Playbooks是一种简单的配置管理系统与多机器部署系统的基础,非常适合于复杂应用的部署。Playbooks可用于声明配置,可以编排有序的执行过程,甚至可以做到在多组机器间来回有序的执行指定的步骤,并且可以同步或异步的发起任务。playbooks可以称为剧本,也可以称为作业,我更习惯将其称之为作业。
系统环境:
| 服务器 | IP地址 | 操作系统 | 所需软件 |
|---|---|---|---|
| ansible主机 | 192.168.2.203 | Centos 7 64位 | ansible |
| 远程主机1 | 192.168.2.205 | Centos 7 64位 | httpd |
| 远程主机2 | 192.168.2.208 | Centos 7 64位 | httpd |
| 远程主机3 | 192.168.2.214 | Centos 7 64位 | 无 |
| 远程主机4 | 192.168.2.215 | Centos 7 64位 | 无 |
一、YAML语法简单介绍
Playbooks遵循YAML语法,是playbook的配置管理语言。YAML跟XML或JSON一样,都是一种利于人们读写的数据格式。每一个YAML文件都是从一个列表开始,列表中的每一项都是一个键值对,通常它们被称为一个“哈希”或“字典”,我们需要知道如何在YAML中编写列表和字典。
YAML基本规则:
1、区分大小写
2、使用缩进表示层级关系
3、禁止使用tab健缩进,只能使用空格键
4、缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级。
5、使用#表示注释
6、字符串可以不用引号括起来,但有特殊符号的字符串必须用引号括起来
YAML文件的第一行是“---”,声明一个文件的开始,但实际上也可以省略此行。
YAML有三种数据结构:1、列表,2、字典,3、常量。
列表中的所有成员都要以”- ”作为开头(一个横杠和一个空格)。举个例子,下面是一个水果的列表
---
- Apple
- Orange
- Strawberry
- Mango一个字典是由简单的“键: 值”的形式组成(冒号后面必须有一个空格):
name: Example Developer
job: Developer
skill: Elite字典也可以使用类似json的形式来表示:{name: Example Developer, job: Developer, skill: Elite}
YAML中提供了多种常量结构,包括:整数、浮点数、字符串、NULL、日期、布尔值、时间等。例如:
boolean:
Knows_agent: TRUE # true, True都可以
users_cvs: FALSE # false, False都可以
float:
- 3.14
- 6.856351e+5 # 可以使用科学计数法
int:
- 123
- 0b1010_0111_1010_1110 # 二进制表示
null:
parent: ~ # 使用~表示null
string:
- newline
- "he&lo x$%d" # 包含特殊字符的字符串要用双引号括起来
date:
- 2018-02-17 # 日期必须使用ISO 8601格式,即yyyy-MM-dd
datetime:
- 2018-02-17T15:02:31+08:00 # 时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区数据格式嵌套,把列表、字典和常量嵌套使用,例如:
---
name: Example Developer
job: Developer
skill: Elite
employed: True
foods:
- Apple
- Orange
languages:
ruby: Elite
python: Elite
dotnet: yes此外,ansible使用“{{ var }}”来引用变量,一个“{}”将认为是一个字典,两个“{{}}”则是变量。例如:Foo: "{{ variable }}"
二、playbook的构成
我们先来看一个官网的例子
实例1:httpd服务版本更新、配置推送
--- # 声明这是YAML文件
- hosts: webservers # 指定要操作的主机或主机组
vars: # 定义变量
http_port: 80 # 定义了一个http_port变量,http_port变量的内容是80
max_clients: 200 # 定义了一个max_clients变量,max_clients变量的内容是200
remote_user: root # 指定执行的用户
tasks: # tasks段指定要执行的任务操作
- name: ensure apache is at the latest version # 任务名称
yum: pkg=httpd state=latest # 通过yum模块确保httpd服务为最新版本
- name: write the apache config file # 任务名称
template: src=/srv/httpd.j2 dest=/etc/httpd/conf/httpd.conf # 使用httpd.j2做为配置模板,可实现配置推送
notify: # 配置有修改的话将会触发handlers,重启httpd服务
- restart apache # 重启任务的名称
- name: ensure apache is running # 任务名称
service: name=httpd state=started # 确保httpd服务是启动状态
handlers: # 跟上面的notify是配对的,由notify来进行触发
- name: restart apache # 任务名称
service: name=httpd state=restarted # 重启httpd服务这个playbook作业的功能如下:
1、确保apache是最新版本,如果不是则升级到最新版本。
2、通过httpd.j2模块来进行配置推送,如果httpd.j2和httpd.conf文件内容一样,则什么都不做;如果httpd.j2文件内容有改动,则将改动的配置更新到httpd.conf,并且重启apache。
3、确保apache是启动状态,如果不是则启动apache。
首先将httpd服务的配置拷贝到ansible本机的/svr/目录下,并命名为httpd.j2,将此文件作为httpd服务的配置模板文件。scp -P 22 [email protected]:/etc/httpd/conf/httpd.conf /srv/httpd.j2
然后运行这个playbook作业,确保两台机器httpd的版本、配置都一样。ansible-playbook httpd_config.yml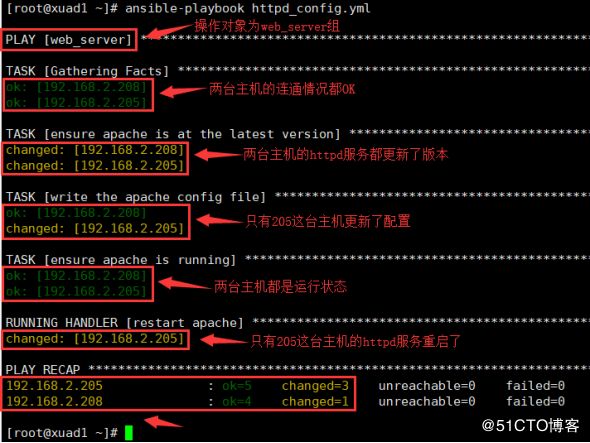
返回信息的最后两行详解:
205这台主机共修改了3个地方,更新了版本、更新了配置、重启了服务,所以是changed=3;共确认了5个地方,连通情况、版本更新、配置推送、运行状态、重启,所以ok=5。
208这台主机共修改了1个地方,更新了版本,所以是changed=1;共确认了4个地方,比205少了一个重启,所以是ok=4。
接下来我们来测试下这个playbook作业,修改httpd.j2模板文件,添加status配置内容
ExtendedStatus On
SetHandler server-status
Order deny,allow
Allow from all
然后再执行这个playbook作业,将配置推送到两台主机上ansible-playbook httpd_config.yml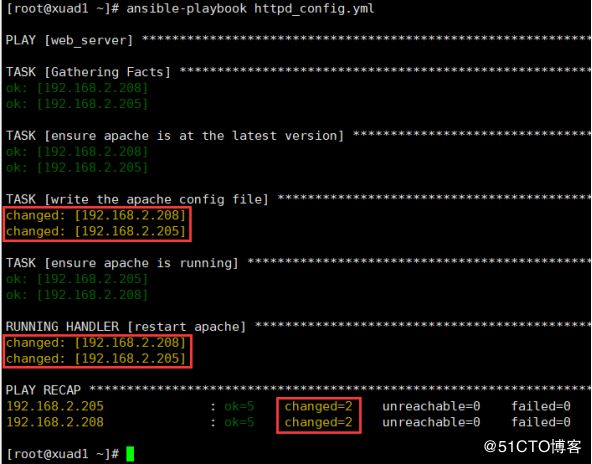
我们再到两台主机上查看一下配置文件内容,确保status配置已经推送成功。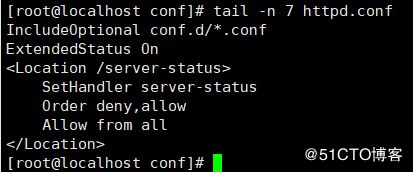
打开浏览器访问http://192.168.2.205/server-status和http://192.168.2.208/server-status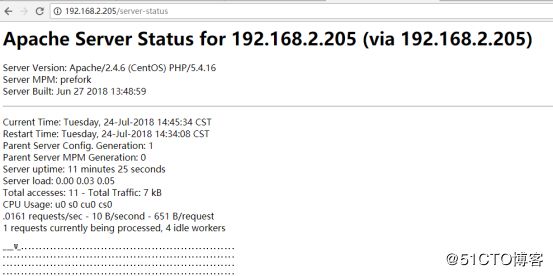
status页面访问OK,以后即使远程主机的httpd配置被人改动了,可以很方便的通过这个playbook作业轻松恢复;要修改httpd的配置,也可以通过它来更新配置,是不是很方便啊。
上面这个例子没看懂的话也不要紧,接下来我会一步一步来讲解如何写一个playbook,而且后面会有更多的实例。
上面这个playbook作业主要是由以下四部分组成:
Target section:定义将要执行 playbook 的远程主机组或主机
Variable section:定义 playbook 运行时需要使用的变量
Task section:定义将要在远程主机上执行的任务列表
Handler section:定义 task 执行完成以后需要调用的任务
即然如此,那么要写一个playbook,首先得指定需要操作的主机或主机组,以及执行playbook作业的用户。
---
- hosts: web_server # 定义要操作的主机或主机组
remote_user: root # 指定执行任务的用户也支持用sudo命令执行playbook作业
- hosts: web_server
remote_user: root
sudo: yes # 使用sudo执行任务如果要sudo到其它用户,而不是sudo到root,只需要添加sudo_user: xuad
如果sudo设置了密码的话,可在运行ansible-playbook命令时添加--ask-sudo-pass或者-k选项。建议使用sudo的话,不要设置sudo密码。
ansible-playbook httpd_config.yml --ask-sudo-pass
ansible-playbook httpd_config.yml -k需要定义变量使用vars
vars:
filename: xuad.txt # 定义了一个文件名称变量
pathname: "/etc/ansible/" # 定义了一个文件路径变量需要执行的任务通过tasks来定义
tasks:
- name: ensure apache is at the latest version # 任务名称
service: name=httpd state=started # 定义要执行的操作也可以在tasks中指定使用sudo执行命令
tasks:
- name: ensure apache is at the latest version
service: name=httpd state=started
sudo: yes # 使用sudo命令启动httpd服务
sudo_user: xuad # 指定sudo到的用户如果要中止一个playbook作业的运行,可以使用ctrl+c组合键中止运行。
playbook按从上到下的顺序执行,每个task的目标在于执行一个moudle(模块),通常是带有特定的参数来执行,在参数中可以使用变量。
可以通过{{ 变量名 }}的方式获取vars里定义的变量,如果参数太多,可以使用缩进的方式隔开连续的一行
tasks:
- name: Copy ansible inventory file to client
copy: src={{ pathname }}{{ filename }} dest={{ pathname }}{{ filename }}
owner=root group=root mode=0644 # 使用缩进的方式隔开连续的行通过前面ansible命令的熟悉后,我们知道command和shell模块不使用key=value格式,在playbook中可以这样定义
tasks:
- name: disable selinux
command: /sbin/setenforce 0 # 直接使用command命令
- name: run this command and ignore the result
shell: /usr/bin/somecommand || /bin/true # 直接使用shell命令notify和handlers组合,当上一条任务发生改动,在每一个task结束时会触发notify去执行handlers,即使有多个任务指出因为有改动需要执行handlers,notify也只会被触发一次,handlers也只会执行一次。
例如上面那个例子,当httpd配置文件发生改变会触发notify,我们在返回的信息明显看到handlers是在playbook作业的最后一步才执行。
ansible还可以通过ansible-pull从节点主机上拉取配置,具体的使用可参考官网,这里我就不讲了。
查看一个playbook是对哪些主机执行任务,可使用下面语句ansible-playbook httpd_config.yml --list-hosts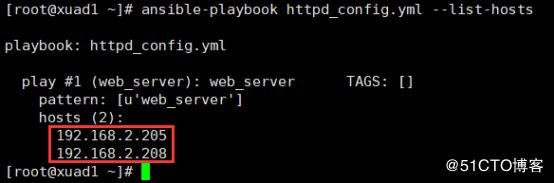
ansible默认只会创建5个并发进程,也就是说一个任务5台机器同时执行,然后再同时执行5台,直到所有机器都执行完成为止。当我们有大量的机器时,需要同时执行更多的机器,可以使用-f参数,指定并发进程数量。ansible-playbook httpd_config.yml -f 10
如果要并发执行单个任务,比如说某一个任务我需要所有机器同时执行,可以使用async和poll,async触发ansible并发执行任务,async的值是这个任务执行的最长时间,而poll是检查这个任务是否完成的频率时间。
- hosts: all
tasks:
- name: Shell script
shell: sh /tmp/script.sh
- name: run updatedb
command: /usr/bin/updatedb
async: 300
poll: 10上面这个例子shell模块是同时在5台机器上执行,而command模块是同时在所有机器上执行,并且超时时间是300秒,检查任务完成的频率时间是10秒。
如果playbook是放到后台去执行,后台执行加-B参数,那就不需要检查了,可以把poll设置为0。如果一个任务需要运行很长时间,需要一直等待这个任务完成,不需要设置超时时间,可以把async的值设置为0。
三、条件选择语句
(1)通过when语句实现条件选择
有时我们可能希望某一个任务在满足一个条件的情况下执行,如果不满足这个条件就不执行,可以使用when语句,可以按下面方式定义
tasks:
- name: "Shutdown RedHat flavored systems"
command: /sbin/shutdown -t now
when: ansible_os_family == "RedHat" # 当节点主机的操作系统是redhat时关机setup模块获取到的主机系统信息可以直接在playbook里面调用,查看远程节点主机是什么系统可使用下面语句ansible 192.168.2.205 -m setup -a 'filter=ansible_os_family'
如果不满足此条件可以用not,有多个条件需要同时满足可以用and,满足其中一个条件用or。
when: not ansible_os_family == "RedHat"
when: ansible_os_family == "RedHat" and ansible_os_family == "Debian"
when: ansible_os_family == "RedHat" or ansible_os_family == "Debian"也可以对数值变量进行判断,如下
when: ansible_lsb.major_release|int >= 6
when: ansible_lsb.major_release|int != 6我们都知道在shell中判断一条命令执行成功与否,可以echo $?,0表示成功,1表示失败。在playbook中我们可以使用register语句来判断一条命令执行成功与否,成功返回succeeded或者success,失败返回failed,然后将返回信息保存在一个变量里,通过这个变量内容来做相应的处理。
实例2:判断httpd服务是否running状态,是则打印“httpd is running, OK”,不是则打印“httpd is faild, Faild”
- hosts: web_server
remote_user: root
tasks:
- name: httpd status
shell: systemctl status httpd | grep running
register: status_result
ignore_errors: True
- name: Httpd is Running
debug: msg="httpd is running, OK"
when: status_result is success
- name: Httpd is Faild
debug: msg="httpd is faild, Faild"
when: status_result is failed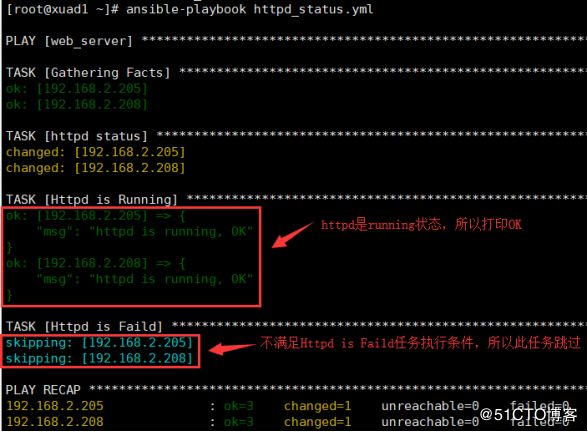
register需要配置使用ignore_errors,并且设置成True,否则如果任务执行失败,即echo $0不为0,则会导致程序中止,后面的任务不会执行。
dedug模块有两个参数,msg和fail,msg就是打印信息,而当fail=yes时,会发送失败通知给ansible,然后ansible会停止运行任务。debug: msg="OS Family {{ ansible_os_family }} is not supported" fail=yes
不管是在inventory中还是playbooks中定义的变量都可以给when使用,下面的例子是基于“键: 值”来决定一个任务是否被执行
vars:
xuad: true
tasks:
- shell: sh /tmp/abcd.sh
when: xuad
tasks:
- shell: sh /tmp/efgh.sh
when: not xuad如果一个变量不存在,可以使用defined跳过执行此任务
tasks:
- shell: sh /tmp/abcd.sh # 此任务不会执行
when: foo is defined
- shell: sh /tmp/efgh.sh # 此任务会执行
when: bar is not defined还可以同时对多个变量进行判断,可通过items定义多个变量,然后循环代入到任务当中,通过when还判断变量内容,符合条件的变量才会代入到任务中执行。关于items的使用,后面循环内容会进行讲解。
实例3:对多个变量进行判断,符合条件的才会打印变量内容
- hosts: 192.168.2.205
remote_user: root
tasks:
- command: echo {{ item }}
with_items: [ 0, 2, 4, 6, 8, 10 ]
when: item > 5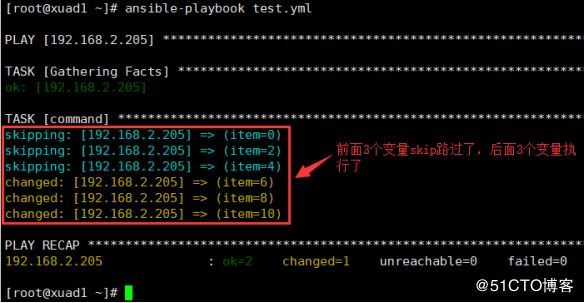
when语句还可以应用在tasks的includes上面,如下
- include: tasks/xuad.yml
when: "'reticulating splines' in output"when语句也可以应用在roles上面,如下
- hosts: web_server
roles:
- { role: debian_stock_config, when: ansible_os_family == 'Debian' }关于roles(角色)部分,后面会进行讲解,这里只需要知道如何在roles上面定义when即可。
(2)通过变量实现条件选择
通过setup系统信息息变量获取变量文件,再通过获取变量文件里定义的变量实现条件选择
实例4:不同的系统版本主机获取对应的变量,实现条件选择
首先创建一个变量文件RedHat.yml,内容如下:
apache: httpd
somethingelse: 42再创建一个playbook文件httpd_running.yml,内容如下:
- hosts: all
remote_user: root
vars_files:
- [ "/root/{{ ansible_os_family }}.yml", "vars/os_defaults.yml" ]
tasks:
- name: make sure apache is running
service: name={{ apache }} state=started此实例是不同的系统版本的主机获取到自己的apache变量。先通过ansible_os_family变量获取到RedHat.yml文件或者其它系统版本的变量文件,再通过RedHat.yml获取apache变量,如果获取不到,就通过os_defaults.yml默认的变量文件获取apache变量,然后将apache变量内容代入到service模块里,从而实现确保httpd服务是运行状态。
通过with_first_found实现文件匹配,第一个文件匹配不到,才会去匹配第二个文件,依此类推。
- name: template a file
template: src={{ item }} dest=/etc/myapp/foo.conf
with_first_found:
- files:
- {{ ansible_distribution }}.conf
- default.conf
paths:
- search_location_one/somedir/
- /opt/other_location/somedir/先通过{{ ansible_distribution }}.conf文件匹配,不同的系统版本主机会匹配到自己的配置文件,匹配到的话就推送这个文件的配置;匹配不到的主机会推送default.conf文件的配置。
四、变量的定义和引用
变量可以在四个地方进行定义:1、在Inventory中定义变量,这个在我上一篇博文已经讲过,这里不再重复。2、在playbook中定义变量。3、在文件中定义变量。4、在role中定义变量。
通过前面的一些例子,大家应该已经发现在playbook中定义变量其实很简单
vars:
http_port: 80引用变量也很简单,只需使用{{}}两个大括号即可,例如:{{ http_port }}
下面来看一个例子,我们现在要批量更新一个应用,那首先是将更新文件打包压缩,然后将更新包分发到各个远程主机上,然后再将更新包解压到应用所在目录,最后重启应用。我们有个以当前日期为名称的yml_20180730.tar.gz压缩包,此压缩包包含两个文件docker.yml和nginx.yml,那我现在需要将它分发到web_server组里所有主机的/tmp目录下并解压,如下实例。
实例5:将tar.gz格式的压缩包拷贝到远程主机上并解压
- name: copy and unzip file
hosts: web_server
remote_user: root
vars:
file: yml_{{ansible_date_time.year}}{{ansible_date_time.month}}{{ansible_date_time.day}}.tar.gz
tasks:
- name: 分发更新包
copy: src=/etc/ansible/{{ file }} dest=/tmp
- name: 解压更新包
shell: tar -zxvf /tmp/{{ file }} -C /tmpansible-playbook tarcopy.yml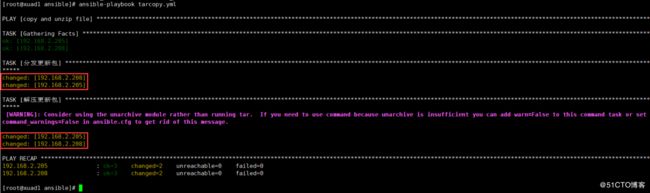
ansible web_server -m shell -a "ls -lh /tmp"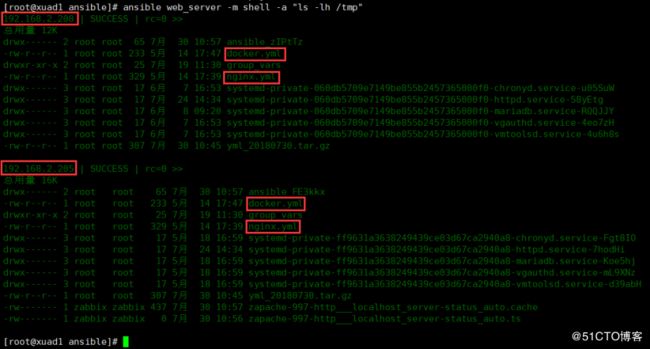
通过facts获取系统相关的变量,也就是前面所说的setup模块,例如:获取远程系统的当前日期{{ ansible_date_time.date }}
在playbook中也可以关闭facts数据的获取,这样有利于加快ansible操作大批量服务器的速度
- hosts: all
gather_facts: no要想指定获取哪台主机的系统变量,可以按如下方式引用{{ hostvars['192.168.2.205']['ansible_os_family'] }}
在文件中定义变量也很简单,我们首先写一个变量文件vars.yml
somevar: somevalue
password: magic在playbook中可以按以下方式引用,使用vars_files来获取文件中的变量
- hosts: all
remote_user: root
vars:
favcolor: blue
vars_files:
- /vars/vars.yml
tasks:
- name: this is just a placeholder
command: /bin/echo foo在命令行中传递变量,使用--extra-vars,例如我在playbook中引用了两个变量,如下
- hosts: '{{ hosts }}'
remote_user: '{{ user }}'
tasks:在执行playbook的命令中可以按如下方式传递变量到playbook中ansible-playbook release.yml --extra-vars "hosts=web_server user=root"
也可以传递json格式的变量--extra-vars '{"pacman":"mrs","ghosts":["inky","pinky","clyde","sue"]}'
使用“@”传递json文件--extra-vars "@some_file.json"
在roles中可以按如下方式定义变量
roles:
- { role: app_user, name: Ian }
- { role: app_user, name: Terry }如果在不同的地方定义了一个相同的变量,获取变量的优先级如下:
extra vars (在命令行中使用 -e)优先级最高
然后是在inventory中定义的连接变量(比如ansible_ssh_user)
接着是大多数的其它变量(命令行转换,play中的变量,included的变量,role中的变量等)
然后是在inventory定义的其它变量
然后是由系统发现的facts
然后是 "role默认变量", 这个是最默认的值,很容易丧失优先权
五、循环语句
使用with_items定义多个变量,以循环的方式引用变量
实例6:copy两个文件到远程主机的/tmp下
- name: copy file
hosts: web_server
remote_user: root
tasks:
- name: cp file
copy: src=/etc/ansible/{{ item }} dest=/tmp
with_items:
- ansible.cfg
- hostsansible-playbook copyf.yml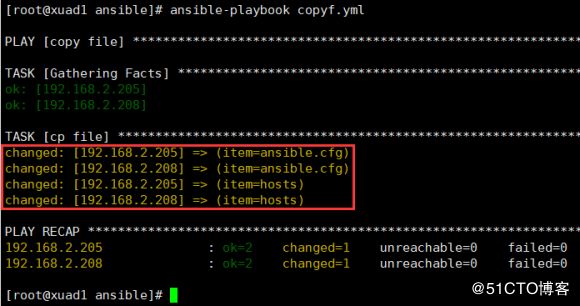
ansible web_server -m shell -a "ls /tmp"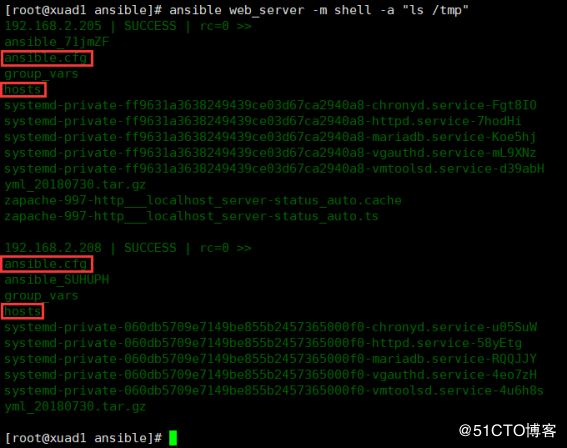
同时引用两个变量,可以按如下方式定义
- name: add several users
user: name={{ item.name }} state=present groups={{ item.groups }}
with_items:
- { name: 'testuser1', groups: 'wheel' }
- { name: 'testuser2', groups: 'root' }使用with_nested实现循环嵌套,按如下方式定义
注:item[0]循环alice和bob两个变量,item[1]循环clientdb、employeedb和providerdb三个变量,以下例子是实现在三个数据库上创建两个用户。
- name: give users access to multiple databases
mysql_user: name={{ item[0] }} priv={{ item[1] }}.*:ALL append_privs=yes password=foo
with_nested:
- [ 'alice', 'bob' ]
- [ 'clientdb', 'employeedb', 'providerdb' ]使用with_dict实现对哈希表循环,按如下方式定义
users:
alice:
name: Alice Appleworth
telephone: 123-456-7890
bob:
name: Bob Bananarama
telephone: 987-654-3210
tasks:
- name: Print phone records
debug: msg="User {{ item.key }} is {{ item.value.name }} ({{ item.value.telephone }})"
with_dict: "{{users}}"使用with_fileglob实现对文件列表进行循环,如下实例
实例7:copy一个目录下的所有文件到远程主机上
- hosts: web_server
remote_user: root
tasks:
- name: 创建目录
file: dest=/tmp/ansible state=directory
- name: 拷贝目录下的所有文件
copy: src={{ item }} dest=/tmp/ansible/ owner=root mode=600
with_fileglob:
- /etc/ansible/*ansible-playbook files.yml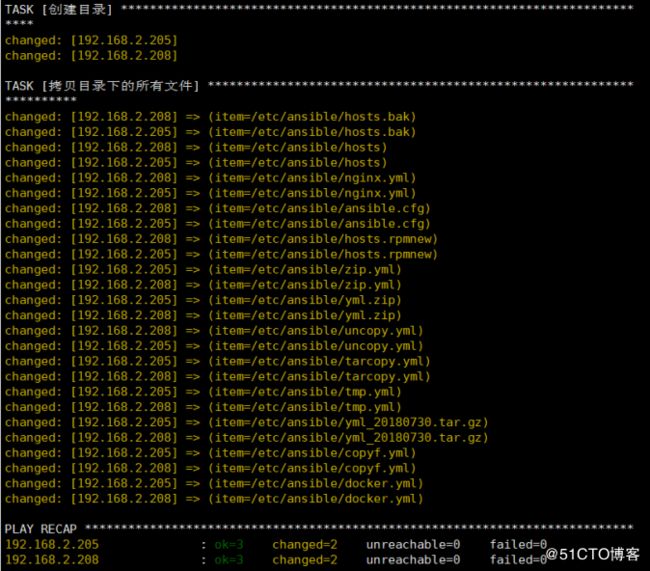
使用with_together实现并行循环,一次获取多个变量
vars:
alpha: [ 'a', 'b', 'c', 'd' ]
numbers: [ 1, 2, 3, 4 ]
tasks:
- debug: msg="{{ item.0 }} and {{ item.1 }}"
with_together:
- "{{alpha}}"
- "{{numbers}}"使用with_subelements实现对子元素使用循环,假设我们有一份按以下方式定义的文件
users:
- name: alice
authorized:
- /tmp/alice/onekey.pub
- /tmp/alice/twokey.pub
mysql:
password: mysql-password
hosts:
- "%"
- "127.0.0.1"
- "::1"
- "localhost"
privs:
- "*.*:SELECT"
- "DB1.*:ALL"
- name: bob
authorized:
- /tmp/bob/id_rsa.pub
mysql:
password: other-mysql-password
hosts:
- "db1"
privs:
- "*.*:SELECT"
- "DB2.*:ALL"要获取以上文件里定义的数据,可以按以下方式引用变量
- user: name={{ item.name }} state=present generate_ssh_key=yes
with_items: "{{users}}"
- authorized_key: "user={{ item.0.name }} key='{{ lookup('file', item.1) }}'"
with_subelements:
- users
- authorized以嵌套的方式获取变量,如下
- name: Setup MySQL users
mysql_user: name={{ item.0.user }} password={{ item.0.mysql.password }} host={{ item.1 }} priv={{ item.0.mysql.privs | join('/') }}
with_subelements:
- users
- mysql.hosts使用with_sequence对整数序列使用循环,如下
- hosts: all
tasks:
# create groups
- group: name=evens state=present
- group: name=odds state=present
# create some test users
- user: name={{ item }} state=present groups=evens
with_sequence: start=0 end=32 format=testuser%02x
# create a series of directories with even numbers for some reason
- file: dest=/var/stuff/{{ item }} state=directory
with_sequence: start=4 end=16 stride=2
# a simpler way to use the sequence plugin
# create 4 groups
- group: name=group{{ item }} state=present
with_sequence: count=4使用with_random_choice实现随机选择一个变量
- debug: msg={{ item }}
with_random_choice:
- "go through the door"
- "drink from the goblet"
- "press the red button"
- "do nothing"使用Do-Until循环,实现循环执行某个任务直到指定的条件成立后停止
- action: shell /usr/bin/foo
register: result
until: result.stdout.find("all systems go") != -1
retries: 5
delay: 10上面的例子递归运行shell模块,直到运行结果中的stdout输出中包含“all systems go”字符串时停止运行,或者该任务按照10秒的延迟重试超过5次时停止运行。
六、角色(Roles)使用
ansible支持将一个playbook进行拆解,比如将vars、tasks和需要操作的主机或执行的用户分别写在不同的文件里,然后通过一个简单的playbook文件去调用这些文件,那么最好的办法就是使用角色(roles),也可以将roles称之为各个项目的集合。
一个角色必须包含如下目录:
role_name/
files/:存储由copy或script等模块调用的文件;
tasks/:此目录中至少应该有一个名为main.yml的文件,用于定义各个task;其它的文件需要由main.yml进行"包含"调用;
handlers/:此目录中至少应该有一个名为main.yml的文件,用于定义各个handler;其它的文件需要由main.yml进行"包含"调用;
vars/:此目录中至少应该有一个名为main.yml的文件,用于定义各个variable;其它的文件需要由main.yml进行“包含”调用;
templates/:存储由template模块调用的模板文本;
meta/:此目录中至少应该有一个名为main.yml的文件,定义当前角色的特殊设定及其依赖关系;其它的文件需要由main.yml进行"包含"调用;
default/:此目录中至少应该有一个名为main.yml的文件,用于设定默认变量;
实例8:yum方式批量安装部署mysql
首先创建ssh-key授权,将公钥文件copy到两台主机上
ssh-copy-id 192.168.2.214
ssh-copy-id 192.168.2.215然后hosts文件添加如下内容
[db_server]
192.168.2.214
192.168.2.215确定2台主机都能正常连接ansible db_server -m ping
建立mysql项目的角色目录
cd /etc/ansible/roles/
mkdir -p mysql/{default,files,handlers,meta,tasks,templates,vars}由于我们修改了mysql的数据存储路径、日志路径和socket文件路径,所以需要关闭selinux,mysql才能正常启动。
创建关闭selinux的配置模板文件,将此模板文件放到/etc/ansible/roles/mysql/templates目录下
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
#SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
#SELINUXTYPE=targeted 创建mysql的配置模板文件,将此模板文件放到/etc/ansible/roles/mysql/templates目录下
[mysqld]
datadir=/data/mysql/data
socket=/data/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd
[mysqld_safe]
log-error=/data/mysql/mariadb.log
pid-file=/data/mysql/mariadb.pid
socket=/data/mysql/mysql.sock
#
# include all files from the config directory
#
!includedir /etc/my.cnf.d创建调用roles的playbook作业vim mysql.yml
- hosts: db_server
remote_user: root
roles:
- mysql创建关闭selinux的tasks文件vim mysql/tasks/selinux.yml
- name: Modify the configuration file for SELinux
template: src=config.j2 dest=/etc/selinux/config
- name: close selinux
shell: setenforce 0创建变量vars定义文件vim mysql/vars/main.yml
mysql_name: "mariadb"
mysql_path: "/data/mysql"
mysql_port: 3306
root_pass: "123456"yum安装mariadb需要安装mariadb-devel、mariadb和mariadb-server三个包,那么我们现在来创建tasks文件vim mysql/tasks/mysql_install.yml
- name: ensure {{ mysql_name }}-devel is at the latest version
yum: pkg={{ mysql_name}}-devel state=latest
- name: ensure {{ mysql_name }} is at the latest version
yum: pkg={{ mysql_name }} state=latest
- name: ensure {{ mysql_name }}-server is at the latest version
yum: pkg={{ mysql_name }}-server state=latest
- name: Create a data directory
file: dest={{ mysql_path }}/data mode=755 owner=mysql group=mysql state=directory
- name: write the mysql config file
template: src=my.cnf.j2 dest=/etc/my.cnf
notify:
- restart mysql
- name: ensure mysql is running
service: name={{ mysql_name }} state=started enabled=yes
- name: Creating a soft link file
file: src={{ mysql_path }}/mysql.sock dest=/var/lib/mysql/mysql.sock state=link
- name: Setting the root password
shell: mysqladmin -u root -h localhost password {{ root_pass }}创建tasks的main.yml文件vim mysql/tasks/main.yml
- include: selinux.yml
- include: mysql_install.yml创建handlers文件vim mysql/handlers/main.yml
- name: restart mysql
service: name=mariadb state=restarted最终mysql的角色路径如下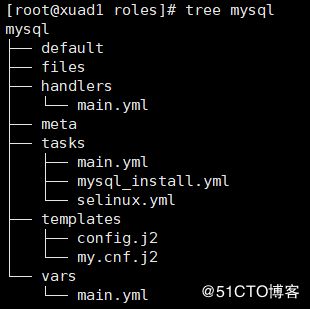
运行mysql.yml作业ansible-playbook mysql.yml
登陆到远程主机上看一下结果吧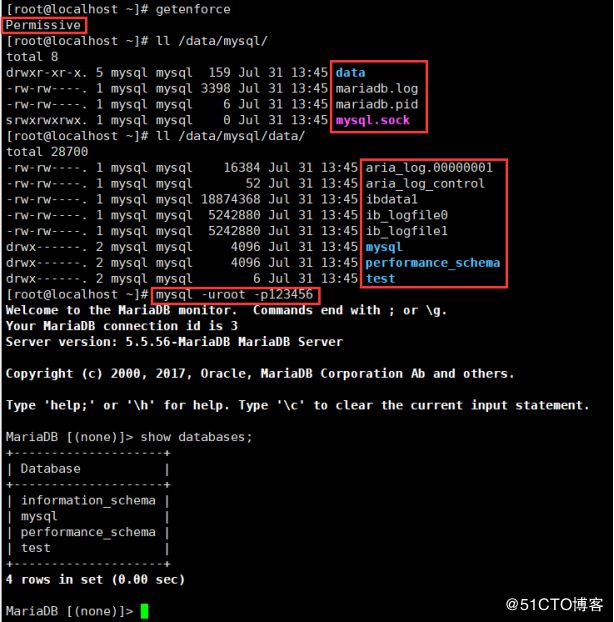
七、playbook实例
实例9:通过unarchive将tar.gz的压缩包解压到远程主机的指定目录下
前面的实例5是通过tar命令解压的,所以会抛出一个警告,意思是建议使用unarchive来完成此任务。
- name: copy and unzip file
hosts: web_server
remote_user: root
tasks:
- name: copy your folder from control machine to remote host
unarchive: src=yml_{{ansible_date_time.year}}{{ansible_date_time.month}}{{ansible_date_time.day}}.tar.gz dest=/tmpansible-playbook untar.yml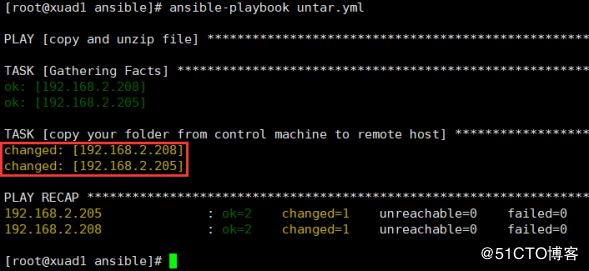
实例10:批量启动、重启、停止httpd服务
注:tags可实现单独运行一个playbook作业中的指定的任务
- hosts: web_server
remote_user: root
tasks:
- name: start httpd
service: name=httpd state=started
tags: start_httpd
- name: stop httpd
service: name=httpd state=stopped
tags: stop_httpd
- name: restart httpd
service: name=httpd state=restarted
tags: restart_httpd例如我现在重启httpd服务ansible-playbook httpd.yml -t restart_httpd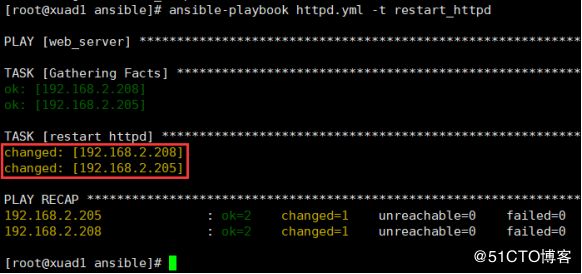
实例11:批量创建用户
首先通过以下方式生成sha-512算法密码,例如密码为xuad123456python -c "from passlib.hash import sha512_crypt; import getpass; print sha512_crypt.encrypt(getpass.getpass())"
然后创建playbook作业,生成的加密串贴到password=””里
- hosts: web_server
remote_user: root
tasks:
- name: 创建用户
user: name={{ item }} password="$6$rounds=656000$O//XUuLIX35/oB2V$yuLC/9TUUvCBb/aCtN0N.xhjBA1ui3t0kPcK2PWP0Hp0eLuThZzx904v3ZoOhAxj/pS6GIHM4RudAzNfnGbxq0"
with_items:
- xiaozh
- wangbs
- yangdlansible-playbook user_add.yml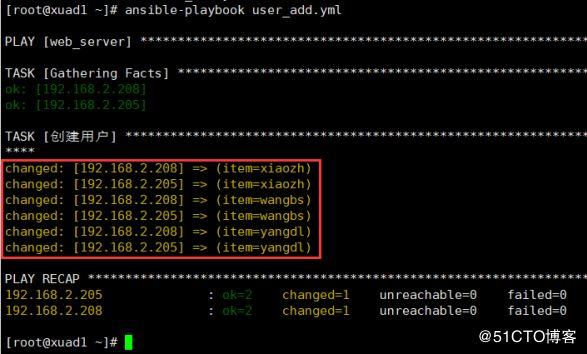
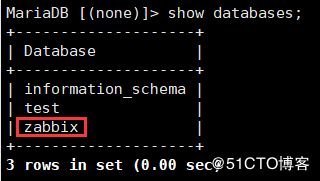
实例12:批量初始化zabbix数据库
首先把zabbix的三个sql文件放到/etc/ansible/roles/mysql/files目录下
编写初始化zabbix数据库的playbook作业vim mysql_add.yml
- hosts: db_server
remote_user: root
vars_files:
- /etc/ansible/roles/mysql/vars/main.yml
vars:
zauser: zabbix_user
user_pass: "user123456"
tasks:
- name: 安装MySQL-python模块
yum: pkg=MySQL-python state=latest
- name: 创建zabbix数据库
mysql_db: login_user=root login_password={{ root_pass }} name=zabbix encoding=utf8 state=present
- name: 创建zabbix用户
mysql_user: login_user=root login_password={{ root_pass }} name={{ zauser }} password={{ user_pass }} priv='zabbix.*:ALL' state=present
- name: 分发sql脚本
copy: src={{ item }} dest=/tmp/
with_fileglob:
- /etc/ansible/roles/mysql/files/*
- name: 导入sql脚本到zabbix数据库
mysql_db: login_user=root login_password={{ root_pass }} name=zabbix state=import target=/tmp/{{ item }}
with_items:
- schema.sql
- images.sql
- data.sqlansible-playbook mysql_add.yml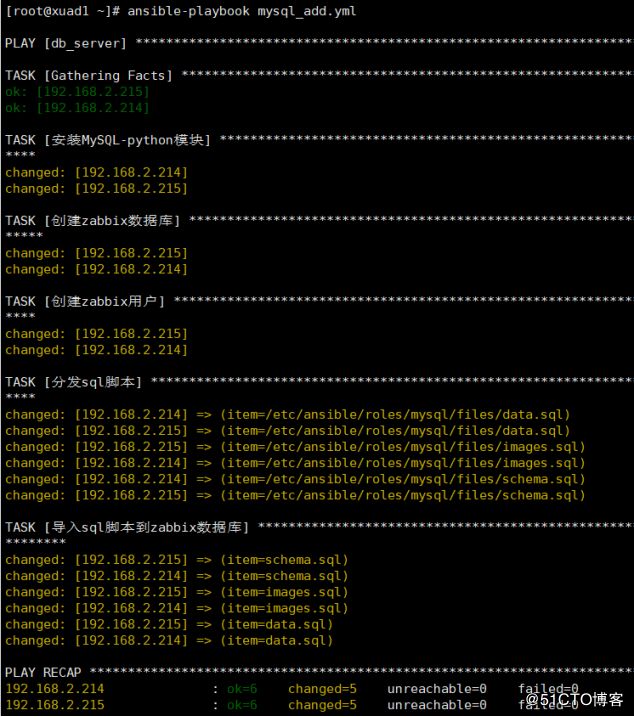
可自行登陆到远程主机上进行测试