一线实践 | 借助混沌工程工具 ChaosBlade 构建高可用的分布式系统
在分布式架构环境下,服务间的依赖日益复杂,可能没有人能说清单个故障对整个系统的影响,构建一个高可用的分布式系统面临着很大挑战。在可控范围或环境下,使用 ChaosBlade 工具,对系统注入各种故障,持续提升分布式系统的容错和弹性能力,以构建高可用的分布式系统。
本周三19:30 - 21:00,我们将在 ChaosBlade 钉群直播《如何构建高可用的分布式系统》,手把手演示如何注入真实的故障,欢迎加入我们的钉群(群号:23177705)。(截止目前,ChaosBlade 已达1k+)
ChaosBlade 是什么?
ChaosBlade 是一款遵循混沌工程实验原理,建立在阿里巴巴近十年故障测试和演练实践基础上,并结合了集团各业务的最佳创意和实践,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具。点击这里,了解详情。
ChaosBlade 无需编译,下载解压即可使用,支持基础资源、Java 应用、容器服务类的混沌实验,特点是操作简洁、无侵入、扩展性强。
ChaosBlade @GitHub,点击进入
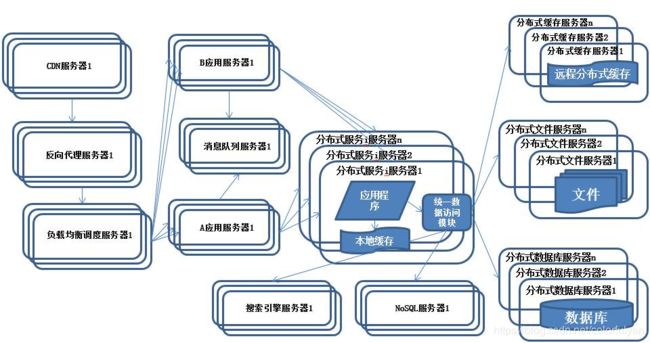
下面我们以微服务分布式系统举例,一步一步构建高可用的分布式系统。
构建高可用的分布式系统
ChaosBlade 的使用方式
ChaoBlade 通过 CLI 方式调用,比如我们模拟 A 服务调用 B 提供的 com.alibaba.demo.HelloService 服务下的 hello 服务延迟 3 秒,我们可以在 B 应用上注入延迟故障,仅需两步操作:
第一步:准备阶段。由于 Java 应用的故障注入是通过 Java Agent 机制实现,所以首先要先挂载 agent,执行的命令是 blade prepare jvm --process
第二步:执行阶段,注入故障。执行命令是 blade create dubbo delay --time 3000 --service com.alibaba.demo.HelloService --methodname hello --provider,即对 B 服务提供方提供的 com.alibaba.demo.HelloService#hello 服务注入 3 秒延迟。
ChaosBlade 使用简洁,如果想了解命令的如何使用,可在命令后面添加 -h 参数,比如 blade create dubbo delay -h。更详细的 chaosblade 操作,可详见新手指南
分布式系统高可用原则
高可用的分布式系统一般需要满足以下原则:
- 失败重试
- 实例隔离
- 请求限流
- 服务降级
- 服务熔断
- 流量调度
- 开关&预案
- 监控告警
- 日志跟踪
混沌实验场景实践
我们以 A 调用 B,B 调用 C,A 同时也调用 D 举例,A1、A2 是 A 服务的多个实例,依次类推。
失败重试
实验场景:调用下游服务实例异常。
容错方案:会再次请求另外一个服务实例进行重试。
场景模拟:对 B1 注入异常故障,A 服务调用到 B1 时会出现调用失败。
预期方案:系统会将 A 服务的请求路由到 B2 进行重试。
blade 命令:blade c dubbo throwCustomException --exception --service --provider
修复方案:添加失败检测和请求重试能力。
实例隔离
演练场景:多次调用下游一个服务实例超时。
容错方案:会隔离或者下线此服务实例,防止请求路由到此服务实例。
场景模拟:对 B1 注入延迟故障,A 服务调用到 B1 时,出现调用超时。
预期方案:系统会自动隔离或下线 B1 实例。
blade 命令:blade c dubbo delay --time --service --provider
修复方案:添加服务质量检查,下线不可用的服务实例。
请求限流
演练场景:服务线程池满。
容错方案:会对入口流量进行限流,防止请求堆积,资源耗尽导致服务不可用。
场景模拟:对 A 注入线程池满故障。
预期方案:线程池满时,触发限流,新请求快速失败。
blade 命令:blade c dubbo threadpoolfull --consumer
修复方案:添加限流能力。
服务降级
演练场景:A 对 B 是强依赖,对 D 是弱依赖,A 调用 D 线程数多,争抢调用 B 服务的资源。
容错方案:对弱依赖 B 进行降级,减少资源分配。
场景模拟:对 A 注入调用 D 线程数满故障。
blade 命令:blade c dubbo threadpoolfull --service --consumer
修复方案:梳理服务依赖,添加服务降级能力。
调用熔断
演练场景:下游服务不可用
容错方案:触发熔断,快速失败返回
场景模拟:对 B 服务所有的实例注入延迟超时故障。
blade 命令:blade c dubbo delay --time --service --provider
修复方案:当下游服务不可用时,能立即熔断,快速失败。
流量调度
演练场景:上游高并发下,扩容下游服务,在服务实例初始化时,CPU 负载高,导致上游服务受影响
容错方案:当服务实例机器负载高时,自动切流到正常机器
场景模拟:对 B1 做 CPU 满载操作。
blade 命令:blade c cpu fullload
修复方案:添加系统、应用资源监控和流量调度能力。
系统预案
演练场景:杀掉服务实例。
容错方案:快速拉起或扩容
场景模拟:杀掉 B 大部分实例。
blade 命令: blade create process kill --process
修复方案:添加相关系统预案。
监控告警
注入任意故障,验证监控告警的有效性
日志跟踪
演练场景:修改应用中具体方法返回值。
容错方案:全链路调用日志记录。
场景模拟:修改 B 服务的一个业务方法的返回值。
blade 命令:blade c jvm return --classname --methodname --value
修复方案:添加全链路日志记录,便于排查和追溯问题。
总结
通过 ChaosBlade 工具能简洁有效的执行混沌实验,上文提到的请求限流、降级熔断功能可以使用 Sentinel 来解决。阿里云 AHAS 产品已经集成混沌工程平台 和 Sentinel 功能。ChaosBlade 除了上述实验场景,还有更多的场景期待你来挖掘。
后续规划
ChaosBlade 后续会继续增强对 Java 生态的混沌实验,比如对 Redis、GRPC、RabbitMQ 等主流组件的支持。也会增加云原生设施的混沌实验,比如 Kubernetes、Service Mesh 等。
阿里云详情优惠活动
https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=vhl4f2ss
腾讯云详情优惠活动
https://cloud.tencent.com/redirect.php?redirect=1040&cps_key=431fc56be57d892cc2d064e86028022b&from=console
腾讯云秒杀活动
https://cloud.tencent.com/redirect.php?redirect=1039&cps_key=431fc56be57d892cc2d064e86028022b&from=console