RC ORC Parquet 格式比较和性能测试
RC ORC Parquet 格式比较和性能测试
作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
为什么要比较这三者
为什么要比较,起因是为了提高Hadoop集群的存储和计算效率,尤其是离线Hive作业的效率,为什么比较的是这三者,是因为三者是目前Hive离线作业中正在大规模使用或可能大规模使用的三种主流的相对成熟的文件格式
对于ORC性能的评测,Hortonworks发过一篇被广泛传播和引用的博客 : ORCFILE IN HDP 2: BETTER COMPRESSION, BETTER PERFORMANCE
这篇文章在ORC改进原理等方面说的比较客观,但是实际的benchmark比较数据,即使不说是有故意偏颇的嫌疑,至少也是不科学不客观的,特别是下面这张文件尺寸比较,带有很大的误导性。

这个测试的数据集,看起来用了TPC-DS的数据,貌似很专业的样子
但是首先,这里的测试方法明显的就不科学,压缩算法并不相同有什么好比的(Snappy侧重性能,Zlib侧重压缩率)?不知道作者对RCFile采用了什么压缩算法,但是Parquet+Snappy,ORC+Zlib,这种比较的基调就不公正(当然,这个问题,作者说是因为这是它们默认的压缩格式,但是科学严谨的来说,benchmark应该用统一的标准来衡量)
其次,套多数hive作业任务的的场景,TPC-DS的数据特性和典型的Hive应用场景(至少我们这边的场景)里的数据看起来并不一致。RC File的压缩还不到15%,这压缩率明显不是Hive离线处理数据场景和压缩算法下RCFile的典型表现
三种文件格式简单介绍
Parquet
Parquet的设计方案,整体来看,基本照搬了Dremel中对嵌套数据结构的打平和重构算法,通过高效的数据打平和重建算法,实现按列存储(列组),进而对列数据引入更具针对性的编码和压缩方案,来降低存储代价,提升计算性能。想要了解这一算法逻辑的,可以看Dremel的论文:Dremel: Interactive Analysis of WebScaleDatasets
从文件结构上来看,如下图所示:
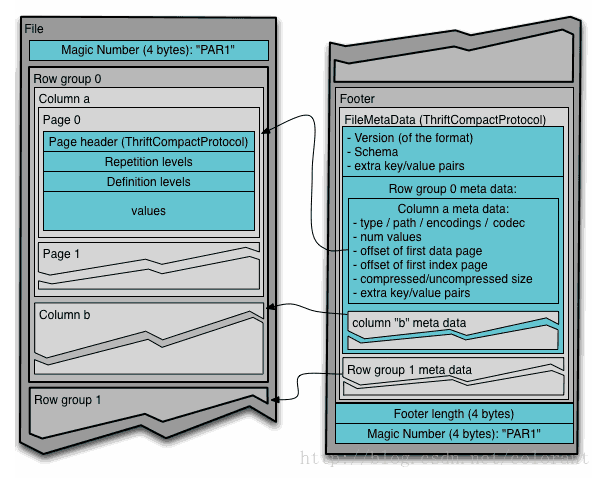
基本上就是一个文件由多个列组组成,数据先按列组(rowgroup)分段(也就是先做行切割),然后在列组内部对每个列的数据分列连续存储(columnchunk)(也就第二步做列切割),每个列内部的数据,再细分成page(可以近似的认为是再做行切割),最后,在文件的尾部,存储所有列组的元数据信息
这么分层设计,从并发度的角度考虑,行切割的目的,主要做为任务的切分单元,比如一个Map任务处理一个列组里的数据。然后列切割的目的,除了按需读取数据,也是做为IO的并发单元。最后Page的拆分,主要是从编码和压缩的角度,进行拆分,以page为单位进行压缩编码,如果近似的理解,也可以认为一定程度上起到了内存和CPU上用量的控制,从Parquet文件的层面来说,Page是数据最小的读写单元。
最后,对列数据提供多种编码方式,比如:字典(Dictionary),游程(RLE),增量(DELTA)等等
综上,Parquet主要还是对Dremel的存储模型这部分的一个实现,在Dremel存储模型定义范围之外,自己额外做的工作,并不多。(这里指的文件格式底层技术实现方面,工程上和大数据生态系各个组件的打通结合方面,还是做了大量的工作的)
ORC
ORC文件格式的一些基础思想和Parquet很像,也是先按行水平切割,在按列垂直切割,针对不同的列,采用特定的编码格式,最后再进一步对编码后的数据进行压缩。支持的编码格式(游程,字典,增量,bit),压缩格式(zlib,snappy,LZO等等)也基本一致
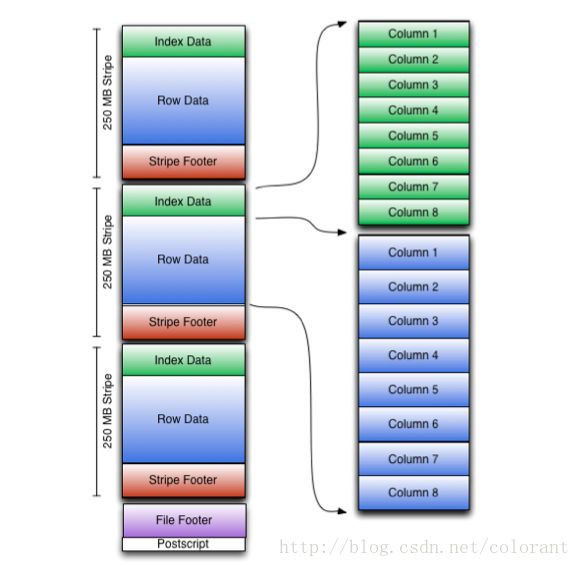
与Parquet不同的地方是,Parquet对嵌套型数据结构的打散和重构的算法,来源于Dremel,通过两种level信息(definition level,repetition level)来标识特定数据在数据结构中层次位置,这两种信息和具体的列数据直接绑定,仅依靠这些信息和对象整体的Schema就能重构出这一列信息原有的层次结构。
而ORC的实现,更加简单直白一些,类似元素是否为Null的信息,就是一组bit位图,而对于元素个数不定的结构,如List,Map等数据结构,则在虚拟的父结构中维护了一个所拥有的子元素数量的信息。这样的带来的问题是,由单纯的某一叶节点列元素的数据出发,是无法独立构建复原出该列数据的结构层次的,需要借助父元素的辅助元数据才能完整复原。
在实现中,ORC对于每个列(基本的或符合结构的)采用了多个Stream分别存储数据和上述各类元数据。
比如String类型的列,如果使用字典编码,那么会生成4个stream,PRESENT Stream用来标识具体String元素是否为Null,DATA Stream,连续存储字符串自身,DICTIONARY_DATA Stream存储字典信息,LENGTH Stream存储每个元素的长度(用来从DATA Stream中定位和拆分数据)

再比如Map类型的列,使用一个PRESENT Stream来标识具体每个Map元素是否为Null,用LENGTH
Stream来标识每个Map元素内部有几个对象
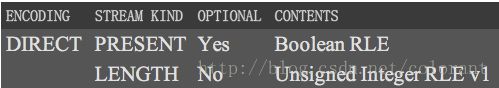
这种处理方式对比Dremel,看起来的确老土很多,理论深度上被甩了不止一条街,不过如果对于嵌套层次不复杂的数据结构,也还是简单有效的。但是,ORC的风评最近感觉明显比Parquet要盛,这又是为什么呢?
个人感觉,主要还是工程实现上的问题,除了核心的数据结构的打散和重建逻辑,ORC的文件格式里,还包含了其它的一些工程优化手段。比如索引(并不是传统意义上的全量排序用索引,更接近统计信息,比如列组的min,max,avg,count等信息,可以用作粗过滤手段,也可以覆盖部分聚合计算的需求),比如Bloomfilter等。而Parquet在这些方面有规划,但是目前似乎基本都没有做。
另外,如果仅从Hive的角度来说,一方面ORC是亲儿子,有些工作开展得比较早,另一方面扁平的数据结构,让Parquet在支持嵌套数据结构方面的优势并不能很好的体现,大概也是原因之一吧。
RC File
RC File的格式,就简单很多了,基本除了先水平切Row,再垂直切Column以外,就剩下每个行组的Metadata里维护了行组的纪录数和每个column及每个Column纪录的长度,除此之外就没有太多别的黑科技了。编码方面Metadata使用RLE编码,Column Data使用Gzip等压缩格式(取决于写入方,比如MR程序)
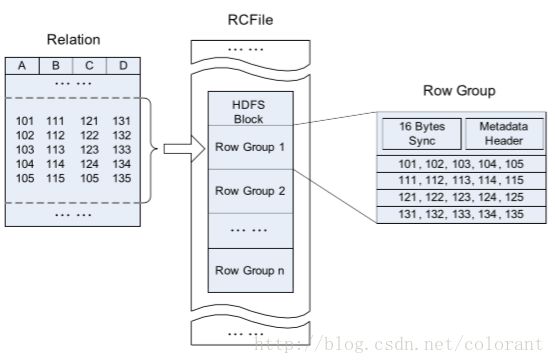
具体看论文 RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems
性能比较
主要做了RC和ORC的比较,Parquet做了一部分,主要还是在Hive的场景下,目前看来ORC会更适合一些(基于hive 1.2.1)
!!! 需要注意的是,具体性能数据取决于集群各种参数配置,具体数据格式内容等因素影响,所以绝对值大小并没有实际意义,比例大小的绝对值也不见得完全有代表性,比例的正负趋势才是基本可以参考的,另外时间有限,部分测试还有一些存疑问题尚未验证
首先是压缩率和写性能,从上表可以看到采用不同的压缩格式,不同的压缩级别,对应不同数据类型,其实结论并不是简单一致的
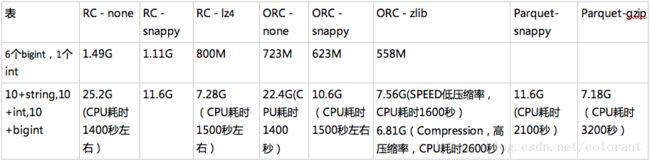
基本上,当前版本情况下,对于String类型比重大的数据,RC文件的尺寸,最佳表现要优于ORC的默认格式(ZLIB, SPEED),但是差距不大(3-5%左右),而对于存int bigint等类型的数据,ORC文件表现优于RC文件是比较一致的
再分析理解一下,可以认为,ORC的编码(Encoding)优势,使得在同等条件下,结果文件尺寸大小要优于RC(30%~100%),而对于复杂String类型比重大的数据,RC文件由于LZ4压缩算法比ZLIB 低压缩率设置下的压缩率的优势,最终结果数据RC+LZ4在CPU耗时略优的情况下,压缩率也略优。 ORC+Zlib可以通过更高压缩率反转尺寸优势,但是CPU耗时就大大增加了。当前hive 1.2.1版本集成的ORC文件格式(0.12+一些改进)还不支持LZ4压缩格式(独立的ORC 1.2.2版本支持),可以想见,一旦集成了,同等条件下,ORC+LZ4的表现应该是最优的。
而Parquet这边,压缩率方面看起来和ORC也没有很明显差距,小幅度的区别的原因应该还是具体Encoding和compress算法的区别。但是CPU耗时方面,明显高出RC和ORC,应该是列打散算法的消耗造成的,也不排除目前Parquet对Dremel算法的应用还有优化的空间。
下面的数据测试读取性能,RC-LZ4 v.s. ORC-ZLIB SPEED

可以看到第一例case中,ORC格式由于column data统计数据的存在,在数据过滤方面可以更好的使用Filter Push down技术,所以性能要明显由于RC格式(数据量100倍)。 无条件count这种,很明显,ORC大概能做到只需要检索原始数据500-2000分之一的数据量,RC大概是十五分之一左右(当然,这取决于表的字段数,RC文件的加速来源于分列存储,ORC格式的加速来源于meta统计信息里Count信息的存在)
而第二例有条件过滤计数case中,ORC还是优于RC,不过我们的数据集case中,检索数据量的大小差异大概只有三倍,大致可以认为是meta统计信息中范围信息起到的过滤作用。 不过,很奇怪的是,理论上ORC文件中添加了Bloom Filter以后,应该可以更好的加速过滤检索,但实际效果并没有见到,还需要再验证,是否是我的测试方法或者测试集又问题,还是当前版本还有Bug存在(1.2.1的版本之前BF这块都有bug,并不能发挥作用,但1.2.1 版本以后,jira上已经找不到这方面bug的报告了)
CPU耗时方面,差异没有那么显著 50%,这也和这个case中,IO是瓶颈,MR任务数量多,平均执行时间短,启动耗时占比不能忽略等因素有关
再看Parquet,还是同样的问题,CPU的耗时明显要偏高(尽管使用了比RC和ORC更快的Snappy压缩方式)
小结
总体可以认为,在我们当前的数据集和hive版本环境下,在文件写入方面,ORC相比RC文件的优势不显著,一些场合RC文件还要更优,在查询检索方面,ORC则基本是更优的,性能差距大小取决于具体数据集和检索模式。如果Hive能集成ORC更新的版本,支持LZ4,并修复一些Bug,那应该就没有任何再使用RC的理由了。
至于Parquet,可以考虑在需要支持深度嵌套的数据结构的应用场合中去使用
需要进一步验证的点
- 内存消耗情况比较
- ORC高版本与Hive集成的进展情况跟踪
- 各种block/strip/page大小参数对文件尺寸,读写性能的影响
- ORC BloomFilter问题的跟踪
- 更大范围的性能验证比较
附录
各种资料
- Spark和ORC的集成情况 https://databricks.com/blog/2015/07/16/joint-blog-post-bringing-orc-support-into-apache-spark.html
- ORC Spec https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
- Hive orc格式配置参数 https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties#ConfigurationProperties-ORCFileFormat
- ORC官网 https://orc.apache.org/docs
- RC格式 http://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/ql/io/RCFile.html
- RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems
- Parquet格式: https://github.com/apache/parquet-format
- Parquet 配置参数: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties#ConfigurationProperties-Parquet
- Parquet 官网 http://parquet.apache.org/
- hive wiki Parquet部分https://cwiki.apache.org/confluence/display/Hive/Parquet
String 和 TimeStamp类型存储日期的比较

理论上用TimeStamp和Date类型的数据结构,应该是要比用String类型的方式表达日期要更高效(毕竟有明确的类型信息),这点从上表中同样的数据使用不同的格式以后压缩率的对比情况上就能看得出来。不过,稍微有点意外的是,在CPU耗时方面,TimeStamp类型远远超过String类型(差4倍。。。),这样使用专门的日期类型的价值就完全被湮没了。照理不应该这么差,不是我哪里姿势没搞对,就是在Hive中,这些类型的读写比较等性能方面还存在很大的改进空间。
顺道,推销一下个人公众号 “望月的蚂蚁”, 和技术完全无关。。。。 以一些有趣的兴趣爱好等为主题,比如乐高,桌游,旅行,摄影。。。工作生活要平衡不是;)
