hive小操作·Ieda下的hive-udf操作
代码环境:Windows10+Idea19-01+spring-boot2.1.6+jdk1.8
jar包运行环境:centos虚拟机+Hadoop3.1.1+hive3.1.1+jdk1.8
在idea中新建一个spring-boot项目,包含基本的就行,本项目中只包含一个web包,如下pom.xml
其中使用idea做udf操作必须包含hive,和Hadoop-common两个包,而且必须跟你集群环境中的版本相同
注意:
①项目中增加hive的lib下的全部jar包和Hadoop中share下hadoop-common-2.5.1.jar(Hadoop眼下最新版本号2.5.1)。
②UDF类要继承org.apache.hadoop.hive.ql.exec.UDF类。类中要实现evaluate。
当我们在hive中使用自己定义的UDF的时候,hive会调用类中的evaluate方法来实现特定的功能
③导出项目为jar文件。
注:项目的jdk与集群的jdk要一致。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.6.RELEASE
com.hello
hive
0.0.1-SNAPSHOT
hive
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
com.vaadin.external.google
android-json
org.apache.hive
hive-exec
3.1.1
org.apache.hadoop
hadoop-common
3.1.1
org.springframework.boot
spring-boot-maven-plugin
然后新建一个类GetCommentNameOrId
package com.hello.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetCommentNameOrId extends UDF {
//在集群中,hive的udf操作只运行evaluate方法
public String evaluate(String url,String flag){
String str = null;
Pattern p = Pattern.compile(flag+"/[a-zA-Z0-9]+");
Matcher m = p.matcher(url);
if(m.find()){
str = m.group(0).toLowerCase().split("/")[1];
}
return str;
}
public static void main(String[] args) {
String url = "http://cms.yhd.com/sale/vtxqCLCzfto?tc=ad.0.0.17280-32881642.1&tp=1.1.36.9.1.LEffwdz-10-35RcM&ti=ZX8H";
GetCommentNameOrId gs = new GetCommentNameOrId();
System.out.println(gs.evaluate(url,"sale"));
}
}
然后在使用maven打包
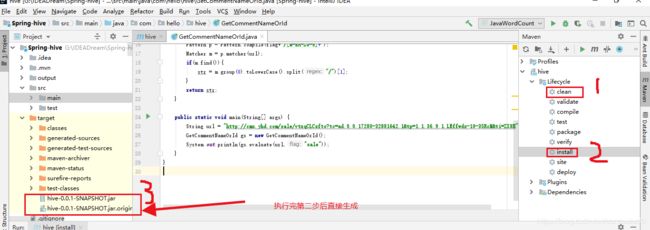
生成两个文件,我使用的是第二个.original的文件,使用这一个需要将后缀改为.jar,直接生成的jar包,测试过,我这里没有通过。
将改好的jar包上传到虚拟机后执行hive操作成功;
使用方法
先运行start-dfs.sh集群,然后执行hive
在hive中进行操作
1、将jar包导入到hive中
add jar /**/**/**.jar;
2、将jar包中的方法名改个简单的临时的名字
create temporary function GetComment as ‘com.hello.hive.GetCommentNameOrId';
3、查看下是否将方法加入到hive中
show functions;
4、使用udf
select GetComment ("sdfas/vtxqCLCzfto?782dajkf","sale") from a;//在使用a之前先创建一个a的数据表
create table a(url string);
如果表中字段url有数据,也可以直接使用
select GetComment (url,"sale") from a;
GetComment (url,"sale")这个函数的意思是使用正则匹配sale后面的“/[a-zA-Z0-9]+”