open64--编译过程 compile process
一、优化控制的思想
1、低层的优化
编译时间短; 优化不容易出错; 计算的精确性比较高; 生成代码执行比较慢(?)。
2、高层的优化
编译时间长; 优化比较激进; 通过牺牲计算的精确性,来保证高的性能; 生成的代码执行比较快(?)。
3、好的优化会通过多个选项来控制
4、优化选项和对应的阶段
-O0: -g时的默认选项,只走FE和CG,所有优化都关闭;
-O1: 只走FE和CG,打开局部优化;
-O2: 默认选项,打开WOPT和剩余CG的优化;
-O3: 打开LNO;
-IPA: 打开IPA;
5、群组选项
选项通过编译阶段或者所做优化的特性来分成不同的组,一般语法如下:
-GROUPNAME:opt[=val]{:opt=[val]};
一些类似于GNU选项的flag:
-march -ffast-math -ffloat-store -fno-inline
其他一些组选项:
-LIST: 用户列表? User listing
-OPT: 优化
-TARG: 目标机器
-TENV: 目标环境
-INLINE: 后端inline
-IPA: 过程间分析
-LANG: 语言特点
-CG: 代码生成
-WOPT: 全局标量优化
-LNO: 嵌套循环优化
6、driver在编译器中的作用
相关的文件在 open64/driver 文件夹下;
作用是处理所有的命令行选项;
调用所有编译的阶段:preprocessor(处理器之前?)、前端、内联、后端(be, lno, wopt, cg)、汇编、链接;
维护与GNU选项的一致性;
1、编译器驱动器
(1) open64/driver/OPTIONS文件
记录了选项的详细说明;
可以将一个选项对应到另一个不同的选项上去??
(2) 单个可执行的,多个软连接??( single executable, multiple soft links)
(3) arg[0]字符串用来辨别编程语言
(4) 查询与编译器相关的环境变量
(5) 在缺省选项 –march=auto 时,查询主机处理器的信息
(6) 为系统特定的选项查询编译器的缺省选项文件
二、C和C++的前端
1、C/C++前端的历史
(1)2000年开放源码时,使用的是GNU2.95的前端
采用的是将GNU的中间树直接翻译成whirl形式;
C和C++使用独立的前端嵌入到open64里;
(2)2004年更新到GNU3.3.1的前端
(3)2006年为虚拟的目标机定义了.spin文件格式
Open64不再将GNU编译器当做自己的一部分进行维护;
将更新到每个GNU版本的工作进行了简化;
在C和C++消失之间复制代码??(duplicate code between C and C++ eliminated)
(4)2007年3月移植GNU4.0.2的前端
(5)2007年10月移植GNU4.2.0的前端
(6)为将来其他GNU语言留有扩展
2、使用GNU编译器做前端
(1) 最开始使用X86-64上的GNU编译器
A老方法是:
对C用open64/kgccfe前端;
对C++用open64/kg++fe的前端;
在GNU代码中嵌入生成whirl的调用;
C++要求运行整个的编译过程去汇编生成完整的转换后的数据;
使用C和C++中的多个源码树;
B新方法是:
用gspin树节点作为模拟GNU树的元素,在libspin库中实现此功能,同时可以打印到.spin文件中;
在gcc编译过程中添加识别点来拦截GNU树
在gcc/tree.c中,用GNU树生成gspin树节点;
Open64/wgen将gspin树节点(.spin文件)翻译成whirl节点(.B文件),wgen的操作模式在kgccfe/kg++fe之后被模拟??( wgen’s mode of operation modeleted after kgccfe/kg++fe)
(2) Gspin树节点
将GNU树中的信息完整的转到.spin文件中;
以8字节的gspin节点作为原子建立块;在libspin/gspin-tree.h中定义gspin nodes; gspin nodes代表GNU树节点中的一个域的信息;连续的几个gspin nodes代表一个GNU树节点;表示图在libspin/gspin-tel.h中定义;
Libspin负责管理已经分配的gspin节点
Gspin nodes的I/O通过mmap()处理
Dump成ASCII码,为避免无限递归,每个节点只dump一次
Gspin nodes的一个例子(如下图):

三、Fortran前端
1、历史
Fortran前端源于cray fotran compiler。
现在fotran前端包括:cray fortran 前端 和 生成whirl的适配器。
多个运行时的库文件:libF77, libI77, libU77, libfi, libf, libu. 其中,libfortan.so包含了前面所有的库文件。
修正了很多的bug,并且在pathscale上进行了增强。
2、Fortran前端的实现
Fortran90的前端分三个子阶段:
(1) 词法分析和语法分析阶段 Lexer(src_input.c, lex.c) and Parser(p_*.c)
程序被表示为树的形式;
在一堆表格中(sytb.*),树节点是入口:
Scp-tbl 表示作用域;
SH-tbl表示语句头;
global_name_tbl, name_tbl表示Fortran标示符;
AT_tbl表示变量和过程的属性节点;
CN_Tbl表示常量的值;
IR_Tbl表示操作符节点;
IL_Tbl表示列表链接节点;
还有很多表示数组界限,文件名的表格。
(2)语义阶段(s_*.c)
主要处理不能在语法阶段即时转换的操作。
(3)生成whirl的阶段
函数cvrt_to_pdg()和函数send*() (在icvrt.c文件中)转换树和符号表为所需要的形式;然后调用crayf90/sgi下的程序生成whirl。
调试所需:
build时加入-D_DEBUG;
运行mfef95时,加入:-uall (打印所有表格处理)和-uir2(打印用的最多的表格);
在mfef95上debug时,可以调用fe90/debug.c下的程序。
四、Goto转换
1、将用goto语句所写的循环转换为高层循环的形式,从而为LNO提供良好支持。
2、goto转换的理论基于Ana Erosa和Laurie Hendren的一篇论文。
3、在LNO之前会调用一次goto转换(be/com/opt_goto.cxx文件中)
4、GNU4.2的前端不再生成高层循环的结构。
5、为了方便VH whirl的使用,在后端的开始部分,添加了新阶段(在be/be/goto_conv.cxx文件中)
五、VH whirl 优化
在Lower到high whirl时做一些优化
1、第一部分处理常见的语言结构(be/vho/vho_lower.cxx)
其中的优化包括:
位域的优化;
short-circuit boolean expressions:就是尽快判断出布尔表达式的值;
switch语句的优化;
简单的if语句的转换;
将小的结构体的复制lower成对各个对立域的赋值;
将一些代码序列转化为intrinsics;
还有其他一些基于类型的优化:max, min等
2、第二部分,将fotran90的结构生成高效的代码(be/vho/f90_lower.cxx)
数组部分的操作扩展为循环;
为了保留语义上并行的部分,引入数组临时变量,例如:
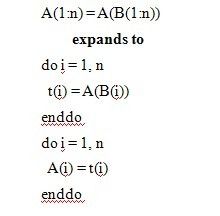
六、Lowering
VHO之后的所有lowering都是通过调用wn_lower()函数实现的(be/com/wn_lower.cxx);参数LOWER_ACTIONS的每一位都控制了一种类型的lowring;lowring会递归的遍历这棵树,并且在其中对节点应用相关的lowring; Mostly simple tree transformation???
七、whirl的简化器(whirl simplifier)
它的作用是将whirl树简化为另一种更加有效地形式。
它在common/com/wn_simp_code.h中实现。当调用WOPT时,树节点类型被转为wn或者coderep;同时前端会将常数表达式转为常量。
在生成whirl树时会自动调用whirl简化器,因为它是代价最小的优化方式,所以在任何一次转换发生时,都应该调用一下whirl简化器。
八、链接转换
实现:common/com/x8664/targ_sim.cxx
控制:在lower时调用;处理如何将不同类型的参数进行传递;处理如何返回不同类型的函数返回值。
Fake parameters for return structs introduced by lowerer??
九、数据层 data layout
1、
作用:解决程序中变量的存储分配问题(变量在编排之前都是离散不连续的)。
出现的优化机会有:对齐;引用的局部性。
策略:延迟优化直到可以看见分配某些相对位置的收益。
2、mechanism
设计的一个方向是使它能在优化和编译阶段连续的使用。
发生阶段:IPA,common块分裂和padding
LNO,强制对齐
等级的数据层表示:对每个符号,使用ST_base和ST_ofst表示位置。ST_base可能会晚些展开。
3、堆栈的数据层
实现:be/com/data_layout.cxx
主要处理:形参、Fixed temporaries for Fortran alternate entry parameters??、实参、其他一些局部变量(用户或者编译时生成的)。
几种堆栈类型:small(只使用$sp), large(使用$fp $sp),dynamic(使用$fp $sp)
在代码生成的最后,堆栈也确定了,st_base被按照$sp or $fp设置
