阿里开源项目dataX简介
一、安装教程
http://www.myexception.cn/open-source/1866902.html
http://yangyoupeng-cn-fujitsu-com.iteye.com/blog/1832143
二、应用程序入口在Engine.java类中
/**
* Program entry > NOTE: The DataX Process exists code exit with
* 0: Job succeed exit with 1: Job failed exit with 2: Job
* failed, e.g. connetion interrupted, if we try to rerun it in a few
* seconds, it may succeed.
*
*
* @param args cmd arguments
*
* @throws Exception*/
public static void main(String[] args) throws Exception {
String jobDescFile = null;
if (args.length < 1) {
System.exit(JobConfGenDriver.produceXmlConf());
} else if (args.length == 1) {
jobDescFile = args[0];
} else {
System.out.printf("Usage: java -jar engine.jar job.xml .");
System.exit(ExitStatus.FAILED.value());
}
confLog("BEFORE_CHRIST");
JobConf jobConf = ParseXMLUtil.loadJobConfig(jobDescFile);
confLog(jobConf.getId());
EngineConf engineConf = ParseXMLUtil.loadEngineConfig();
Map pluginConfs = ParseXMLUtil.loadPluginConfig();
Engine engine = new Engine(engineConf, pluginConfs);
int retcode = 0;
try {
retcode = engine.start(jobConf);
} catch (Exception e) {
logger.error(ExceptionTracker.trace(e));
System.exit(ExitStatus.FAILED.value());
}
System.exit(retcode);
} 该函数的运行流程如下:

三、生成XML任务流程
dataX将一次数据导出导入操作称为一个任务(job),任务以xml形式保存在jobs目录下。生成一个任务的流程如下:
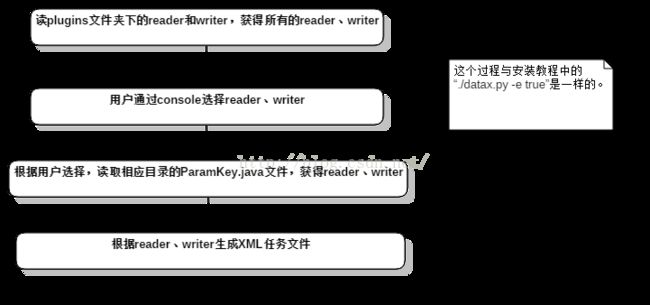
dataX支持不同数据库之间的导入导出操作,不同数据库组件以插件的形式调用。用户选择reader、writer的过程其实就是在选择插件。控制台输入如下:
Taobao DataX V1.0
Data Source List :
0 mysql
Please choose [0-0]: 0
Data Destination List :
0 mysql
1 redis
Please choose [0-1]: 0
Generate D:\dlc\workspaces-datax\dataexchange/jobs/mysqlreader_to_mysqlwriter_1472197442111.xml successfully .
mysqlreader
mysqlwriter
用户需要根据注释修改这个xml文件,使之可以正确连接数据库,并导入导出指定的数据。文件的执行见第四步。
开头的流程图里已经说过了,该xml文件是根据ParamKey.java生成的,因此当ParamKey.java变化时,要及时拷贝一份到相应插件目录下。
hdfs的RCF文件是压缩文件,无法读取,解决办法是将RCF文件改为text
四、执行任务
修改Engine.java的main函数,主要是为了比较方便的使用第三步生成的任务文件。修改后仍然Run as->Java Application
// String jobDescFile = null;
// if (args.length < 1) {
// System.exit(JobConfGenDriver.produceXmlConf());
// } else if (args.length == 1) {
// jobDescFile = args[0];
// } else {
// System.out.printf("Usage: java -jar engine.jar job.xml .");
// System.exit(ExitStatus.FAILED.value());
// }
String jobDescFile = "D:\\dlc\\workspaces-datax\\dataexchange\\jobs\\mysqlreader_to_rediswriter_1472175472641.xml";public int start(JobConf jobConf) throws Exception {
...
// 初始化reader线程池
NamedThreadPoolExecutor readerPool = initReaderPool(jobConf,
storagePool);
// 初始化writer线程池
List writerPool = initWriterPool(jobConf,
storagePool);
...
// 生成报告 初始化线程池的过程如下:
(1)读取任务文件获得一个PluginParam对象,而后经过任务分割器(一般在相应插件的目录下,实现了Splitter接口的类)将一个PluginParam分隔为多个。切分条件一般是任务文件中配置的多个表,多个表之间通常有固定的分隔符或解析规则,然后每个表又成为独立的任务。
(2)根据任务文件中配置的concurrency参数,以及第(1)步中实际切分得到的job数量,初始化线程池的大小(选择两个值中较小的那个)
这里要注意concurrency参数,这个并不是简单的描述线程数量,所以不要指望通过增加这个数值来提高导入导出速度。e.g. 如果插件没有提供Splitter,就算任务文件中指定了多个表,也还是单线程的,因为没有任务分割器去做分割的操作。
顺便提一下,limit参数也不是限制导入导出的数据行数的!
(3)执行任务。任务执行流程由ReaderWorker.java和WriterWorker.java的run方法描述。举个栗子
/**
* Read data, main execute logic code of {@link Reader}
* NOTE: When catches exception, {@link ReaderWorker} exit process immediately.
*
* */
@Override
public void run() {
try {
int iRetcode = (Integer) init.invoke(myObject, new Object[] {});
if (iRetcode != 0) {
logger.error("Reader initialize failed .");
System.exit(ExitStatus.FAILED.value());
return;
}
iRetcode = (Integer) connect.invoke(myObject,
new Object[] {});
if (iRetcode != 0) {
logger.error("Reader connect to DB failed .");
System.exit(ExitStatus.FAILED.value());
return;
}
iRetcode = (Integer) startRead.invoke(myObject,
new Object[] { this.sender });
if (iRetcode != 0) {
logger.error("Reader startRead failed .");
System.exit(ExitStatus.FAILED.value());
return;
}
iRetcode = (Integer) finish.invoke(myObject, new Object[] {});
if (iRetcode != 0) {
logger.error("Reader finish loading failed .");
System.exit(ExitStatus.FAILED.value());
return;
}
} catch (Exception e) {
logger.error(ExceptionTracker.trace(e));
System.exit(ExitStatus.FAILED.value());
}
}writer是类似的。主要的一个区别是:writer在任务文件(xml)中可以是一个list,即可以配置多个writer,每一个最终都是一个单独的线程。而reader在任务文件中只有一个。
如果用户想实现自己的插件,那么继承Reader.java或Writer.java,并实现这几个抽象方法就可以了
五、其他
(1)前面讲的是代码调试,真正的任务文件是这样执行的
①cd到bin目录,该目录下有一个datax.py,是一个python文件
cd /xxx/datax/bin
②执行
./datax.py /xxx/datax/jobs/hdfsreader_to_rediswriter.xml
(2)安装教程中使用了rpmbuilder以及ant,其实就是把源码打包、拷贝到指定目录。如果不想写spec文件,手动打包拷贝文件也是可以的
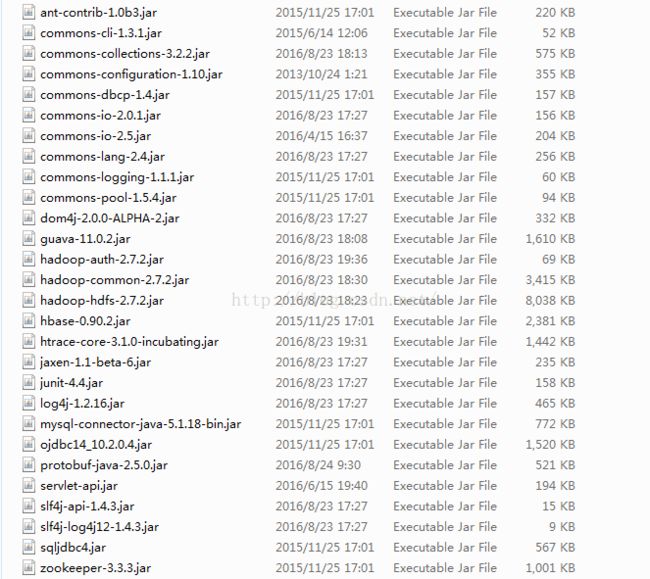
(3)dataX不支持hadoop2,这是需要更新dataX的libs目录下的hadoop依赖。这个过程可能会引入更多的依赖,因此会有大量的ClassNotFound、NoClassDefound异常,引入对应的依赖就可以了。我修改后的依赖如下(只做参考):
(4)dataX使用log4j记录日志,保存于dataX/logs目录下