新一代Hadoop大数据挖掘平台和生态介绍
大数据革命正以Apache Hadoop为中心如火如荼的进行着。自从开源分布式数据处理平台在5年前发布时讨论之声就不绝于耳。在过去的一年中,Hadoop赢得了客户的认可,并得到众多商业化的支持以及众多数据库和数据集成软件商的整合。
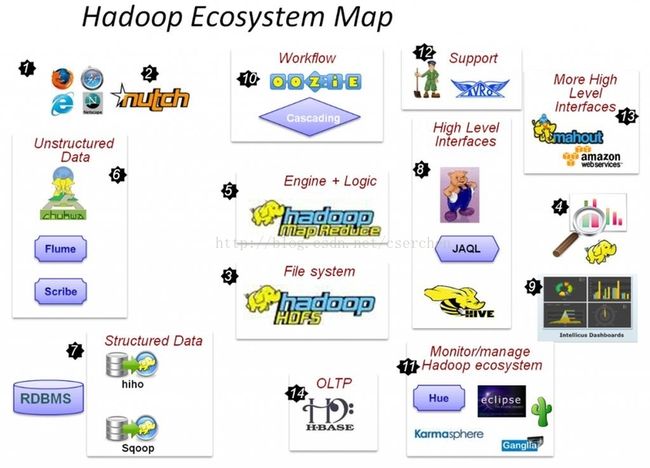
Hadoop可以管理结构化数据,以及诸如服务器日志文件和Web点击流的数据。同时还可以管理以非结构化文本为中心的数据,如Facebook和Twitter。这种处理多类型数据的能力非常重要。它催生了NoSQL平台和产品。如Cassandra, CouchDB, MongoDB以及Oracle最新的NoSQL数据库。
而传统关系型数据库如Oracle,IBM DB2,Microsoft SQL Server和MySQL则都不能处理混合数据类型和非结构化数据。由于事务处理灵活性的需求,Hadoop获得大多数数据分析厂商的关注和支持。展望未来,在未来的3到5年,大数据已经成为私人和公共组织的战略关键。事实上,在未来5年预计有50%的大数据项目会在Hadoop框架下运行
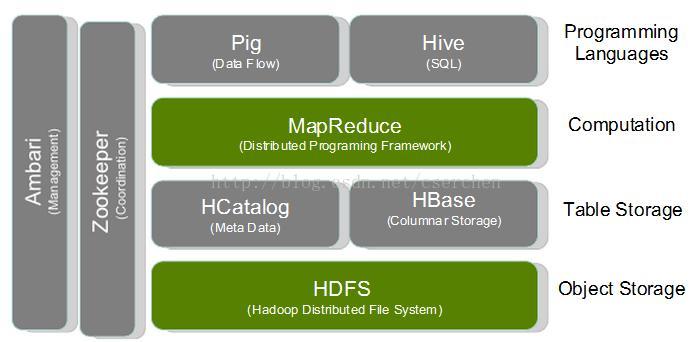
- Hadoop:Java编写的软件框架,以支持数据密集型分布式应用
- ZooKeeper:高可靠性分布式协调系统
- MapReduce:针对大数据的灵活的并行数据处理框架
- HDFS:Hadoop分布式文件系统
- Oozie:负责MapReduce作业调度
- HBase:Key-value数据库
- Hive:构建在MapRudece之上的数据仓库软件包
- Pig:Pig是架构在Hadoop之上的高级数据处理层。Pig Latin语言为编程人员提供了更直观的定制数据流的方法。
- Sqoop和Flume:可改进数据的互操作性和其余部分。Sqoop功能主要是从关系数据库导入数据到Hadoop,并可直接导入到HFDS或Hive。而Flume设计旨在直接将流数据或日志数据导入HDFS。
- Mahout:Mahout提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括集群、分类、推荐过滤、频繁子项挖掘。
- Ambari:Ambari是最新加入Hadoop的项目, Ambari可帮助系统管理员部署和配置Hadoop,升级集群以及监控服务。还可通过API集成与其他的系统管理工具。
MapReduce
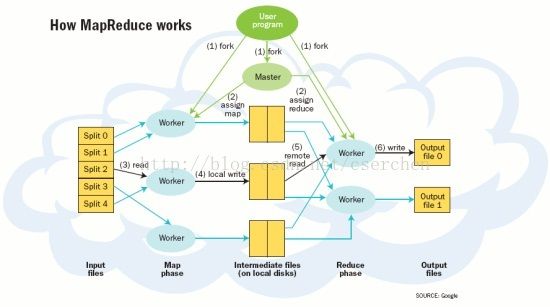
MapReduce作为Hadoop的核心是一种处理大型及超大型数据集(TB级别的数据。包括网络点击产生的流数据、日志文件、社交网络等所带来的数据)并生成相关的执行的编程模型。其主要思想是从函数式编程语言借鉴而来的,同时也包含了从矢量编程语言借鉴的特性。
Google在2004年创造了MapReduce,而从MapReduce到Hadoop这其中经历了一个有趣的转变。MapReduce最初是帮助搜索引擎公司应对万维网所带来的创建索引时产生的大量数据。Google最初也招募了一些硅谷的精英,并雇用了大批的工程师来完善MapReduce。并快速将技术应用在相关的行业之中,如金融、零售等。Goolge曾拿出MapReduce的部分相关信息与Nutch团队分享,以开发开源版本“Hadoop”。但Yahoo则将Nutch收入到旗下。Yahoo在2007年将其发展成Hadoop开源项目。Hadoop现在越来越多的用于大数据的大规模并行数据处理引擎。
MapReduce系统获得成功的原因之一是它为编写需要大规模并行处理的代码提供了简单的编程模式。它受到了Lisp的函数编程特性和其他函数式语言的启发。MapReduce和云计算非常相配。MapReduce的关键特点是它能够对开发人员隐藏操作并行语义 — 并行编程的具体工作方式
传统Hadoop MapReduce
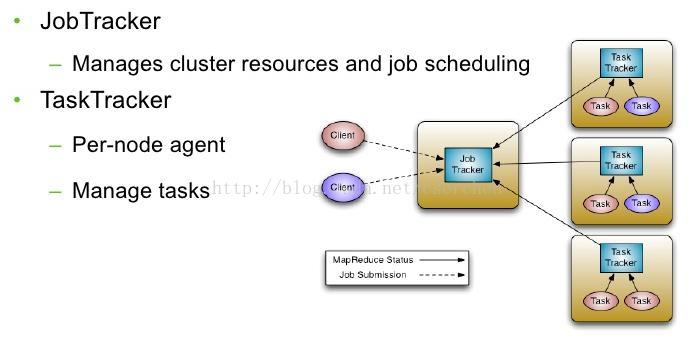
JobTracker:管理集群资源和作业调度
TaskTracker:每节点代理——管理任务
传统Hadoop MapReduce目前存在的限制
- 利用率
- 可扩展性
集群规模限制; 4000节点 ;最大并发任务数:40000 ;JobTracker粗略同步
- 单节点故障
无法结束所有队列和运行中的任务;Jobs restarted on bounce
- 磁盘分区资源进入map和reduce slots
资源利用率低
- 缺乏备用模式支持
迭代应用使用MapReduce实现效率慢10倍。
K-means算法(K-means算法是硬聚类算法,是典型的局域原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则)
- 缺乏wire – compatible协议
客户端和集群为同一版本;应用程序和工作流无法迁移到不同的集群
下一代Hadoop YARN概述
- 可靠性
- 可用性
- 利用率
- 联入兼容性
- Agility & Evolution——敏捷并改进客户控制网格软件包升级的能力
- 可扩展性——集群数量在6000-10000机器
每台机器16内核,48/96GB内存,24TB/36TB硬盘;100000+并发任务 ;10000并发作业
设计中心
将JobTracker的两个主要功能分离为:集群资源的管理和应用程序生存周期管理;MapReduce新生成的user-land库
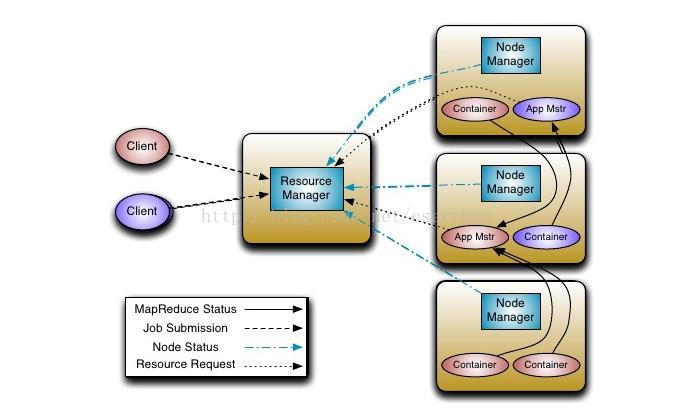
架构
- 应用
应用作为任务提交到框架
- 容器
分配的基本单位(例如容器A:单CPU 2GB内存);替换修复map/reduce slots
资源管理
全局资源调度; 等级化的序列
节点管理
每台计算机代理;管理生命周期的容器;资源监视容器
应用程序管理
管理应用程序调度和程序的执行(例如 MapReduce 应用 Master)
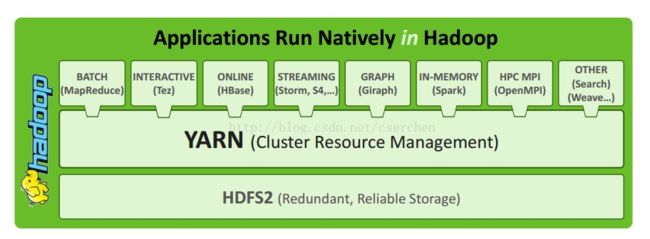
展望未来
- YARN
运行时的改进(容器隔离);补充的编程模型;更长时间的运行服务
- MapReduce
框架增强;Unpack
- 任务调度
多维资源调度
数据处理应用
- 基于Hadoop的OpenMPI
- Spark(Shark is Hive-on-Spark)
- 实时数据处理
Twitter Storm;Apache S4
- 图形处理
Apache Giraph
相比数据处理软件的优势
- Apache HBase
部署于YARN;简单部署集群服务
- MapReduce 框架运行时
可提高任务分配细粒度;允许应用和Pig/Hive随时添加到系统中

根据目前的状况来看,Hadoop作为企业级数据仓库体系结构核心技术,在未来的数年中将会保持持续增长的势头。下一代的MapReduce节点数将从目前的4000增加到6000-10000,其次并发的任务数从目前的40000增加到100000。
下一代的MapReduce也将继续加大对硬件支持、架构也会有所改变,包括更多编程模式的支持。包括MapR、Zettaset、Cloudera、HStreaming、Hadapt、DataStax、Datameer这些与Hadoop相关的新公司已经获得投资,为人们所熟知,为各种市场带来最新技术。
(zz原文链接 http://www.slideshare.net/Hadoop_Summit/map-reduce-whats-next )