MapReduce
MapReduce是一种并行编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。
Map和Reduce函数
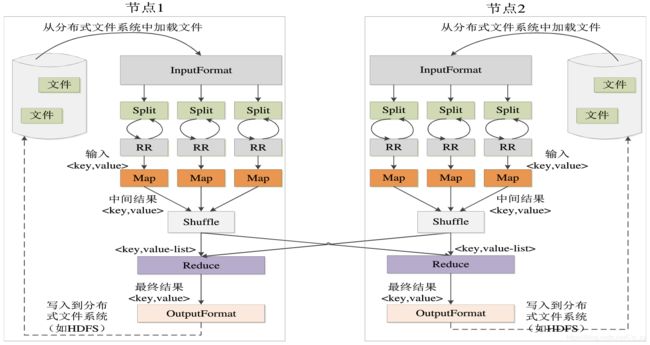
在MapReduce中,一个存储在分布式文件系统中的大规模数据集会被切分成许多独立的小数据块,这些小数据块可以被多个Map任务并行理。MapReduce框架会为每个Map任务输入一个数据子集,Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后结果,并写入分布式文件系统。
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| Map | <行号,“a,b,c”> |
<“a”,1> <“b”,1> <“c”,1> |
1.将数据集进一步解析成一批 2.每一个输入的 |
| Reduce | 输入的中间结果 |
拿Reduce举个例子
MapReduce体系结构
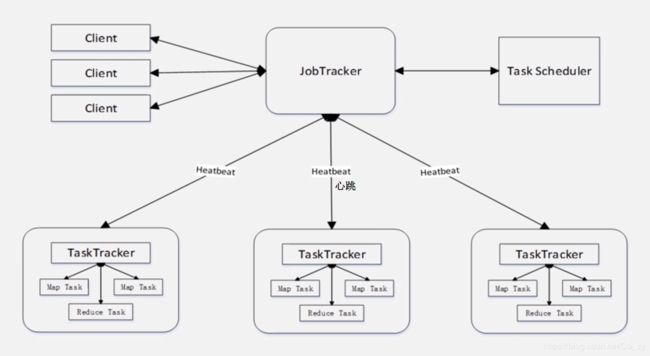
(1)Client
1.通过Client可以提交用户编写的应用程序用户通过他将应用程序交到JobTracker端
2.通过这些Client用户也可以通过它提供的一些接口去查看当前提交作业的运行状态
(2)JobTracker:
1.负责资源的监控和作业的调度
2.监控底层的其它的TaskTracker以及当前运行的Job的健康状况
3.一旦探测到失败的情况就把这个任务转移到其它节点继续执行,跟踪任务执行进度和资源使用量
(3)TaskScheduler
JobTracker会把任务执行进度和资源使用量这些信息传给TaskScheduler,TaskScheduler负责具体任务调度,它要解决应该把哪个任务分发给哪个TaskTracker去执行
(4)TaskTracker
1.执行具体的相关任务一般 接收JobTracker发送过来的命令
2.把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式,也就是heartbeat发送给JobTracker(见上图)
3.TaskTracker是以什么方式来衡量资源使用情况的?TaskTracker使用一个槽(slot)的概念,它会把机器上面所有的CPU、内存资源进行打包,然后把资源等分成许多个slot,slot又分为map类型的slot,reduce类型的slot,两者不通用.(Hadoop2.0修改了这个缺陷)
(5)map task和reduce task可以同时运行
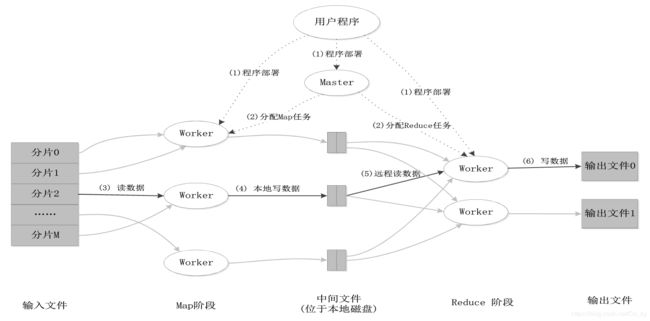
MapReduce工作流程
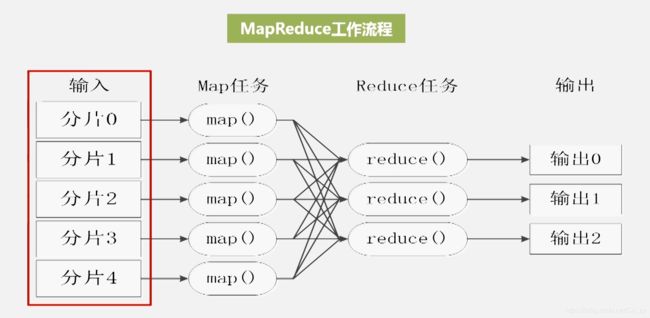
分片大小取决于HDFS块的大小,有多少个分片就有多少个map任务,而reduce任务的个数取决于reduce任务slot的个数.
下图展示了MapReduce工作流程中各个执行阶段
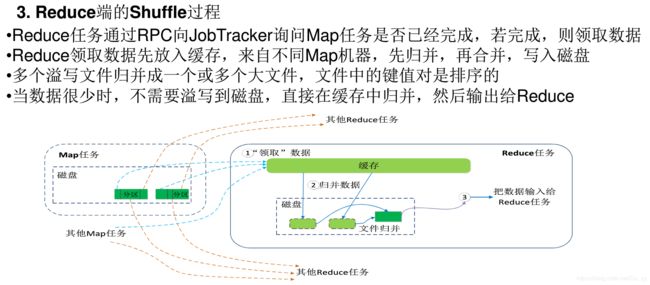
Shuffle过程
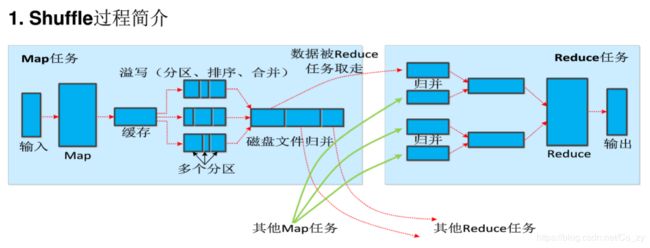
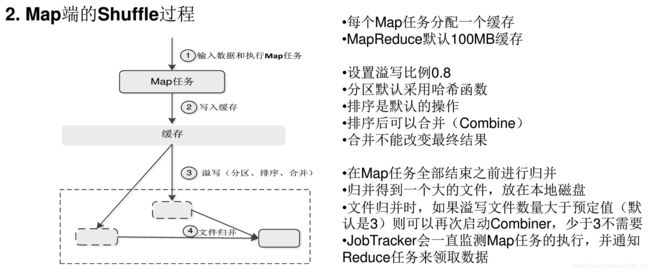
合并(Combine)和归并(Merge)的区别:
键值对<"a",1>和<"a",1>如果合并,会得到<"a",2>,如果归并,会得到<"a",<1,1>>
MapReduce应用执行过程
在Hadoop中执行MapReduce任务的几种方式
(1)hadoop jar 编写一个文件,打包成jar包去运行
(2)Pig Pig Latin语言提供类似SQL语句的功能
(3)Hive 类似SQL的语句,称为HiveQL,被Hive框架自动转化成MapReduce程序
(4)Python
(5)Shell脚本
哪种方式效率高,就用哪种.