从零开始搭建Linux共享服务器(云享系统)
从零开始搭建Linux共享服务器(云享系统)
是男人就下100层,是汉子就来搭个服务器吧ヾ(◍°∇°◍)ノ゙
主要思路
所谓共享服务器,就是支持多人文件共享的HTTP服务器,功能十分简单,但我们关注的是如何尝试构建较高性能服务器、开放出用于扩展功能的接口、并且高效的管理文件数据;所以我们需要经过建立TCP服务端、将到来的客户端连接添加到线程池中、线程获取任务后解析请求报文、根据处理结果调用响应模块、响应模块根据需求调用MySQL(真汉子数据库也要自己封装)里的信息,组织响应报文这些过程,最后达到列表展示|文件上传|下载|断点续传的功能
ps:为了避免文章冗余,我将代码的实现略去只保留函数的原型和说明,有需要的小伙伴可以在最后的Github连接里找到项目源码O(∩_∩)O~
一、建立TCP服务端
构建单例模式
就我们这个例子,服务端存在一个就就够了,并且在一开始就最好能加载所有的资源并开始响应请求,所以我选用了饿汉模式来构建服务端类;
//HttpSever.hpp
class Server{
static Server http_serv;
Server() {};
Server(const Server&)=delete;
Server& operator=(const Server&)=delete;
public:
static Server* GetHttpServer(){
return &http_serv;
}
...
};
Server Server::http_serv;
建立TCP连接
这里我们是使用网络套接字建立TCP连接,作为服务端,需要先创建一个socket文件,在绑定端口后开始监听,当一个新的客户端连接请求到来并被放入已完成连接队列里时,Accept函数为这个链接创建一个专门用于通信的socket文件并返回操作句柄,服务器则继续监听,接收请求成功后,客户端就可以通过通信socket来和服务器进行数据交换了,至此能够收发数据的TCP服务端至此初步建立;我将这些步骤封装在Socket类里,这里通过图来简单说明下流程:
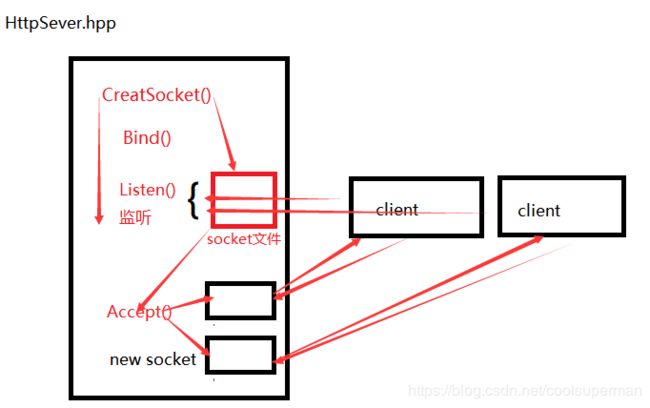
二、线程池创建与服务端任务添加
为什么要使用线程池技术呢?
我们来举一个真实的栗子—张三火了,CXK的那种,粉丝们都疯狂的想要访问这个服务器来下载它的照片(请强忍不适往下看O(∩_∩)O~)此时服务器所要处理成千上万的连接请求,我们知道,当建立一个连接后,我们往往需要将处理请求的任务交给其他的执行流,以便继续响应其他请求,如果为每一个接入的请求分配一个线程的话,如此巨量的线程创建,调度,销毁(暂且不论线程创建的上限是多少)所花费的系统开销也会成倍增长,以及因此导致的缓存和系统性能下降,更不用说有一天我上了热搜,大量突发性请求产生的线程很可能会使服务器内存达到极限,出现错误;而线程池维护者多个线程与一个等待队列,当线程池里有闲置线程时,等待队列里的任务才会被分配执行;就好比演唱会位子是固定的,所有人都要排队,当有空位置时才会放人进去,这样不管粉丝有多少,都不会让演唱会崩溃;
线程池创建
简单来说,线程池的核心是循环创建的一组线程以及一个等待队列,线程创建好后进行分离,然后因为队列里没有任务,进入休眠;当任务到来时,将任务添加进等待队列,然后再唤醒一个或多个闲置进程来"领取"它;那么任务具体是以什么样的形式被添加进来的呢?,我们要首先创建一个任务类:
//Threadpool.hhp
typedef bool(*Header)(int);
class Task{
private:
int socket;//传入参数
Header TaskHeader;//任务函数的函数指针
public:
Task(int s=0,Header TH=NULL)//初始化赋值
:socket(s),TaskHeader(TH)
{}
void SetTask(int s,Header TH);//创建后赋值;
bool Run();//运行;
};
我们规定要运行任的务以它的函数指针和它的参数构成的类,当需要运行时,将参数传入函数指针即可;
多线程的运行是并发的环境,而线程们获取和添加任务,又并非是原子性操作,极易引发线程安全问题,所以还要条件变量,互斥量控制线程的休眠与唤醒,互斥锁保证同一时间访问等待队列时的唯一性;我们来通过画图梳理一遍详细的过程:
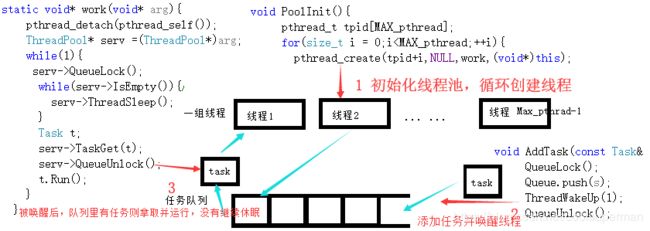
服务端任务添加
当线程池构建好后,我们就可以在成功接收到连接请求后,将返回的新socket句柄和运行函数构建一个任务类,添加进线程池的任务队列,线程池就会在有空余时自动运行啦;
//HttpSever.hpp
void Go(){
while(1){
int client_socket=sock.Accept();
if(client_socket==-1)
continue;
Task tt(client_socket,Header);
pool.AddTask(tt);
}
三、接收与解析HTTP数据
在线程获取到了任务后,需要对客户端发送到socket文件的请求HTTP数据(报文的首行,头部)进行读取,解析,才能够确定这个服务端想要什么,然后执行对应的响应;
接收HTTP首行-头部
客户端向我们发送的所有数据,都存储在客户端socket上,所以申请一块空间用来存放读到的数据,但要注意的是,在我们读取的时候,并不知道客户端是否已经发送了完整的http请求头在socket上,而一般的读取操作,会将读取的数据从原来的文件里删除,所以我要采用探测读取法,每次读取时并不删除socket里的数据,当检测读取到了头部结尾+空行(\r\n\r\n)时,证明头部和首行读取完毕,此时再用传统的读取方式再读一遍,删除socket里的头部数据;
解析HTTP首行-头部
在获得了Http首行和头部后,我们需要对其进行解析,为此我们需要维护一个类来存储这些信息;
//Tools.hpp
class RequestInfo{
public:
std::string _method;//请求类型
std::string _version;//协议版本
std::string _path_info;//请求相对路径
std::string _path_phys;//请求绝对路径
std::string _query_string;//查询字符串
std::vector<std::string> _part_list;//下载请求块;
std::unordered_map<std::string,std::string> hd_list;//存储头部键值对;
struct stat _st;//获取文件信息;
std::string _err_code="200";//错误码
...
};
首先,我们要把首行分离出来,得到首行里的请求方法,版本协议,以及URL,将URL里的请求路径拆分出来后,判断请求路径指向文件是否存在,存在则并更新文件信息并转化为绝对路径存储;其次,将接下来头部里的一个个键值对用unordered_map存放起来,至此首行与头部便解析完成;
四、组建响应模块
至此,我们已经和客户端建立了联系,明白了客户端想要什么,所以就根据要求调用不同的响应即可,但注意,客户的请求并不是一成不变的,合格的服务器程序要能够快捷的进行功能扩展,所以在这里我使用了继承/多态的方法来使得处理请求的模块化,在扩展时只专注与功能本身,其他方面继承基类方法即可:
首先定义一个用于扩展的抽象类:
//HttpResponse.hpp
class ResponseBasic{//响应接口类
public:
ResponseBasic(int sock):_cli_sock(sock)
{}
virtual bool ProccessRun(RequestInfo& info)=0;//组织响应;
virtual bool RspBody(RequestInfo& info)=0;//组建正文;
virtual bool Response(RequestInfo& info)=0;//整个响应流程运行;
void CommonHeader(RequestInfo& info);//最大程度上组建通用头部,减少代码冗余,其实是懒得再写...;
bool InitResponse(RequestInfo& req_info);//实现好的响应模块初始化对下面的类成员进行初始化
protected:
bool SendData(const std::string &buf);//实现好的传输数据模块
bool SendCData(const std::string &buf);//实现好的分块传输模块
protected:
mySQL SQL;
int _cli_sock;
std::string _rsp_header;//响应头
std::string _rsp_body;//响应正文
std::string _end;//分块传输结尾
std::string _etag;//ETag字段用于唯一标识文件是否被修改
std::string _lmod;//最后一次修改时间;
std::string _date;//系统当前时间;
std::string _fsize;//文件大小;
std::string _ftype;//文件类型;
std::string _cont_len;//正文长度;
};
接下来我们一共实现了五个模块:错误响应,文件列表展示模块,文件下载模块,文件上传模块,分块下载模块(断点续传)模块
错误响应模块
这个模块十分的重要,根据错误响应,客户端和服务端都可以清楚地知道当请求失败时,问题出在哪里,记得我们存储信息的类里面有一个错误码成员变量吗?,当处理请求失败时,立刻更新错误码,然后调用错误响应模块,根据我们在一个无序图里存放的错误信息解释,组织错误响应报文;
存放错误码解释的无序图:
std::unordered_map<std::string,std::string> err_exp={
{"200","OK"},
{"206","PARTIAL CONTENT"},
{"400","Bad Request"},
{"403","Forbidden"},
{"404","Not Found"},
{"405","Method Not Allowed"},
{"413","Request Entity Too Large"},
{"500","Internal Server Error"},
};
文件上传模块
当解析完成后,判断是一个CGI请求时,我们在外部完成文件上传响应,首先根据请求头部的键值对设置环境变量,创建一个子进程,继承父进程的环境变量,这样就传输了必要的头部信息,再通过匿名管道的方式传输数据,用管道描述符替换父子进程的标准输入和标准输出,这样通过cin,cout就可以进行数据交互啦;上传文件时,协议头里的Content-Type指定了boundary -一个随机生成的字符串,用来分隔文本的开始和结束
- 境变量里的Content-Type字段里获取boundary,然后处理数据:
----boundary
first_boundary: ------boundary
middle_boundary: \r\n------boundary\r\n
last_boundary: \r\n------boundary--
- 文起始位置匹配first_boundary,获取上传文件名称后,创建一个同名文件
- 从剩下正文匹配middle_boundary,将该位置之前数据存储到文件中
- 当匹配到las_boundary,将该位置之前数据存储到文件中;
- 通过管道让父进程组织一个成功的相应报文;
- 父进程根据文件名更新文件相关信息到MySQL库中;
列表展示模块
如果解析出的HTTP请求是一个文件请求,并且该文件是目录时,就调用列表展示模块;
- 根据用户调用MySQL中的对应表,将表中所有对象的信息进行获取并存储;
SQL.Select("root");//这是自行封装的函数,在下一节讲到;
- 组织HTTP响应头部:先组织首行再组织头部。这里要注意目录下可能有很多的文件,如果遍历一遍所有的文件计算出Content-length响应回去,效率太低,因此这里采用分块传输(Transfer-Chuncked),每次传输body的一部分内容(Transfer-Encoding: chunked)
- 组织html展示页面;
- 发送HTTP头部,正文;
html页面:
<html>
<head>
<title>Home/Catalogtitle><meta charset='UTF-8'>
head>
<body>
<h1>[Path]:/h1><form action='/upload' method='POST' enctype='multipart/form-data'>
<input type='file' name='FileUpLoad' />
<input type='submit' value='上传' />
form>
<hr/>
<ol>
<li>
<strong><a href='/hello.txt'>hello.txta>strong>
<br/>
<small>Modf: Tue,16 Jul 2019 10 : 04 : 26 GMT
<br/>text/plain Size:11B
<br/><br/>
small>
li>
ol>
<hr/>
body>
html>
文件下载模块
当解析到的HTTP请求是一个文件请求,并且该文件不是目录时,调用文件下载模块
- 根据文件名从MySQL中获取相关信息;
- 组织Http相应首行与头部,并发送
- 组织并发送正文数据
断点续传模块
在文件下载过程中,有可能遇到网络故障而暂停下载,当下次继续下载时,我们希望能够从上次的位置继续下载而不是重头开始,从而提高传输效率;
在这里,我们先要了解以下几个字段:
Range/Content-Range
- Range是客户端发送续传请求时所用的字段,它定义了第一个字段与最后一个字段,共有五种方式
Range: bytes=0-100 表示第 0-100 字节范围的内容
Range: bytes=-100 表示最后 100 字节的内容
Range: bytes=100- 表示从第 100 字节开始到文件结束部分的内容
Range: bytes=0-0,-1 表示第一个和最后一个字节
Range: bytes=0-100,101-200 多个范围
- Content-Range是服务端发送续传响应时所用,表示当前响应范围和总大小
//Content-Range: bytes (unit first byte pos) - [last byte pos]/[all length]
Content-Range: bytes 0-100/1000
Last-Modified/Etag–If-Range
有一种情况,客户端发起续传请求时,服务器端对应文件已经被改变,直接续传就会出错,通过 Last-Modified和 ETag 标识该文件是唯一的。
当客户端发起续传请求时,服务器端的对应文件已经发生了改变,此时在续传就会出现问题,所以我们要通过Last-Modified和ETag来表示文件的唯一性;
- Last-Modified:
- If-Modified-Since :由客户端向服务器发送的HTTP 头信息,记录最后修改时间。
- Last-Modified:由服务器向客户端发送的HTTP 头信息,记录最后修改时间。
客户端通过 If-Modified-Since 将先前服务器端发过来的 Last-Modified 最后修改时间戳发送回去,让服务器端判断客户端的页面是否是最新的:如果不是最新的,则返回新的内容;否则返回 304 告诉客户端页面是最新的,客户端就可以直接从本地加载页面,不用再次下载。
- Etag :
- 一般是一串长的数字串 ,标识文件的唯一性。
- Etag 由服务器端生成,客户端通过 If-Range 来验证资源是否修改。
如果请求报文中的 Etag没有发生变化,则应答报文的状态码为 206。发生了变化,应答报文的状态码为 200。
- If-Range:
- 由客户端发出,让服务端判断文件是否发生改变,如果未改变,服务端发送客户端缺失的部分,否则发送整个文件。If-Range用 Etag 或者 Last-Modified作为返回值。
- 必须与Range成对出现。
If-Range: <day-name>, <day> <month> <year> <hour>:<minute>:<second> GMT
If-Range: <etag>
还可以计算MD5值来验证续传的文件的正确性;
通过MySQL库来管理文件
对,没错,张三又双叒叕火了,依然是CXK那种,不过这时他的粉丝们已经不满足于下载我的照片了,他们有的把自己和张三P在一起,然后上传到服务起来,有的写满的对张三的肺腑之言,也上传到这个服务器,那么问题来了,当我们想提高用户体验时,势必要管理下这些杂乱的文件,最好也能够根据不同的要求,不同的用户将特定的文件筛选,此时MySQL就是一个很好的选择,我们要做的就是用C++封装一个MySQL类,在每次添加或删除文件时都对它进行分类管理,在查找文件时直接使用MySQL语句即可;
- 如何用C++封装一个MySQL请参考我之后的博客:
至此,一个共享HTTP服务器已经完成了,在以后的时间里,我会持续不断的扩展它的功能,让它变得美观完善,你要不要也来试试呢?
- 项目源码