Spark
1、Spark起源:
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处,Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。从各方面报道来看Spark抱负并非池鱼,而是希望替代Hadoop在大数据中的地位,成为大数据处理的主流标准,不过Spark还没有太多大项目的检验,离这个目标还有很大路要走。
2、Spark特点:
速度快:DAG有向无环图执行引擎数据流和内存计算支持,速度极快。
易用性:可用多种语言编写。
通用性:RDD抽象数据集在不同业务间转换。
跨平台:多种模式下运行。
3、Spark与hadoop区别:
Spark把中间数据放到内存中,减少磁盘I/O操作,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。
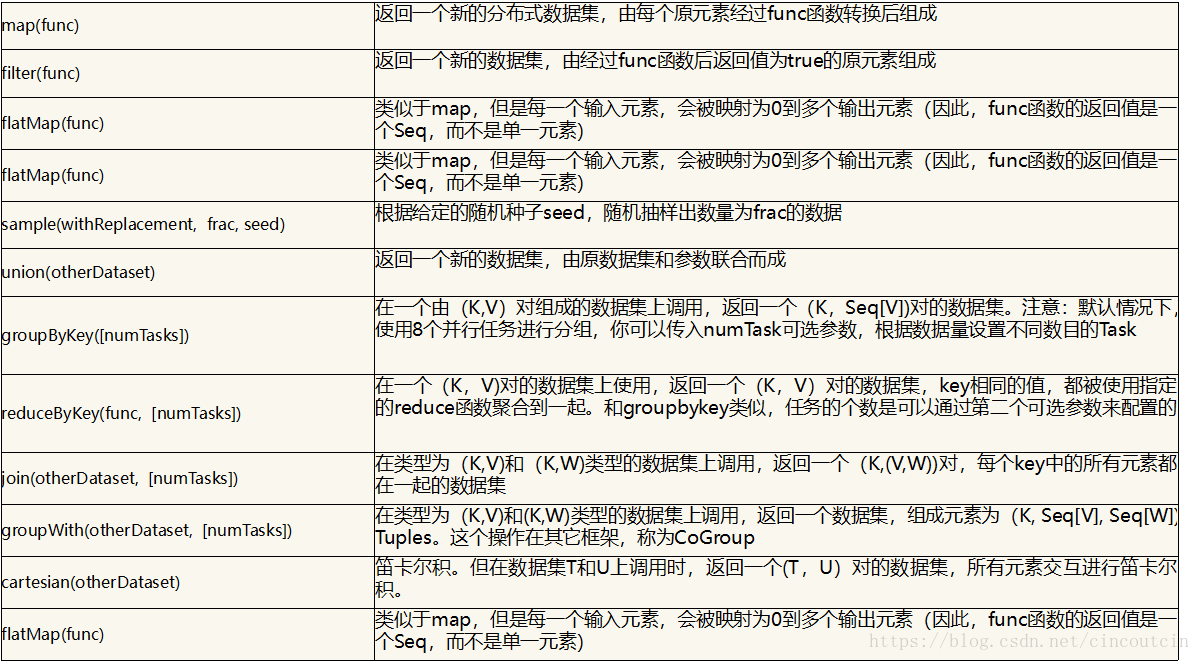
Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
4、Spark体系结构:

由Driver和Executor两部分。
5、Spark运行模式:
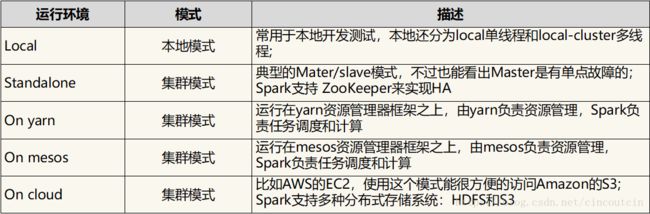
6、Spark数据模型:
RDD(Resillient Distributed Dataset 弹性分布式数据集):Spack核心的数据结构。
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升非常大。
RDD特征:只读、容错、分布式存储、丰富的操作
来源:一种是从持久存储获取数据,另一种是从其他RDD生成只读:状态不可变,不能修改
分区:支持元素根据 Key 来分区 ( Partitioning ) ,保存到多个结点上,还原时只会重新计算丢失分区的数据,而不会影响整个系统
路径:在 RDD 中叫世族或血统 ( lineage ) ,即 RDD 有充足的信息关于它是如何从其他 RDD 产生而来的
持久化:可以控制存储级别(内存、磁盘等)来进行持久化
操作:丰富的动作 ( Action ) ,如Count、Reduce、Collect和Save 等
RDD的执行过程:
1、创建(4种方式):
1、1从Hadoop文件中创建。
从Hadoop支持的存储类型的数据源生成RDD,包括本地文件系统、HDFS、Amazon S3等。
val rdd1 = sc.textFile("file:///root/access_log/access_log*.filter");
val rdd1 = sc.textFile(“hdfs://…");
val rdd1 = sc.textFile(“s3n://…");
每条记录包含一行文件
1、2从父RDD转换得到。
1、3调用SparkContext的parallelize,将Driver上的数据集并行化,形成分布式RDD。
val rdd = sc.parallelize(Array(1 to 10)) 根据执行器数量拆分
val rdd = sc.parallelize(Array(1 to 10), 5) 指定了partition的数量 (slice)
缺点:受制于Driver所在节点资源限制,数据规模较小。
1、4基于DB(Mysql),NoSQL(HBase)、S3、数据流创建。
2、转换处理:
2、1转换(Transformation) :
一个RDD经过计算后生成新的RDD,比如wordcount中的flatMap、map和ReduceByKey
2、2动作(Action):
返回结果到Driver程序中,这一般意味着RDD计算的结果,比如wordcount中的最后一步collect操作
3、输出:
处理完以后,数据可以被持久化或缓存,可以放到分布式文件系统,内存,或者数据数据库中。
实例:
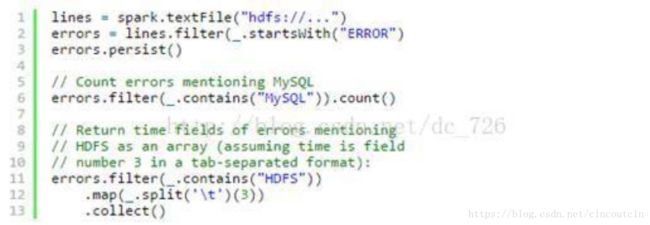
假设网站中的一个 WebService 出现错误,我们想要从数以 TB 的 HDFS 日志文件中找到问题的原因,此时我们就可以用 Spark 加载日志文件到一组结点组成集群的 RAM 中,并交互式地进行查询。以下是代码示例:
首先行 1 从 HDFS 文件中创建出一个 RDD ,而行 2 则衍生出一个经过某些条件过滤后的 RDD 。行 3 将这个 RDD errors 缓存到内存中,然而第一个 RDD lines 不会驻留在内存中。这样做很有必要,因为 errors 可能非常小,足以全部装进内存,而原始数据则会非常庞大。经过缓存后,现在就可以反复重用 errors 数据了。我们这里做了两个操作,第一个是统计 errors 中包含 MySQL 字样的总行数,第二个则是取出包含HDFS 字样的行的第三列时间,并保存成一个集合。
RDD的两种操作:
1、Transformation:
采用lazy模式:
从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
2、Action:
Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。

3、RDD操作实例:
单词计数:
val lines = sc.textFile("C://Users//CZC//README.md",1)
val words = lines.flatMap{line => line.split(" ")}
val pairs = words.map{word => (word,1)}
val wordCounts = pairs.reduceByKey(_+_)
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + " : " +wordNumberPair._2))
sc.stop()
RDD分区:
每个RDD包含:
1、一组RDD分区:(partition,即数据集的原子部分)。
2、对父RDD的一组依赖,这些依赖包含了RDD的Lineage(血统:即RDD之间的依赖关系)。
3、一个函数:即在父类上执行的何种计算。
4、元数据,描述分区模式和数据存放的位置。
RDD依赖关系:
窄依赖(Narrow Dependencies )
子RDD 的每个分区依赖于常数个父分区(即与数据规模无关)
输入输出一对一的算子,且结果RDD 的分区结构不变,主要是map 、flatMap
输入输出一对一,但结果RDD 的分区结构发生了变化,如union 、coalesce
从输入中选择部分元素的算子,如filter 、distinct 、subtract 、sample
宽依赖(Wide Dependencies )
子RDD 的每个分区依赖于所有父RDD 分区
对单个RDD 基于Key 进行重组和reduce,如groupByKey 、reduceByKey ;
对两个RDD 基于Key 进行join 和重组,如join

特性:
1、计算某个子RDD时:
窄依赖:一个父RDD计算完了就可以通过相应的计算(map等)得到相应的子RDD
款依赖:等到所有父RDD计算完了,并且Hash后传到相应节点之后才能计算子RDD
2、数据丢失时:
窄依赖:重算丢失的那块数据即可恢复。
宽依赖:重算祖先的所有数据块进行恢复。
RDD的容错支持:
1、Linage方式:根据血缘关系,在执行一次前面的处理。RDD它本身是一个不可变的数据集,自己能够记住构建它的操作图,无需备份,这种自我恢复的机制降低了跨网络数据传输的成本。
2、设置检查点:将数据持久化到存储中,适用于含宽依赖的长血统RDD。
7、Spark任务调度:
shuffle:
当一个RDD的一个分区依赖前一个RDD的所有分区时,例如,对于单词“Spark”出现次数汇总时,该单词可能出现在所有分区中,需要将所有分区中的Spark出现的键值对汇总到某一个数据节点进行处理。这个过程叫作shuffle
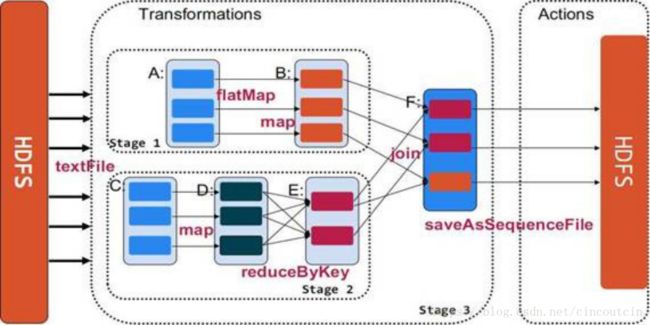
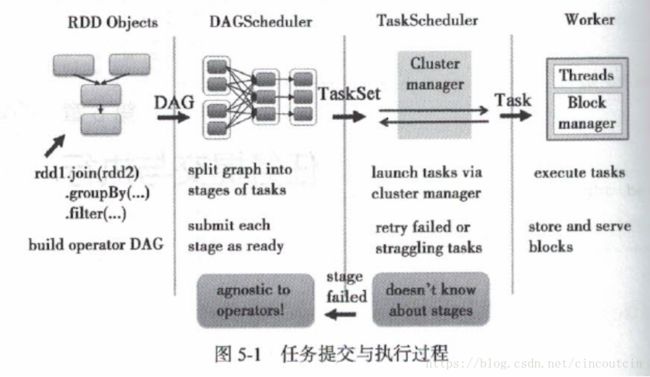
1、Action类型的算子触发job的执行。源码中调用了SparkContext的runJob()方法,跟进源码发现底层调用的是DAGScheduler的runJob()方法。
DAGScheduler会将我们的job按照宽窄依赖划分为一个个stage,每个stage中有一组并行计算的task,每一个task都可以看做是一个”pipeline”,,这个管道里面数据是一条一条被计算的,每经过一个RDD会经过一次处理,RDD是一个抽象的概念里面存储的是一些计算的逻辑,每一条数据计算完成之后会在shuffle write过程中将数据落地写入到我们的磁盘中。
2、stage划分完之后会以Tasket的形式提交给我们的TaskScheduler。
源码中TaskScheduler.submit.tasks(new TaskSet())只是一个调用方法的过程而已。我们口述说是发送到TaskScheduler。TaskScheduler接收到TaskSet之后会进行遍历,每遍历一条调用launchTask()方法,launchTask()根据数据本地化的算法发送task到指定的Executor中执行。task在发送到Executor之前首先进行序列化,Executor中有ThreadPool,ThreadPool中有很多线程,在这里面来具体执行我们的task。
3、TaskScheduler和Executor之间有通信(Executor有一个邮箱(消息循环体CoresExecutorGraintedBackend)),Executor接收到task
Executor接收到task后首先将task反序列化,反序列化后将这个task变为taskRunner(new taskRunner),并不是TaskScheduler直接向Executor发送了一个线程,这个线程是在Executor中变成的。然后这个线程就可以在Executor中的ThreadPool中执行了。
4、Executor接收到的task分为maptask 和 reducetask
map task 和 reduce task,比如这里有三个stage,先从stage1到stage2再到stage3,针对于stage2来说,stage1中的task就是map task ,stage2中的task就是reduce task,针对stage3来说...map task 是一个管道,管道的计算结果会在shuffle write阶段数据落地,数据落地会根据我们的分区策略写入到不同的磁盘小文件中,注意相同的key一定写入到相同的磁盘小文件中),map端执行完成之后,会向Driver中的DAGScheduler对象里面的MapOutputTracker发送了一个map task的执行状态(成功还是失败还有每一个小文件的地址)。然后reduce task开始执行,reduce端的输入数据就是map端的输出数据。那么如何拿到map端的输出数据呢?reduce task会先向Driver中MapOutPutTracker请求这一批磁盘小文件的地址,拿到地址后,由reduce task所在的Executor里面的BlockManager向Map task 所在的Executor先建立连接,连接是由ConnectionManager负责的,然后由BlockTransformService去拉取数据,拉取到的数据作为reduce task的输入数据(如果使用到了广播变量,reduce task 或者map task 它会先向它所在的Executor中的BlockManager要广播变量,没有的话,本地的BlockManager会去连接Driver中的BlockManagerMaster,连接完成之后由BlockTransformService将广播变量拉取过来)Executor中有了广播变量了,task就可以正常执行了。
8、Spark存储体系:
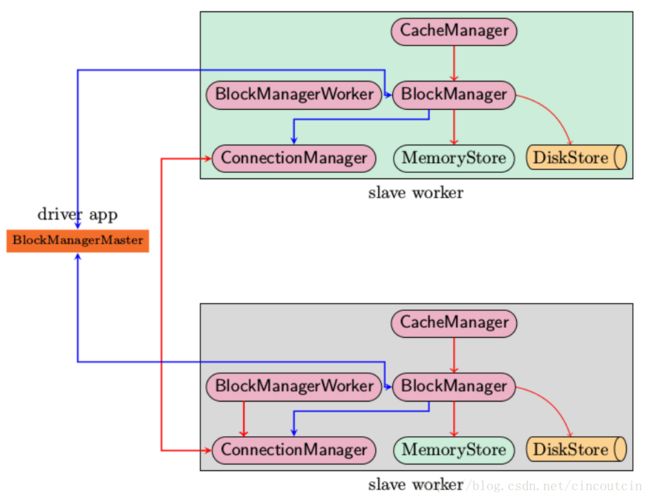
上图是Spark存储子系统中几个主要模块的关系示意图,现简要说明如下
CacheManager RDD在进行计算的时候,通过CacheManager来获取数据,并通过CacheManager来存储计算结果
BlockManager CacheManager在进行数据读取和存取的时候主要是依赖BlockManager接口来操作,BlockManager决定数据是从内存(MemoryStore)还是从磁盘(DiskStore)中获取
MemoryStore 负责将数据保存在内存或从内存读取
DiskStore 负责将数据写入磁盘或从磁盘读入
BlockManagerWorker 数据写入本地的MemoryStore或DiskStore是一个同步操作,为了容错还需要将数据复制到别的计算结点,以防止数据丢失的时候还能够恢复,数据复制的操作是异步完成,由BlockManagerWorker来处理这一部分事情
ConnectionManager 负责与其它计算结点建立连接,并负责数据的发送和接收
BlockManagerMaster 注意该模块只运行在Driver Application所在的Executor,功能是负责记录下所有BlockIds存储在哪个SlaveWorker上,比如RDD Task运行在机器A,所需要的BlockId为3,但在机器A上没有BlockId为3的数值,这个时候Slave worker需要通过BlockManager向BlockManagerMaster询问数据存储的位置,然后再通过ConnectionManager去获取.
8、1 BlockManager 在 spark 中扮演的角色
spark shuffle 的过程总用到了 BlockManager 作为数据的中转站
spark broadcast 调度 task 到多个 executor 的时候, broadCast 底层使用的数据存储层
如果我们对一个 rdd 进行了cache, cacheManager 也是把数据放在了 blockmanager 中, 截断了计算链依赖, 后续task 运行的时候可以直接从 cacheManager 中获取到 cacherdd ,不用再从头计算。
8、2 Block和partition的关系
RDD 的运算是基于 partition, 每个 task 代表一个 分区上一个 stage 内的运算闭包, task 被分别调度到 多个 executor上去运行。
首先根据RDD id和partition index构造出block id (rdd_xx_xx),接着从BlockManager中取出相应的block。
如果该block存在,表示此RDD在之前已经被计算过和存储在BlockManager中,因此取出即可,无需再重新计算。
如果该block不存在则需要调用RDD的computeOrReadCheckpoint()函数计算出新的block,并将其存储到BlockManager中。这样RDD的transformation、action就和block数据建立了联系,虽然抽象上我们的操作是在partition层面上进行的,但是partition最终还是被映射成为block,因此实际上我们的所有操作都是对block的处理和存取。
8、3 Spark cache 过程总结
rdd 计算的时候, 首先根据RDD id和partition index构造出block id (rdd_xx_xx), 接着从BlockManager中取出相应的block。
如果该block存在,表示此RDD在之前已经被计算过和存储在BlockManager中,因此取出即可,无需再重新计算。
如果 block 不存在我们可以 计算出来, 然后吧 block 通过 doPutIterator 函数存储在 节点上的 BlockManager上面,汇报block信息到 driver, 下次如果使用同一个 rdd, 就可以直接从分布式存储中 直接取出相应的 block。
8、4 BlockManager数据写入流程
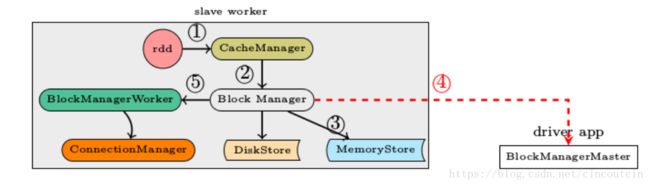
1、RDD.iterator是与storage子系统交互的入口
2、CacheManager.getOrCompute调用BlockManager的put接口来写入数据
3、数据优先写入到MemoryStore即内存,如果MemoryStore中的数据已满则将最近使用次数不频繁的数据写入到磁盘
4、通知BlockManagerMaster有新的数据写入,在BlockManagerMaster中保存元数据
5、将写入的数据与其它slave worker进行同步,一般来说在本机写入的数据,都会另先一台机器来进行数据的备份,即replicanumber=1
8、5 MemorySore 如何存储Block
MemoryStore内部维护了一个hashmap来管理所有的block,以block id为key将block存放到hashmap中
在MemoryStore中存放block必须确保内存足够容纳下该block,若内存不足则会将block写到文件中
8、6 DiskStore如何存取block
DiskStore可以配置多个folder,所有的block都会存储在所创建的folder里面。
每一个block都被存储为一个file,通过计算block id的hash值将block映射到文件中,根据block id计算出hash值,将hash取模获得dirId和subDirId,在subDirs中找出相应的subDir,若没有则新建一个subDir,最后以subDir为路径、block id为文件名创建file handler。
DiskStore使用此file handler将block写入文件内