【Class 20】【实例】python 爬虫简单案例实现二---将数据保存为CSV文件
摘抄一位网友的写入和读取csv的代码:
#输出数据写入CSV文件
import csv
data = [
("Mike", "male", 24),
("Lee", "male", 26),
("Joy", "female", 22)
]
#Python3.4以后的新方式,解决空行问题
with open('d://write.csv', 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
for list in data:
print(list)
csv_writer.writerow(list)
#读取csv文件内容
import csv
list = []
reader = csv.reader(open("d://demo.csv"))
#csv中有三列数据,遍历读取时使用三个变量分别对应
for title, year, director in reader:
list.append(year)
print(title, "; ", year , "; ", director)
print(list)
我们在前面 class 19 中,将保存为csv的功能加入进去:
保存csv的代码如下
# 保存数据为csv格式
def __SaveCSV(self, anchors):
with open('d://PandaTV_data.csv', 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
for value in anchors:
csv_writer.writerow([value['name'], value['number']])
完整代码如下:
# Ciellee 2019-02-24 22:00
# 爬虫前奏:
# 明确目的: 获取熊猫TV 英雄联盟主播人气排行榜
# 找到数据对应的网页:https://www.panda.tv/cate/lol?pdt=1.c_lol.psbar-ca0.0.29u3363v9n8
# 分析网页的结构,找到数据所在的标签位置: video-info { video-nickname, video-number }
# 待分析网页数据
#
# LPL春季赛RW vs EDG
# LPL熊猫官方直播2台
# 678.9万
#
# 模拟HTTP请求,向服务器发送个请求,获取到服务器返回给我们的HTML
# 用正则表达式提取我们要的数据 video-nickname,video-number
from urllib import request
import re
import csv
class Spider():
url = 'https://www.panda.tv/cate/lol?pdt=1.c_lol.psbar-ca0.0.29u3363v9n8'
# 匹配字符串 \s\S: 匹配所有字符串 *:匹配无限多个 ?:采用非贪婪模式
root_pattern = '([\s\S]*?)'
name_pattern = ''
number_pattern = '="video-number">([\s\S]*?)'
# 私有方法,访问网页
def __fetch_content(self):
r = request.urlopen(Spider.url)
# 类型为字节码,bytes
htmls = r.read()
#print(type(htmls))
# 将字节码转换为字符串文本
htmls=str(htmls, encoding='utf-8')
#print(type(htmls))
return htmls
# 分析文本
def __analysis(self,htmls):
root_html = re.findall(Spider.root_pattern, htmls)
#print(type(root_html))
#print(root_html[0])
# 新建一个空字典
anchors = []
for html_tmp in root_html:
name = re.findall(Spider.name_pattern, html_tmp)
number = re.findall(Spider.number_pattern, html_tmp)
# 将name 和 number 拼成一个字典
anchor = {'name':name, 'number':number}
anchors.append(anchor)
#print(anchors[0])
return anchors
# 对数据进行修饰
# strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
def __refine(self, anchors):
lam = lambda anchors:{
'name':anchors['name'][0].strip(),
'number':anchors['number'][0]
}
return map(lam, anchors)
# 对数据进行分析,排序
def __sort(self, anchors):
anchors = sorted(anchors, key=self.__sort_seed, reverse=True)
return anchors
# 排序的key, 将number从字符串提取为整数
def __sort_seed(self, anchor):
r = re.findall('\d*\.*\d*', anchor['number'])
number = float(r[0])
#print(number)
if '万' in anchor['number']:
number *= 10000.0
#print(number)
return number
# 显示数据
def __show(self, anchors):
#for anchor in anchors:
for rank in range(0, len(anchors)):
print('第' + str(rank+1) + '名' + ' : '
+ anchors[rank]['name'] +' ------ '+anchors[rank]['number'] + '人')
# 保存数据为csv格式
def __SaveCSV(self, anchors):
with open('d://PandaTV_data.csv', 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
for value in anchors:
csv_writer.writerow([value['name'], value['number']])
# 用户接口
def go(self):
# 访问网页
htmls = self.__fetch_content()
# 解析数据
anchors = self.__analysis( htmls )
# 对数据进行修饰
anchors = list( self.__refine(anchors) )
# 分析数据,排序
anchors = self.__sort(anchors)
# 保存数据为csv格式
self.__SaveCSV(anchors)
# 显示打印数据
#self.__show(anchors)
#print( anchors )
spider = Spider()
spider.go()
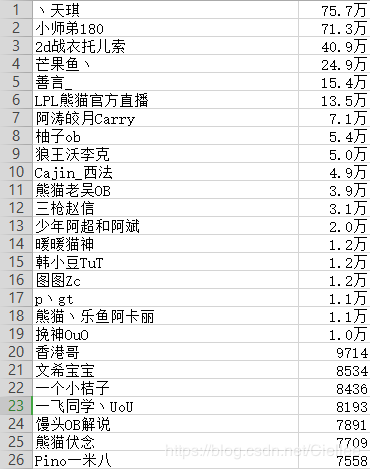
结果如下: