服务链路追踪Zipkin实战演示
一、简介
Zipkin是啥?自行百度
最近看了好多的博客,写的内容都比较老了,而且不是很完整,所以决定自己写一个,不足之处大家可以补充!
二、环境信息
- Zipkin服务端(Zipkin-server)
服务端可以有很多中启动方式,这里用java -jar 启动
执行以下两条命令:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
这样下载下来的jar包是最新的版本
java -jar zipkin.jar
访问本地地址localhost:9411
我是用的虚拟机跑的所以地址是192.168.17.11
这样一个最简单的Zipkin服务器已经启动了,单独一个服务器是没用的,还需要客户端来配合使用才可以;
2.Zipkin客户端,一个服务提供者(zipkin-provider),一个服务消费者(zikpin-consumer)
这里说的客户端就是一个springboot的简单应用,可以实现相互调用即可,只要是pom文件和yml文件的配置
pom依赖加上以下两个即可;
org.springframework.cloud
spring-cloud-starter-zipkin
//客户端与zipkin-server之间增加缓存类的中间件,例如redis、MQ等,在zipkin-server程序挂掉或重启过程中,客户端依旧可以正常的发送自己收集的信息,不用的话可以把下面的注释掉
org.springframework.cloud
spring-cloud-starter-stream-rabbit
我用的springcloud版本
Greenwich.SR1
springboot版本(v2.1.3.RELEASE)
yml配置文件
加上以下代码:
spring:
zipkin:
base-url: http://localhost:8762
sleuth:
sampler:
rate: 1这样客户端既可以和服务端相互通信了;
然后用zikpin-consumer 调用zipkin-provider 这一条调用记录就会展示在Zipkin-server 的管理界面上;
注意点:
A.以上的配置只是测试用的,如果用于生产环境,sleuth.sampler.rate 不能设置成1
sleuth采样率,默认为0.1,值越大收集越及时,但性能影响也越大
B.为了测试方便,我们可以将数据保存到内存中,但是生产环境还是需要将数据持久化的,原生支持了很多产品,例如ES、数据库等,参考下面的配置。
3.Mysql+Rabbitmq(升级版本)
A.首先安装Mysql和Rabbitmq
在mysql先创建一个库zipkin 再执行以下语句:
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
B.启动Zipkin服务端
使用rabbitMq+mysql:STORAGE_TYPE=mysql RABBIT_ADDRESSES=localhost RABBIT_USER=admin RABBIT_PASSWORD=admin MYSQL_USER=root MYSQL_HOST=192.168.17.1 MYSQL_PASS=123456 java -jar zipkin.jar
C.修改客户端yml文件
spring:
sleuth:
sampler:
rate: 1
rabbitmq:
host: 192.168.17.11
port: 5672
username: admin
password: adminD.用zikpin-consumer 调用zipkin-provider,数据会存储到Mysql里面
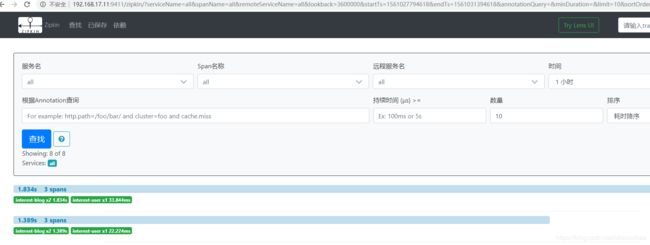
http://192.168.17.11:9411/metrics

三、技术栈
SpringBoot
Zipkin
Mysql
Rabbitmq
四、代码演示
https://github.com/openzipkin/zipkin/tree/master/zipkin-server
https://github.com/openzipkin/docker-zipkin
五:推荐博客:
https://www.cnblogs.com/duanxz/p/7552857.html
这一篇写的还不错,不过版本有点低,已经不适用了,可以参考以下