pytorch 遇到的问题集锦
1,numpy 在数据扩增的时做了flip或mirror等操作(::-1),运行出现
![]()
解决方案:
np.ascontiguousarray(input)或 input.copy()即可。
原因是c++中对Numpy做的这种操作在pytorch中并未支持。
2,基于cv2的轮廓填充,去除最小面积,外接矩形操作方式:
https://blog.csdn.net/u014365862/article/details/77720368
3, 预训练pytorch模型采用了SGD优化算法,并保存了模型参数,微调先加载了预训练的模型,并改变了优化为“Adam”,训练第一步就出现了错误keyError:'betas',,,发现问题出在optim中的adam算法中,后发现正是因为改变优化方式引起了问题,将优化方式改回或者不加载预训练模型即可。(ps:感觉是pytorch内部有些问题,所以保存模型要保存优化方式,加载的时候要一起加载)

4,pytorch从3升级到4.1的时候,模型加载时出现:KeyError: "Unable to open object (object 'group1.bn1.num_batches_tracked' doesn't exist)"
模型加载中加: if 'batches_tracked' not in k:
h5f = h5py.File(filename, mode='r')
for k, v in model.state_dict().items():
if 'batches_tracked' not in k:
param = torch.from_numpy(np.asarray(h5f[k]))
v.copy_(param)
5,RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.DoubleTensor) should be the same:
网上查找该问题的答案,大多就是将模型放进cuda中,但本人遇到时模型已经正确放在GPU中,最后发现自己额外添加的模块self.sebs是由多个nn.Sequential组成的list, 在参数初始化的时候未进入cuda,通过self.sebs = nn.ModuleList(self.sebs)定义转化之后,问题就解决了。
6,pytorch 0.3与0.4.1版本中requires_grad和volatile:
pytorch 0.3:默认tensor转化为variable之后的requires_grad和volatile均为False,tensor无volatile属性。
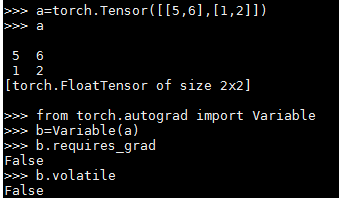
所以inference时需要将variable的volatile设为True,减少内存占用,训练时则可以直接求梯度。
pytorch 0.4:取消了volatile特性,将variable和tensor合并,默认tensor是requires_grad=False,而输入网络模型之后(第一层即可),该tensor即变成requires_grad=True,所以train时直接dataloader即可,而inference需要在y=model(x)之前加上
with torch.no_grad():7,错误:ValueError: Expected more than 1 value per channel when training, got input size [1, 256, 1, 1],出错在pytorch中的BN层,解决方案是DataLoader中drop_last设置为True(训练和验证)。有人给出的解释是“可能是输入批次只有一个数据点,而由于BatchNorm操作需要多于一个数据计算平均值,因此造成该错误”。但实际训练中保证了这种条件,但验证没有满足这种条件,运行也是没有问题的,最初出错在训练epoch的末尾,之后待解决。