内存,另外因为要读取磁盘,所以会带来I/O操作。使用这种缓存方式,代码如下:
splitDataRdd.persist(StorageLevel.MEMORY_AND_DISK());- 序列化形式存于内存和磁盘:与上面的“存于内存和磁盘”的方式类似,不同之处是数据是以序列化形式存储的。优点是序列化后数据更加紧凑,占用空间更少;缺点序列化和反序列化需要更多的计算。使用这样缓存方式,代码如下:
splitDataRdd.persist(StorageLevel.MEMORY_AND_DISK_SER());- 仅存于磁盘:这种存储级别可以避免内存消耗,在存入磁盘时也进行了序列化,占用磁盘也比较少,但是数据读写过程涉及到序列化、反序列化、磁盘I/O,CPU计算。使用这样的缓存方式,代码如下:
splitDataRdd.persist(StorageLevel.DISK_ONLY());- 缓存在两个节点上:上面所有的存储级别都可以应用到集群的两个节点上,RDD数据都将复制到两个worker节点的内存或者磁盘里,使用这样的缓存方式,代码如下:
splitDataRdd.persist(StorageLevel.MEMORY_ONLY_2());
splitDataRdd.persist(StorageLevel.MEMORY_ONLY_SER_2());
splitDataRdd.persist(StorageLevel.MEMORY_AND_DISK_2());
splitDataRdd.persist(StorageLevel.MEMORY_AND_DISK_SER_2());
splitDataRdd.persist(StorageLevel.DISK_ONLY_2());- 堆外存储:这种存储级别,序列化的RDD将保存在Tachyon的堆外存储上,好处是可以在executor和其他应用之间共享一个内存池,减少垃圾回收带来的消耗,也能避免在executor崩溃时丢失内存内缓存数据的问题。代码如下:
splitDataRdd.persist(StorageLevel.OFF_HEAP());(2) 在使用缓存时需要注意:当将一个数据缓存进入内存时,如果内存不够用了,就会将其他最近最久未被使用的那个分区从内存中清除掉,虽然Spark cache是可以容错的,当使用时会重新计算丢失的数据,但是缓存了无用的数据,确实会无谓地增加执行时间。
(3) SparkSQL缓存
可以对将要多次查询的表进行缓存,表会以列式存储在内存中,这样在对表一部分列进行查询时,就不需要对整个数据集进行全部扫描。表缓存的方式有: