HDFS高级功能
安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,让NameNode得到块的位置信息,并对每一个文件对应的数据块副本进行统计,当最小副本条件满足时HDFS自动离开安全模式。如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求)
假设我们设置的副本数即(参数dfs.replication是5),那么在datanode上应该有5个副本存在,假设只存在3个副本那么比例就是3/5=0.6,默认的最小的副本率是0.999.因此系统会自动复制副本到其他的dataNode,使得副本率不小于0.99.
安全模式的相关命令:
查看当前状态
1 |
hdfs dfsadmin -safemode get |
进入安全模式
1 |
hdfs dfsadmin -safemode enter |
强制离开安全模式
1 |
hdfs dfsadmin -safemode leave |
一直等待直到安全模式结束
1 |
hdfs dfsadmin -safemode wait |
Web查看启动过程 端口50070

回收站
HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户通过Shell删除的文件/目录,在系统回收站中都一个周期,也就是当系统回收站中的文件/目录在一段时间之后没有被用户恢复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。在HDFS内部的具体实现就是在NameNode中开启了一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的所有文件/目录,对于已经超过生命周期的文件/目录,这个线程就会自动的删除它们,不过这个管理的粒度很大。另外,用户也可以手动清空回收站,清空回收站的操作和删除普通的文件目录是一样的,只不过HDFS会自动检测这个文件目录是不是回收站,如果是,HDFS当然不会再把它放入用户的回收站中了。
设置trashtrash选项
hadoop中的trash选项默认关闭,如果生效,需要更改conf中的core-site.xml
1 |
<property> |
执行 Hadoop fs -rm -f /文件路径,将文件删除时,文件并不是直接消失在系统中,而是被从当前目录move到了所属用户的回收站中。保留时间(1440分钟=24小时),24小时内,用户可以去回收站找到这个文件,并且恢复它。24小时过后,系统会自动删除这个文件,于是这个文件彻底被删除了。
fs.trash.checkpoint.interval则是指的是检查垃圾回收的检查间隔,应该是小于或者等于fs.trash.checkpoint.。想要恢复数据只需要把数据移动到要恢复的数据即可。
快照
Hadoop 2.x HDFS新特性
基于某时间点的数据的备份复制.利用快照,可以针对基本的目录或者整个文件系统,让HDFS在数据损坏时恢复到过去一个正确的时间点,快照比较常见的应用场景书数据备份,以防止一些用户错误或者灾难.
快照功能默认禁用,开启或者禁用快照功能需要针对目录进行操作命令如下
1 |
hdfs dfsadmin -allowSnapshot |
开启快照
1 |
[hadoop@datanode1 ~]$ hdfs dfsadmin -allowSnapshot /input |
创建快照
1 |
hdfs dfs -createSnapshot /input input_2018-12-19 |
上传文件
1 |
[hadoop@datanode1 ~]$ hadoop fs -put bigtable /input |
创建快照
1 |
[hadoop@datanode1 ~]$ hdfs dfs -createSnapshot /input input_2018-12-19_2 |
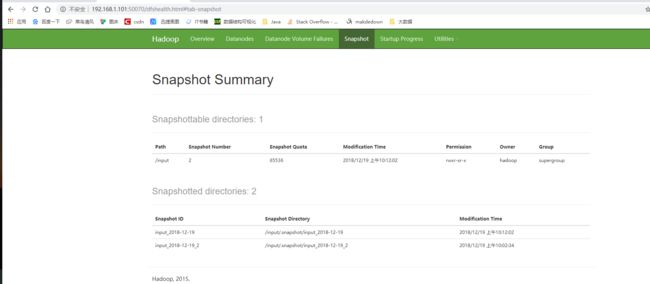
对比快照
1 |
[hadoop@datanode1 ~]$ hdfs snapshotDiff /input input_2018-12-19 input_2018-12-19_2 |
Web查看
恢复数据
恢复数据的方法就是拷贝
1 |
[hadoop@datanode1 ~]$ hdfs dfs -cp /input/.snapshot/input_2018-12-19 /input |
配额
- setQuota 针对HDFS中的某个目录设置文件和目录数量之和的最大值
1 |
[hadoop@datanode1 ~]$ hdfs dfsadmin -setQuota 5 /input # 该目录下目录数之和不超过5 |
- setSoaceQuota
1 |
[hadoop@datanode1 ~]$ hdfs dfsadmin -setSpaceQuota 134217728 /input #设置input的存储空间为128M |
- 清除配额命令
1 |
[hadoop@datanode1 ~]$ hdfs dfsadmin -clrQuota /input |
联邦
Federation即为“联邦”,该特性允许一个HDFS集群中存在多个NameNode同时对外提供服务,这些NameNode分管一部分目录(水平切分),彼此之间相互隔离,但共享底层的DataNode存储资源。
【单机namenode的瓶颈大约是在4000台集群,而后则需要使用联邦机制】
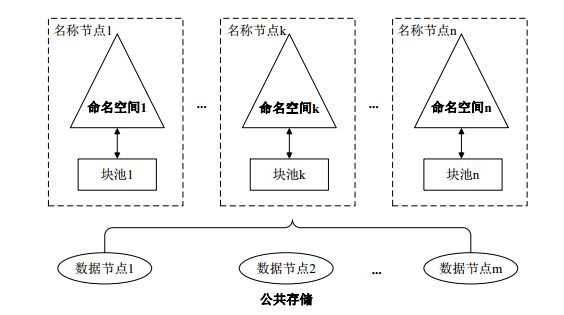
什么是Federation机制
Federation是指HDFS集群可使用多个独立的NameSpace(NameNode节点管理)来满足HDFS命名空间的水平扩展 ,这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。
NameSpace之间在逻辑上是完全相互独立的(即任意两个NameSpace可以有完全相同的文件名)。在物理上可以完全独立(每个NameNode节点管理不同的DataNode)也可以有联系(共享存储节点DataNode)。一个NameNode节点只能管理一个Namespace
Federation机制解决单NameNode存在的以下几个问题
(1)HDFS集群扩展性。每个NameNode分管一部分namespace,相当于namenode是一个分布式的。
(2)性能更高效。多个NameNode同时对外提供服务,提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
(4)Federation良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作。
Federation是简单鲁棒的设计
鲁棒性(健壮和强壮):在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃
由于联盟中各个Namenode之间是相互独立的:Federation整个核心设计大部分改变是在Datanode、Config和Tools,而Namenode本身的改动非常少,这样Namenode原先的鲁棒性不会受到影响。比分布式的Namenode简单,虽然扩展性比真正的分布式的Namenode要小些,但是可以迅速满足需求。
另外一个原因是Federation良好的向后兼容性,可以无缝的支持目前单Namenode架构中的配置。已有的单Namenode的部署配置不需要任何改变就可以继续工作。
Federation不足之处
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单namenode/namespace看,仍然存在单点故障。因此 Federation中每个namenode配置成HA高可用集群,以便主namenode挂掉一下,用于快速恢复服务。
HA
通常一个集群只有一个NameNode,所有的元数据由唯一的NameNode负责管理,如果机器或者进程变得不可用,整个集群都会无法工作。知道NameNode恢复工作为止。影响集群的可用性,HDFS高可用通过提供同一集群中运行两个NameNode的方法来解决问题,一台保持活跃(Active)状态对外提供服务,一台处于备用(Standby)状态,两个节点保持数据同步。为了实时同步两个NameNode上的元数据需要一个共享存储系统,可以是NFS QJM 或者Zookeeper,Active的NameNode将共享数据写入到共享系统中去,而Standby监听该系统与ActiveNameNode基本保持一致因此在一个NameNode不能对外提供服务的情况下,可以快速故障转移到另外一个NameNode。
