Linux正则表达式
正则表达式
简单的说,正则表达式就是为处理大量的字符串而定义的一套规则和方法,通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。linux正则表达式一般以行为单位匹配处理的。字符集LC_ALL=C。
容易混淆的两个注意事项:
- 正则表达式应用非常广泛,存在于各种语言中,例如php,python,java等。但是以下所讨论的都是linux系统运维工作中的正则表达式,即linux正则表达式,最常应用正则表达式的命令就是grep,sed,awk。
- 正则表达式与通配符特殊字符是有本质区别的。ls *.log,这里的*是通配符表示所有。正则表达式中*是重复前面的一个字符0次或多次。
正则表达式(Regular Expressions)实际就是一些特殊字符,赋予了它特定的含义。
正则表达式元字符由以下字符组成:
^ $ . [ ] { } - ? * + ( ) | \
基础的正则表达式BRE
实战测试数据:
[root@ianLinux ~]# cat oldboy.log
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball abd chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god,i am not oldbey,but OLDBOY!
oldb y[root@ianLinux ~]# export LC_ALL=C #注意字符集(1)“^word” 以word开头的。
(2)“word$”以word结尾的。
(3)“^$” 表示空行。

![]()
过滤空行。oldboy.log里面就有两行空行。

把空行去掉。

(4)“.”代表且只能代表任意一个字符。
(5)“\” 转义字符,例如.只代表点本身,让有着特殊身份意义的字符还原本身意义。
(6)“*” 重复0个或多个前面的一个字符。
(7)“.*” 匹配所有字符。延伸^.*以任意多个字符开头。.*$以任意多个字符结尾。
grep "." oldboy.log

grep "oldb.y" oldboy.log

grep ".*" oldboy.log

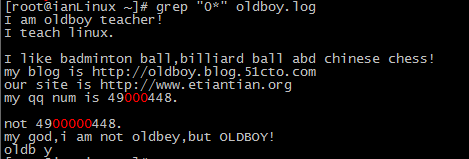
grep "0*" oldboy.log
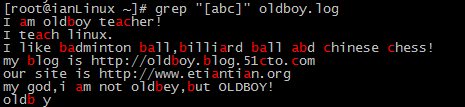
(8)[abc] 匹配字符集合内的任意一个字符[a-z]、[A-Z]、[0-9]。
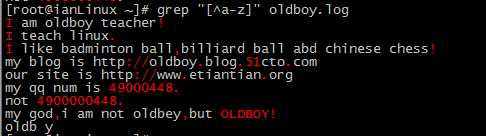
(9)[^abc] 匹配不包含^后的任意字符的内容。中括号里的^为取反。
(10)
\{n,m\} 重复n到m次,前一个重复的字符。如果用egrep/sed -r可以去掉斜线。
\ {n,\} 重复至少n次,前一个重复的字符。如果用egrep/sed -r可以去掉斜线。
\{n\} 重复n次,前一个重复的字符。如果用egrep/sed -r可以去掉斜线。
egrep,grep -E或sed -r过滤一般特殊字符可以不转义。
grep "[abc]" oldboy.log
grep "[0-9]" oldboy.log

grep "[^a-z]" oldboy.log
grep -E "0{3,5}" oldboy.log
![]()
grep -E "0{3,}" oldboy.log
![]()
grep "0\{3\}" oldboy.log与grep -E "0{3}" oldboy.log

扩展的正则表达式ERE
(egrep或grep -E)
新的测试数据:
[root@ianLinux ~]# vi oldboy.log
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball abd chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god,i am not oldbey,but OLDBOY!
oldb y
good
goood
gd(1) + 重复一个或多个前面的字符(与*区别)
(2) ? 重复0次或1次前面的字符
(3) | 用或的方式查找多个符号的字符串
grep -E "go+d" oldboy.log与grep -E "go*d" oldboy.log

grep -E "go?d" oldboy.log
![]()
grep -E "god|good" oldboy.log
![]()