机器学习笔记(一)——总体介绍
文章目录
- 一、机器学习和深度学习和统计学习
- 1、机器学习
- 二、一些数学知识
- 1、导数
- 2、方向导数
- 3、梯度
- 4、条件概率
- 三、松散知识点
- 1、数值的归一化
- 2、命名实体识别NER(Named Entity Recognition)
- 3、词袋模型
- 4、python numpy的一些例子
- 4.1画所有样本点中,只在单位圆中的样本点,并且挖去“洞”中的点
- 4.2 画$f(x)=x^x$图象的代码
- 5、标称型数据和数值型数据
- 6、分类问题和回归问题
- 7、batch、epoch、iteration的含义
- 8、卷积核
一、机器学习和深度学习和统计学习
参考链接:
机器学习与深度学习有什么区别?
数据挖掘,机器学习,统计学习的区别与联系
包含关系如下图:
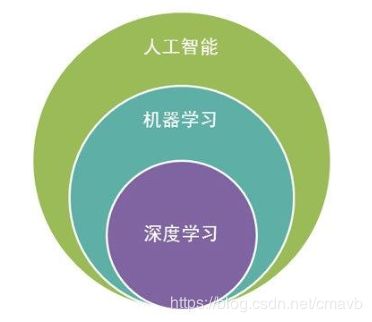
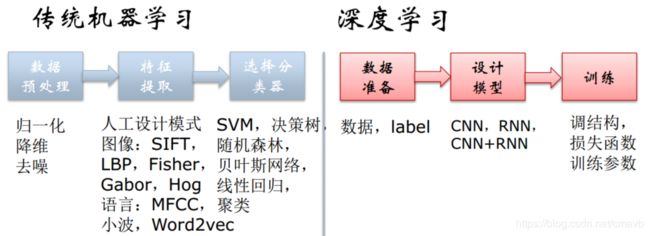
数据库提供数据管理技术,机器学习和统计学提供数据分析技术
。由于统计学界往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域。但能否认为数据挖掘只不过就是机器学习的简单应用呢?答案是否定的。一个重要的区别是,传统的机器学习研究并不把海量数据作为处理对象,很多技术是为处理中小规模数据设计的,如果直接把这些技术用于海量数据,效果可能很差,甚至可能用不起来。因此,数据挖掘界必须对这些技术进行专门的、不简单的改造。例如,决策树是一种很好的机器学习技术,不仅有很强的泛化能力,而且学得结果具有一定的可理解性,很适合数据挖掘任务的需求。但传统的决策树算法需要把所有的数据都读到内存中,在面对海量数据时这显然是无法实现的。为了使决策树能够处理海量数据,数据挖掘界做了很多工作,例如通过引入高效的数据结构和数据调度策略等来改造决策树学习过程,而这其实正是在利用数据库界所擅长的数据管理技术。实际上,在传统机器学习算法的研究中,在很多问题上如果能找到多项式时间的算法可能就已经很好了,但在面对海量数据时,可能连算法都是难以接受的,这就给算法的设计带来了巨大的挑战。
总结:
1)统计学习:是其它两门技术的基础,更偏重于理论上的完善;
2)机器学习:是统计学习对实践技术的延伸,更偏重于解决小数据量的问题提供算法技术支撑;
3)数据挖掘:更偏重于大数据的实际问题,更注重实际问题的解决,包括真实数据的数据清洗,建模,预测,等操作。
1、机器学习
机器学习是人工智能的一个分支。我们设计一个系统,使它根据训练数据来按照一定的方式学习。随着训练次数的增加,使得性能上不断学习和改进。通过参数优化的学习模型,能够用于预测相关问题的输出。分为
-
有监督学习
有可能是“半监督” -
无监督学习
-
增强学习
走路、踢球
不能解决大数据存储、并行计算、做一个机器人。
python中常用的包
- Numpy
- Pandas: DataFrame/Series(Excel/csv/tsv)
- scipy
- matplotlib
- scikit-learn: 用于ML
- tensorflow(Keras封装了tensorflow):用于DL, 同类的还有pytorch等。
二、一些数学知识
1、导数
导数就是曲线的斜率,是曲线变化快慢的反应。
二阶导数是斜率变化快慢的反应,表征曲线的凹凸性。
(非重点)例如求解 f ( x ) = x x f(x)=x^x f(x)=xx的最小值:
最后的 t 就是最小值

画 f ( x ) = x x f(x)=x^x f(x)=xx图象的代码
import math
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 3, 10000) # 用此来创建等差数列,
y = x**x
plt.plot(x, y, 'r-', linewidth=3, markersize=1)
# ‘r-’代表红色实线,markersize代表点的大小,linewidth表示线宽
plt.show()
2、方向导数
待补全
3、梯度
待补全
4、条件概率
设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率为:
P(A|B)=P(AB)/P(B)
分析:一般说到条件概率这一概念的时候,事件A和事件B都是同一实验下的不同的结果集合,事件A和事件B一般是有交集的,若没有交集(互斥),则条件概率为0,例如:
① 扔骰子,扔出的点数介于[1,3]称为事件A,扔出的点数介于[2,5]称为事件B,问:B已经发生的条件下,A发生的概率是多少?
也即,做一次实验时,即有可能仅发生A,也有可能仅发生B,也有可能AB同时发生,
② 同时扔3个骰子,“三个数都不一样”称为事件A,“其中有一个点数为1”称为事件B。这一题目中,AB也是有交集的。

用图更能容易的说明上述问题,我们进行某一实验,某一实验所有的可能的样本的结合为Ω(也即穷举实验的所有样本),圆圈A代表事件A所能囊括的所有样本,圆圈B代表事件B所能囊括的所有样本。
由图再来理解一下这个问题:“B已经发生的条件下,A发生的概率”,这句话中,“B已经发生”就相当于已经把样本的可选范围限制在了圆圈B中,其实就等价于这句话:“在圆圈B中,A发生的概率”,显然P(A|B)就等于AB交集中样本的数目/B的样本数目。为什么这里用的是样本的数目相除,而上面的公式却是用的概率相除,原因很简单,用样本数目相除时,把分子分母同除以总样本数,这就变成了概率相除。
三、松散知识点
1、数值的归一化
例如使用欧氏距离时,某一项特征产生的影响可能会远远大于其他特征的影响,但理论上它们应该具有同等重要的地位。例如“每年的飞行公里数”的计算得到结果远大于“每日游戏时长”。
此时可以采用“归一化”操作,把数变为(0,1)之间的小数:
newValue = (oldValue - min) / (max - min)
或者 其他方式也可以
2、命名实体识别NER(Named Entity Recognition)
参考链接:NLP入门(四)命名实体识别(NER)
NER是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具。一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
3、词袋模型
参考链接:NLP系列之词袋模型和TFIDF模型
词集模型:
单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个。
词袋模型基于词集模型:
如果一个单词在文档中出现不止一次,统计其出现的次数(频数)。
两者本质上的区别:词袋是在词集的基础上增加了频率的维度,词集只关注有和没有,词袋还要关注有几个。
假设我们要对一篇文章进行特征化,最常见的方式就是词袋。
4、python numpy的一些例子
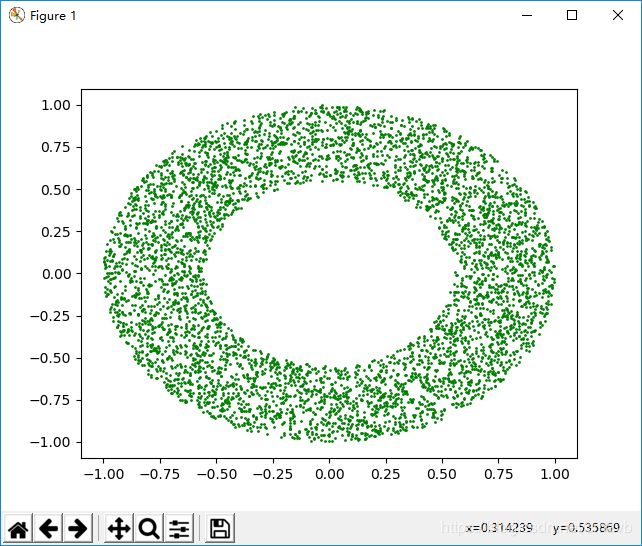
4.1画所有样本点中,只在单位圆中的样本点,并且挖去“洞”中的点
import math
import numpy as np
import matplotlib.pyplot as plt
data = 2 * np.random.rand(10000, 2) - 1 #
x = data[:, 0]
y = data[:, 1]
index_all = x**2 + y**2 <= 1
index_hole = x**2 + y**2 <= 0.3
index = np.logical_and(index_all, ~index_hole)
# 求 与 的集合,在index_all 但是 不在index_hole
plt.plot(x[index], y[index], 'go', markersize=1)
plt.show()
4.2 画 f ( x ) = x x f(x)=x^x f(x)=xx图象的代码
import math
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 3, 10000) # 用此来创建等差数列,
# **linspace()**通过指定开始值、终值和元素个数创建表示等差数列的一维数组
#可以通过endpoint参数指定是否包含终值,默认值为True,即包含终值。
#**arange()**类似于内置函数range()
#通过指定开始值、终值和步长创建表示等差数列的一维数组
#注意得到的结果数组不包含终值。
y = x**x
plt.plot(x, y, 'r-', linewidth=3, markersize=1)
# ‘r-’代表红色实线,markersize代表点的大小,linewidth表示线宽
plt.show()
5、标称型数据和数值型数据
**标称型:**一般在有限的数据中取,而且只存在‘是’和‘否’两种不同的结果(一般用于分类)
**数值型:**可以在无限的数据中取,而且数值比较具体化,例如4.02,6.23这种值(一般用于回归分析)
6、分类问题和回归问题
其实分类和回归的本质是一样的,都是对输入做出预测,其区别在于输出的类型。
分类问题:分类问题的输出是离散型变量(如: +1、-1),是一种定性输出。(预测明天天气是阴、晴还是雨)
回归问题:回归问题的输出是连续型变量,是一种定量输出。(预测明天的温度是多少度)。
7、batch、epoch、iteration的含义
参考:
batch、epoch、iteration的含义
(1)batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次。
比如训练集有500个样本,batchsize = 10 ,那么训练完整个样本集:iteration=50,epoch=1.
8、卷积核
图像处理的基本算子。
参考链接:
什么是卷积