关于Redis - 哨兵模式
单纯的主从模式还是会存在问题,一旦主机宕机,这个主从就没有办法维持下去。同时,从机也会不能正常工作(这里的正常工作指的主从的运作体系)。
Redis 2.8中新提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
目录
一、简单说说哨兵:
二、哨兵的配置:
三、启动方式:
四、关于哨兵的一些基本命令
五、关于哨兵选举:
一、简单说说哨兵:
其实在配置文件内就可以看到:
① 主机无法正常工作的情况下选择副本以升级为 master(主机)
② 监控主从数据库是否正常运行
③ 哨兵配置的时,哨兵之间其实也会相互监控(基于第一点)
二、哨兵的配置:
其实官方文档也存在:https://redis.io/topics/sentinel
从源码/自己编译好的代码中获取:
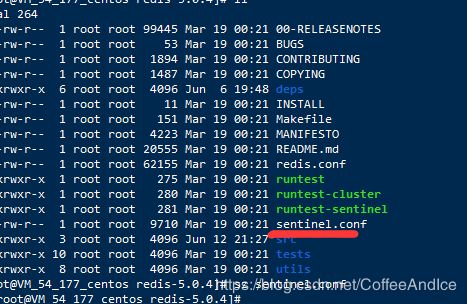
这里设置三个哨兵,以达成后面的需求:
端口号:26379、26380、26381
Tip:为什么我会用两个以上哨兵
基本修改操作:
daemonize yes
# 守护线程 这里便于后台运行
pidfile /var/run/redis-26379_sentinel.pid
# 文件名自定义,文件存放位置也是自定义
logfile "./logs/sentinel_26379.log"
# 该项可不设置,默认输出到/dev/null,若没文件夹需先建立,与之前主从时并无差异
dir./
# 工作目录,除非本身配置文件存放不同文件夹下,否则还是自定义这个地址,参考主从部分
sentinel monitor mymaster 127.0.0.1 6379 2
# mymaster 为主机别名,需要在 A-z 0-9 和 ".-_".之内的字符组成
# 后面分别为 ip地址, 端口号 , 以及当主机宕机时多少个哨兵投票就可以决定新的主机;
# 这里面若是配置多个,则监听多个主机
#++++++++++++假设主服务器设置了密码++++++++++++++
# 格式:sentinel auth-pass
sentinel auth-pass mymaster coffeeandice
# mymaster 是主服务器别名(自定义的),coffeeandice是主服务器设置的密码
sentinel down-after-milliseconds mymaster 30000
# 是尝试连续ping 主服务器失败时坚持的时间,单位为毫秒 ,mymaster 为主机名称
三、启动方式:
一、直接哨兵可执行文件:
redis-sentinel sentinel.conf
二、使用redis-server可执行文件,以哨兵模式启动它:
redis-server sentinel.conf --sentinel启动完毕后:哨兵会有不一样的标识

查看日志:(这里示例端口为 26380的哨兵)
清晰的展示了主从关内容详情

+monitor master mymaster 127.0.0.1 6379 quorum 2 # 配置文件内的宕机选举人数
+slave slave .. 表示从服务器参数
四、关于哨兵的一些基本命令
其实这部分内容上面的官方文档也有提及
$ redis-cli -p 26379
# 这里可以是任意一个哨兵的端口号① 获取主服务器的某些参数
127.0.0.1:26379> sentinel master mymaster② 获取所有从服务器的信息
127.0.0.1:26379> SENTINEL slaves mymaster③ 获取其他哨兵的信息
127.0.0.1:26379> SENTINEL sentinels mymaster④ 让主机暂时休眠,代替宕机
redis-cli -p 6379 DEBUG sleep 30
# 如果存在密码 ,则加上参数 -a 后接密码
eg: redis-cli -p 6379 -a coffeeandice DEBUG sleep 30获取主机地址 及其端口号信息
127.0.0.1:26379> SENTINEL get-master-addr-by-name mymaster⑤ 用于新增监听一个主机
SENTINEL MONITOR
# 对应上述配置文件设置内容,可以在运行时执行 ⑤ 用于撤销监听一个主机
SENTINEL REMOVE
# name代表主机的名称,当初设置的别名 ⑥ 用于设置配置文件
SENTINEL SET
五、关于哨兵选举:
我们可以根据上面的休眠命令④来得到如下结果:
主机宕机,先是继续持续尝试访问旧主机,直到等到配置或者默认配置的条件时,开始执行投票,选举新的主机的一个过程;
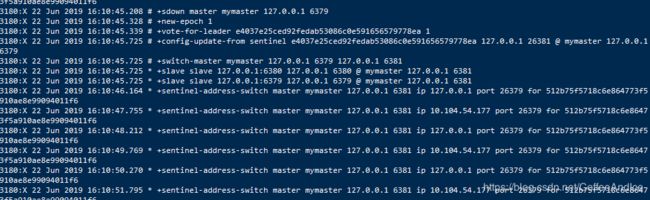
自动扫描哨兵与从服务器
哨兵启动后,会与要监控的master建立相当于俩条连接:
- 一条连接用来订阅master的
_sentinel_:hello频道与获取其他监控该master的哨兵节点信息 - 另一条连接定期向master发送INFO等命令获取并同步r本身的信息
- 自动搜索的过程中,如果发现已经有一个哨兵runid相同或同一地址(ip和端口),则之前匹配的所有哨兵记录清空,重新添加哨兵
与master建立连接后,哨兵会执行三个操作,这三个操作的发送频率都可以在配置文件中配置:
1、定期向master和slave发送INFO命令
2、定期向master个slave的_sentinel_:hello频道发送自己的信息
3、定期向master、slave和其他哨兵发送PING命令
选举与优先级
从服务器选择过程评估关于其的以下信息:[ 下面条件是优先级的,不会并行 ]
- 与主服务器断开的时间。
- 从服务器的优先级。[replica-priority]
- 复制抵消处理。
- 运行ID。
①一个从发现断开主超过十倍配置的主超时(down-after-milliseconds选项),加上 主也不是可用的节点时, 哨兵会认为是不适合故障转移的节点。
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state② 顾名思义是对比 replica-priority 的配置值
③ 可以对比偏移值来选取【即offeset】
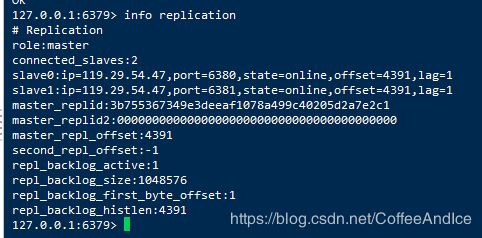
④ 以运行的pid 大小来选取,最好不要轮到这个配置,最小者成为主服务器
广播配置
待选举完成后,将通过__sentinel__:hello发布/订阅频道广播配置;
因为每一个配置都有不同的版本号,版本就越大 则是最新,待选举完成后广播出去, 所有其他实例将看到这个配置并相应地将更新他们的配置,因为新的配置版本号最大,为最新。