hbase的基本操作
HBase是一个分布式的、面向列的开源数据库。HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。
Hbase的组成结构可用表形容:
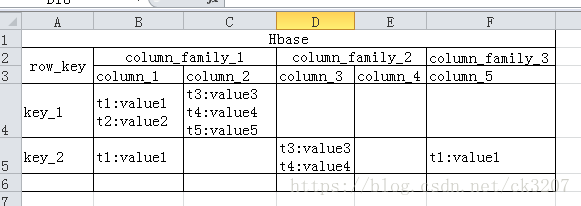
hbase是一张表:表中有一个唯一键是 row key, 每个row key 对应 N(N >= 1)个列族。每个列族由N个列组成(N>=1)。
创表
下面开始我们探索之旅。要实现如图的表,首先需创建一张hbase表,创表的规范为:
create 'table', 'column_family_1','column_family_2','column_family_3'...
hbase(main):032:0> create 'hbase_test','column_family_1', 'column_family_2', 'column_family_3'
0 row(s) in 1.2620 seconds
=> Hbase::Table - hbase_test
hbase(main):033:0> 创表的关键字是create,”hbase_test”是表名;”column_family_1”,”column_family_2”,”column_family_3”是三个不同的列族名。
删除表
相应的,删除表可用drop命令:
表创建成功后,默认状态是enable,即“使用中”的状态,删除表之前需先设置表为“关闭中”。
设置表为“使用中”:enable 'hbase_test'
设置表为“关闭中”:disable 'hbase_test'
disable 'hbase_test'
drop 'hbase_test'依次执行上述命令,可删除表成功。
查看所有表
可用list 命令查看当前创建的表:
hbase(main):026:0> list
TABLE
ai_ns:testtable
demo
dmp:hbase_tags
emp
fund1
hbase_tags
hbase_test
hbase_weitest
jemp
scores
test1
11 row(s) in 0.1130 seconds查看表结构
可使用describe命令查看表结构,其规范为:
describe 'table'
hbase(main):033:0> describe 'hbase_test'
Table hbase_test is ENABLED
hbase_test
COLUMN FAMILIES DESCRIPTION
{NAME => 'column_family_1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE',
MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'column_family_2', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE',
MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'column_family_3', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE',
MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
3 row(s) in 0.0290 seconds插入与更新数据
如何插入数据呢?较为普遍的方法是put命令,其命令规范为:
put 'table', 'row key', 'column_family:column', 'value'
hbase(main):007:0> put 'hbase_test','key_1','column_family_1:column_1','value1'
0 row(s) in 0.1710 seconds
hbase(main):008:0> put 'hbase_test','key_1','column_family_1:column_2','value2'
0 row(s) in 0.0150 seconds查看创表过程,相比也知道”hbase_test”是表名;’001’ 是row key;’column_family_1:column_1’ 是列族以及列族对应的列,中间用”:”分隔;’value1’ 是”colum_1”这个列的值。表格的其他数据,可以用此方法全部插入:
put 'hbase_test','key_2','column_family_1:column_1','value4'
put 'hbase_test','key_2','column_family_1:column_2','value5'
put 'hbase_test','key_3','column_family_1:column_2','value5'
put 'hbase_test','key_4','column_family_1:column_1','value1'
put 'hbase_test','key_4','column_family_2:column_3','value3'
put 'hbase_test','key_4','column_family_3:','value1'
put 'hbase_test','key_4','column_family_3:','value1'
put 'hbase_test','key_5','column_family_1:column_1','value1'
put 'hbase_test','key_5','column_family_2:column_3','value4'
put 'hbase_test','key_5','column_family_3:','value2'
put方法可以插入新数据,同样也运用于更新,使用方法与上述一致。
当然,put方法类似的还有很多,但大同小异,可以使用help "put"命令查看:
hbase(main):046:0> help "put"
Put a cell 'value' at specified table/row/column and optionally
timestamp coordinates. To put a cell value into table 'ns1:t1' or 't1'
at row 'r1' under column 'c1' marked with the time 'ts1', do:
hbase> put 'ns1:t1', 'r1', 'c1', 'value'
hbase> put 't1', 'r1', 'c1', 'value'
hbase> put 't1', 'r1', 'c1', 'value', ts1
hbase> put 't1', 'r1', 'c1', 'value', {ATTRIBUTES=>{'mykey'=>'myvalue'}}
hbase> put 't1', 'r1', 'c1', 'value', ts1, {ATTRIBUTES=>{'mykey'=>'myvalue'}}
hbase> put 't1', 'r1', 'c1', 'value', ts1, {VISIBILITY=>'PRIVATE|SECRET'}
The same commands also can be run on a table reference. Suppose you had a reference
t to table 't1', the corresponding command would be:
hbase> t.put 'r1', 'c1', 'value', ts1, {ATTRIBUTES=>{'mykey'=>'myvalue'}}读取数据(get)
以上这样的插入数据方式,很容易联想到获取数据是否也是类似格式呢?
没错,获取数据get 命令与之相似:
hbase(main):020:0> get 'hbase_test','key_1'
COLUMN CELL
column_family_1:column_1 timestamp=1534259899359, value=value1
column_family_1:column_2 timestamp=1534259904389, value=value2
2 row(s) in 0.0220 seconds同样的,类似的get方法还有别的,用help "get"命令查看:
hbase(main):047:0> help "get"
Get row or cell contents; pass table name, row, and optionally
a dictionary of column(s), timestamp, timerange and versions. Examples:
hbase> get 'ns1:t1', 'r1'
hbase> get 't1', 'r1'
hbase> get 't1', 'r1', {TIMERANGE => [ts1, ts2]}
hbase> get 't1', 'r1', {COLUMN => 'c1'}
hbase> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2], VERSIONS => 4}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1, VERSIONS => 4}
hbase> get 't1', 'r1', {FILTER => "ValueFilter(=, 'binary:abc')"}
hbase> get 't1', 'r1', 'c1'
hbase> get 't1', 'r1', 'c1', 'c2'
hbase> get 't1', 'r1', ['c1', 'c2']
hbase> get 't1', 'r1', {COLUMN => 'c1', ATTRIBUTES => {'mykey'=>'myvalue'}}
hbase> get 't1', 'r1', {COLUMN => 'c1', AUTHORIZATIONS => ['PRIVATE','SECRET']}
hbase> get 't1', 'r1', {CONSISTENCY => 'TIMELINE'}
hbase> get 't1', 'r1', {CONSISTENCY => 'TIMELINE', REGION_REPLICA_ID => 1}读取数据(scan)
使用get命令虽然方便,但是终究只是某一个row key下的数据,若需要查看所有数据,明显不能满足我们工作需求。别急,还可以使用scan命令查看数据:
hbase(main):021:0> scan 'hbase_test'
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
key_1 column=column_family_1:column_2, timestamp=1534259904389, value=value2
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_2 column=column_family_1:column_2, timestamp=1534259913358, value=value5
key_3 column=column_family_1:column_2, timestamp=1534259917322, value=value5
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_4 column=column_family_2:column_3, timestamp=1534259928680, value=value3
key_4 column=column_family_3:, timestamp=1534259936240, value=value1
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
key_5 column=column_family_2:column_3, timestamp=1534259943330, value=value4
key_5 column=column_family_3:, timestamp=1534259947358, value=value2
5 row(s) in 0.0420 seconds以上为获取某张表的所有数据,若只需取’column_family_1’列族下的数据,则:
hbase(main):002:0> scan 'hbase_test',{COLUMN => 'column_family_1'}
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
key_1 column=column_family_1:column_2, timestamp=1534259904389, value=value2
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_2 column=column_family_1:column_2, timestamp=1534259913358, value=value5
key_3 column=column_family_1:column_2, timestamp=1534259917322, value=value5
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
5 row(s) in 0.0330 seconds上述表达式 等同于 scan 'hbase_test',{COLUMN => ['column_family_1']}
若需取’column_family_1’,’column_family_2’多列列族数据:
hbase(main):004:0> scan 'hbase_test',{COLUMN => ['column_family_1', 'column_family_2']}
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
key_1 column=column_family_1:column_2, timestamp=1534259904389, value=value2
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_2 column=column_family_1:column_2, timestamp=1534259913358, value=value5
key_3 column=column_family_1:column_2, timestamp=1534259917322, value=value5
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_4 column=column_family_2:column_3, timestamp=1534259928680, value=value3
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
key_5 column=column_family_2:column_3, timestamp=1534259943330, value=value4
5 row(s) in 0.0270 seconds再细致一点,你可能会有获取’column_family_1’列族下,’column_1’列的数据:
hbase(main):005:0> scan 'hbase_test',{COLUMN => ['column_family_1:column_1']}
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
4 row(s) in 0.0190 seconds同样的,多列数据可以这样获取:
hbase(main):006:0> scan 'hbase_test',{COLUMN => ['column_family_1:column_1','column_family_2:column_3']}
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_4 column=column_family_2:column_3, timestamp=1534259928680, value=value3
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
key_5 column=column_family_2:column_3, timestamp=1534259943330, value=value4
4 row(s) in 0.0390 seconds若要获取row key 大于等于某key的情况:
hbase(main):007:0> scan 'hbase_test',{COLUMN => ['column_family_1:column_1','column_family_2:column_3'], STARTROW => 'key_2'}
ROW COLUMN+CELL
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_4 column=column_family_2:column_3, timestamp=1534259928680, value=value3
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
key_5 column=column_family_2:column_3, timestamp=1534259943330, value=value4
3 row(s) in 0.0210 seconds同样,获取row key 小于某key的情况:
hbase(main):008:0> scan 'hbase_test',{COLUMN => ['column_family_1:column_1','column_family_2:column_3'], STOPROW => 'key_2'}
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
1 row(s) in 0.0330 seconds大于等于key_2,小于key_5:
hbase(main):009:0> scan 'hbase_test',{COLUMN => ['column_family_1:column_1','column_family_2:column_3'], STARTROW => 'key_2', STOPROW => 'key_5'}
ROW COLUMN+CELL
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_4 column=column_family_2:column_3, timestamp=1534259928680, value=value3
2 row(s) in 0.0180 seconds上述要注意关键字STARTROW与STOPROW稍有区别,STARTROW后的row key 是包含在内,而STOPROW后的row key 则是不包含的关系,相当于“左闭右开”的关系。
使用scan 命令扫描一张表的数据时,我们常常会限制下输出row key条数:
hbase(main):013:0> scan 'hbase_test', {LIMIT => 2}
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534259899359, value=value1
key_1 column=column_family_1:column_2, timestamp=1534259904389, value=value2
key_2 column=column_family_1:column_1, timestamp=1534259909024, value=value4
key_2 column=column_family_1:column_2, timestamp=1534259913358, value=value5
2 row(s) in 0.0190 seconds看到上述输出你可能会懵,明明是 “LIMIT => 2” 为什么会返回四条数据,前面说了,row key 是唯一主键,这个限制的数量是针对主键row key的。
若想以反序获取两行数据:
hbase(main):016:0> scan 'hbase_test', {LIMIT => 2, REVERSED => true}
ROW COLUMN+CELL
key_5 column=column_family_1:column_1, timestamp=1534259939697, value=value1
key_5 column=column_family_2:column_3, timestamp=1534259943330, value=value4
key_5 column=column_family_3:, timestamp=1534259947358, value=value2
key_4 column=column_family_1:column_1, timestamp=1534259924209, value=value1
key_4 column=column_family_2:column_3, timestamp=1534259928680, value=value3
key_4 column=column_family_3:, timestamp=1534259936240, value=value1
2 row(s) in 0.0390 seconds不要疑惑为什么不是与scan 'hbase_test', {LIMIT => 2}数据的输出内容不一致。默认情况下REVERSED => false,当设置REVERSED => true时,数据反向读取2行,自然与之前不一致。可以理解为mysql中select * from dual asc limit 2与select * from dual desc limit 2这样的区别。
scan的更多使用方法可用help 'scan'查看:
hbase(main):025:0> help 'scan'
Scan a table; pass table name and optionally a dictionary of scanner
specifications. Scanner specifications may include one or more of:
TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, ROWPREFIXFILTER, TIMESTAMP,
MAXLENGTH or COLUMNS, CACHE or RAW, VERSIONS, ALL_METRICS or METRICS
If no columns are specified, all columns will be scanned.
To scan all members of a column family, leave the qualifier empty as in
'col_family'.
The filter can be specified in two ways:
1. Using a filterString - more information on this is available in the
Filter Language document attached to the HBASE-4176 JIRA
2. Using the entire package name of the filter.
If you wish to see metrics regarding the execution of the scan, the
ALL_METRICS boolean should be set to true. Alternatively, if you would
prefer to see only a subset of the metrics, the METRICS array can be
defined to include the names of only the metrics you care about.
Some examples:
hbase> scan 'hbase:meta'
hbase> scan 'hbase:meta', {COLUMNS => 'info:regioninfo'}
hbase> scan 'ns1:t1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1303668804, 1303668904]}
hbase> scan 't1', {REVERSED => true}
hbase> scan 't1', {ALL_METRICS => true}
hbase> scan 't1', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']}
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => "
(QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"}
hbase> scan 't1', {FILTER =>
org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}删除数据(delete)
难免有数据插入不当的情况,可用delete命令删除:
hbase(main):027:0> put 'hbase_test','key_6','column_family_3:','value6'
0 row(s) in 0.1020 seconds
hbase(main):028:0> get 'hbase_test','key_6','column_family_3:'
COLUMN CELL
column_family_3: timestamp=1534305060905, value=value6
1 row(s) in 0.0190 seconds
hbase(main):029:0> delete 'hbase_test','key_6','column_family_3:'
0 row(s) in 0.0520 seconds
hbase(main):030:0> get 'hbase_test','key_6','column_family_3:'
COLUMN CELL
0 row(s) in 0.0110 seconds删除数据(deleteall)
delete这个方法只能删除具体到哪一行中的某个列族下的某一列数据,想要删除一整行数据,需用deleteall命令:
hbase(main):041:0> put 'hbase_test','key_7','column_family_3:','value7'
0 row(s) in 0.0150 seconds
hbase(main):042:0> put 'hbase_test','key_7','column_family_2:column_3','value9'
0 row(s) in 0.0130 seconds
hbase(main):043:0> get 'hbase_test','key_7'
COLUMN CELL
column_family_2:column_3 timestamp=1534305920535, value=value9
column_family_3: timestamp=1534305915794, value=value7
2 row(s) in 0.0110 seconds
hbase(main):044:0> deleteall 'hbase_test','key_7'
0 row(s) in 0.0110 seconds
hbase(main):045:0> get 'hbase_test','key_7'
COLUMN CELL
0 row(s) in 0.0090 seconds若需删除整张表的数据,可用truncate命令:
hbase(main):050:0> truncate 'hbase_test'
Truncating 'hbase_test' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 3.4050 seconds
hbase(main):051:0> scan 'hbase_test'
ROW COLUMN+CELL
0 row(s) in 0.3380 seconds执行脚本
hbase 与 hive一样,都是可以直接执行脚本的。比如之前的put 命令,一个个填写复制粘贴写数据很麻烦,我可以全部put 命令放在一个文件中:
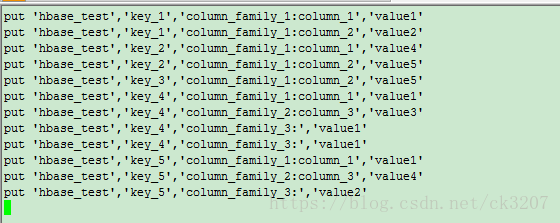
如上,执行完毕后,查看命令是否已正确执行,插入数据:
hbase(main):052:0> scan 'hbase_test'
ROW COLUMN+CELL
key_1 column=column_family_1:column_1, timestamp=1534306889023, value=value1
key_1 column=column_family_1:column_2, timestamp=1534306889072, value=value2
key_2 column=column_family_1:column_1, timestamp=1534306889078, value=value4
key_2 column=column_family_1:column_2, timestamp=1534306889083, value=value5
key_3 column=column_family_1:column_2, timestamp=1534306889093, value=value5
key_4 column=column_family_1:column_1, timestamp=1534306889099, value=value1
key_4 column=column_family_2:column_3, timestamp=1534306889104, value=value3
key_4 column=column_family_3:, timestamp=1534306889116, value=value1
key_5 column=column_family_1:column_1, timestamp=1534306889122, value=value1
key_5 column=column_family_2:column_3, timestamp=1534306889128, value=value4
key_5 column=column_family_3:, timestamp=1534306889144, value=value2
5 row(s) in 0.0270 seconds没有问题,非常完美。