【笔记】YOLOv3训练自己的数据集(2)——训练和测试训练效果
环境:Ubuntu18.04 GTX1080
文章目录
- 3 训练
- 3.1 修改配置文件
- 3.1.1 修改类别名称显示文件`darknet/data/voc.names`
- 3.1.2 修改数据文件`darknet/cfg/voc.data`
- 3.1.3 修改配置文件 `darknet/cfg/yolov3-voc.cfg`
- 3.2 开始训练
- 3.2.1 从预训练模型开始训练
- 3.2.2 从头开始训练
- 3.2.3 控制台输出解释
- 4 训练结果测试
- 【未完待续...】
3 训练
3.1 修改配置文件
3.1.1 修改类别名称显示文件darknet/data/voc.names
这里存放的是要检测的类别的名称,比如gun,就把原来的内容删除掉,键入gun,即可,如果是多个类别,以回车分割各个类别。
cd darknet
cp data/voc.names data/voc.names.bak #备份原文件
gedit data/voc.names

3.1.2 修改数据文件darknet/cfg/voc.data
cd darknet
cp cfg/voc.data cfg/voc.data.bak #备份原文件
gedit cfg/voc.data
classes= 1 /*类别数*/
train = /home/xxx/train.txt /*voc2yolo.py生成的train.txt所在路径,建议使用绝对路径*/
valid =/home/xxx/2007_test.txt /*voc2yolo.py生成的2007_test.txt所在路径,建议使用绝对路径*/
names = cfg/voc.names /*3.1中修改的voc.names所在路径*/
backup = backup /*Darknet训练结果的输出路径,一定要有,不然没有输出。*/
3.1.3 修改配置文件 darknet/cfg/yolov3-voc.cfg
下面是yolov3-voc.cfg内容简介。
[net]
# Testing /*测试配置标签*/
# batch=1 /*测试时批次大小*/
# subdivisions=1
# Training /*训练配置标签*/
batch=64 /*训练时批次大小*/
subdivisions=16 /*训练时,每次参与训练的图片数,是batch/subdivisions*/
width=416 /*图片宽度*/
height=416 /*图片高度*/
channels=3/*图片通道数*/
momentum=0.9/*动量,反向传播用*/
decay=0.0005/*衰减率,反向传播用*/
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 50200
policy=steps
steps=40000,45000
scales=.1,.1
/**下面是每层的网络配置*/
[convolutional]/*这一层是卷积层*/
batch_normalize=1/*使用批量归一化*/
filters=32/*滤波器个数*/
size=3/*滤波器尺寸*/
stride=1/*滤波器步长*/
pad=1/*填充*/
activation=leaky/*激活函数是 leaky relu*/
...
[shortcut]/*这个是仿ResNet的shortcut层*/
from=-3
activation=linear
...
[convolutional]/*yolo层之前的一个卷积层,比较重要*/
size=1
stride=1
pad=1
filters=75 /*3x(类别数+4+1)*/
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20 # 类别数
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1 /*如果显存很小,将random设置为0,关闭多尺度训练*/
cd darknet
cp cfg/yolov3-voc.cfg cfg/yolov3-voc.cfg.bak #备份原配置文件
gedit cfg/yolov3-voc.cfg
要修改的地方有那么几处
①如果Training配置被注释,那么要取消Training的注释,并且把Testing注释。
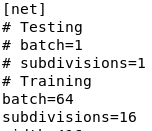
②如果你想修改图片的大小也可以,但是要注意图像的宽高都要是32的倍数,因为Darknet53最后的特征层的宽高是原图的1/32。不过一般情况下,不需要更改。
![]()
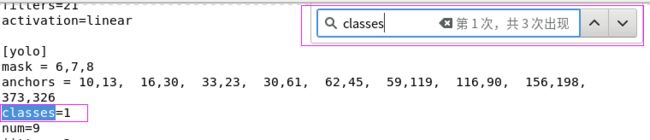
③类别数修改为自己想要的检测的类别数,比如这里仅仅检测枪支,类别数classes=1。
使用gedit打开yolov3-voc.cfg,按下Ctrl+F,右上角输入框里输入classes,定位到classes出现的三个位置,统统改为1。
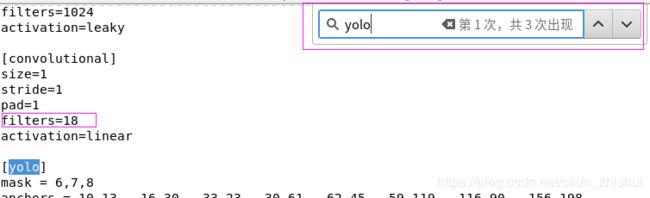
④修改filters,只需要修改[yolo]层前一个[convolutional]里的filters,结果计算公式是filters=3x(类别数+4+1),这里就是3x(1+4+1)=18。
使用gedit打开yolov3-voc.cfg,按下Ctrl+F,右上角输入框里输入yolo,定位到yolo出现的三个位置,找到上面第一个出现的[convolutional]的filters,统统改为18。
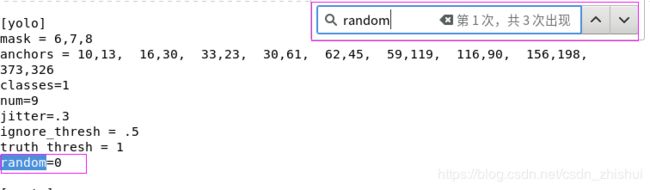
⑤如果显存太小,可以把[yolo]层的random从1改为0,关闭多尺度训练,使得训练能继续下去。
方法同③,使用gedit打开yolov3-voc.cfg,按下Ctrl+F,右上角输入框里输入random,定位到random出现的三个位置,统统改为0。
3.2 开始训练
训练时可以在预训练模型上继续训练,也可以从头开始训练。
3.2.1 从预训练模型开始训练
cd darknet
wget https://pjreddie.com/media/files/darknet53.conv.74
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpu 0 | tee train_yolov3.log
3.2.2 从头开始训练
cd darknet
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg -gpu 0 | tee train_yolov3.log
这里把训练日志保存到darknet/train_yolov3.log,以便后面分析训练过程,如可视化loss曲线等。
3.2.3 控制台输出解释
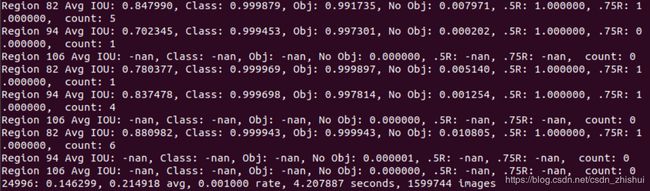
①每组包含三条信息,分别是:Region 82,Region 94,Region 106,三个尺度上预测不同大小的框,82卷积层为最大的预测尺度,使用较大的mask,但是可以预测出较小的物体,94卷积层为中间的预测尺度,使用中等的mask,106卷积层为最小的预测尺度,使用较小的mask,可以预测出较大的物体。
②Region Avg IOU表征在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比;Class表征标注物体分类的正确率,期望该值趋近于1;Obj越接近1越好;No Obj期望该值越来越小,但不为零;count是所有的当前subdivision图片中包含正样本的图片的数量。
③最后一行是每个batch(本文中是64)处理完成后都会输出的训练信息。
24996:第24996组batch。
0.146299:该批次内的总损失
0.214918 avg:平均损失
0.001000 rate:当前的学习率
4.207787 seconds: 当前batch训练所花的时间
1599744 images : 目前为止参与训练的图片总数 = 24996 * 64
等到avg降到1e-1~1e-2,Classes,Obj等也都接近于1时,就可以停止训练了。
4 训练结果测试
训练结束之后
①进入3.1.2中配置的voc.data下指定的backup目录,把yolov3-voc_xxx.weights中选择一个xxx最大的拷贝到darknet目录下,比如是yolov3-voc_20000.weights。
②准备一张测试图像放在darknet/data目录下,比如是gun.jpg。
cd darknet
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg yolov3-voc_20000.weights data/gun.jpg
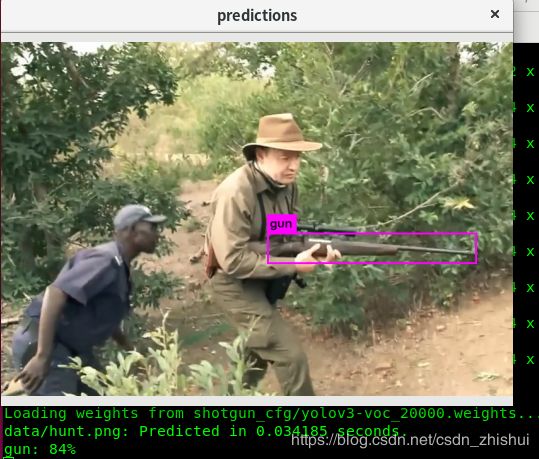
至此,便从零开始使用YOLOv3训练好了一个自己的目标检测器。
【未完待续…】
下一篇【笔记】YOLOv3训练自己的数据集(3)——小技巧和训练日志可视化。