Lucence的见解
Lucene:
为什么需要了解搜索引擎:
当需要通过数据库查询数据的时候,模糊查询使用sql语句的like查询,而且查询的数据不应该放在索引库和缓存中。使用like查询有弊端:
1)、数据量比较大的时候,性能比较差,因为它需要去进行全表的查询。
2)、查询出来的结果也不准确,例如,查询一个java,它会把javascript也查询出来,不能实现精确的查询。
搜索引擎的类型:
一、综合性的搜索引擎
综合性的搜索引擎为可以进行多样性的搜索,不管倒排还是全文都行。
二、垂直搜索引擎

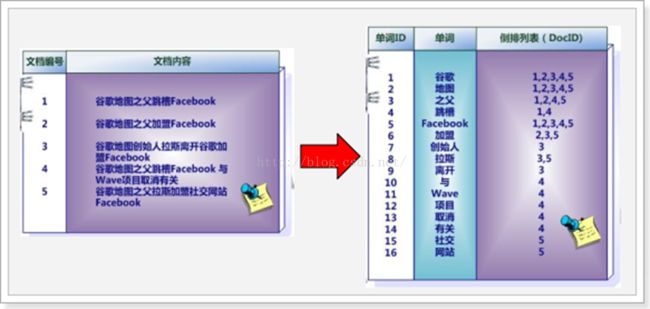
三、倒排索引
倒排索引是一种以关键字和文档编号结合,并且以关键字作为主键的索引结构。
即是把需要检索的内容,把其相对的分开,并且配上文档编号
四、全文检索
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并且将查询的结果反馈给用户。建立了一个索引库在里面查询。
Lucene:
Lucene是一套用于全文检索和搜索的开源程序库,它提供了一个简单却强大的应用程序接口,能够做全文索引和搜寻。
Lucene并不是现成的搜索引擎产品,但是可以用来制作搜索引擎产品。
Directory 索引操作目录
Analyzer 分词器
Document 索引中文档对象
IndexableField 文档内部数据信息
IndexWriterConfig 索引生成配置信息
IndexWriter 索引生成对象
实现Lucene:
需要导入jar包或者依赖:
4.0.0
com.mjf.lucence
mjf.lucence
1.0.1-SNAPSHOT
org.apache.lucene
lucene-core
4.10.2
org.apache.lucene
lucene-analyzers-common
4.10.2
org.apache.lucene
lucene-queryparser
4.10.2
org.apache.httpcomponents
httpclient
4.3.5
org.apache.commons
commons-lang3
3.3.2
org.apache.commons
commons-io
1.3.2
测试:
package com.mjf.lucene.example;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class MyLuceneExample {
public static void main(String[] args) throws Exception {
Document document = new Document();
//定义文档存储
/**
* add存储的参数为IndexAbleField的子类继承
* 所需要存储的字段,要配置Store为yes
*/
document.add(new LongField("id", 691300L, Store.YES));
document.add(new TextField("title", "传智播客,细蚊仔,我俾架三脚鸡硬硬磊过来.磊弊只脚嗲.你快搭两蚊纸摩托车来睇我咯涡.要死嗲哇!三星 B9120 钛灰色 联通3G手机 双卡双待双通", Store.YES));
document.add(new StringField("sellPoint", "要好屏,选夏普!日本原装面板,智能电视,高画质高音质!还有升级版安卓智能新机46DS52供您选择!",Store.YES));
document.add(new LongField("price", 379000L, Store.YES));
document.add(new StringField("image", "http://image.taotao.com/jd/2e45ff47f2e7424cb6d95fb9f05151bd.jpg", Store.YES));
//定义一个indexWriter的工程路径
Directory directory = FSDirectory.open(new File("index"));
//定义一个分词解析器
Analyzer analyzer = new StandardAnalyzer();
//定义indexWriter需要将数据写入其中
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_4_10_2, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.addDocument(document);
//关闭
indexWriter.commit();
indexWriter.close();
}
}验证的方式为在eclipse的工作空间有index的索引库
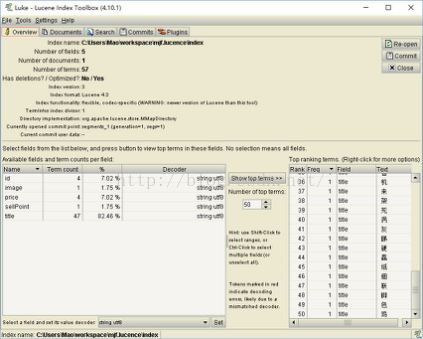
使用索引库工具查看:
中文检索:
检索中文,文字不是重点,重点的是词意,语意分词
先在使用中文分词的检索为IK分词器。
导入依赖:
ikanalyzer
ikanalyzer
1.0
使用的分词器也为:
//当使用自定义分词器
//Analyzer analyzer2 = new IKAnalyzer();自定义分词:
有些时候我们需要检索的分词没有出现,这个时候我们要自己自定义分词,实现自定义分词,则需要导入依赖外,还需要导入cfg.xml文件和自定义的dic文件。
文件:
IK Analyzer 扩展配置
/ext.dic;
Lucene的查询的核心API:
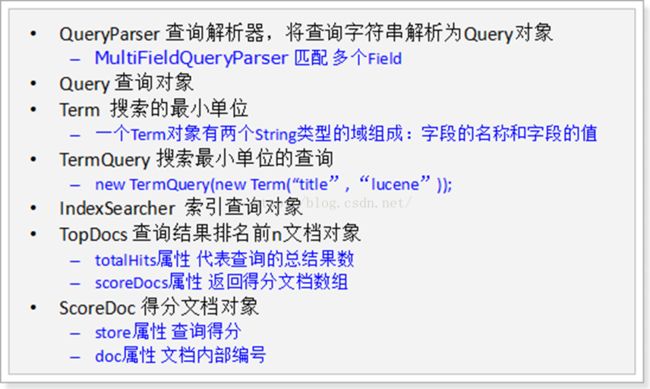
Lucene内置的Query对象:
TermQuery 词条搜索
NumericRangeQuery 范围搜索
MatchAllDocsQuery 匹配所有搜索
WildcardQuery 模糊搜索
FuzzyQuery 相似度搜索
BooleanQuery 布尔搜索(组合查询)
一、TermQuery词条搜索。
Term term= new Term(“title”,”xxx”);
Query query = new TermQuery();二、NumericRangeQuery范围搜索
Query query = NumericRangeQuery.newLongRanage(“id”,691300L,691500L,true,true);三、MatchAllDocsQuery 匹配所有搜索
Query query = new MatchAllDocsQuery();
四、WidcardQuery模糊搜索
?:代表1个任意的字符
*:代表0或者多个任意的字符
Query query = new WidcardQuery(new Teem(“title”,”appl*”));
五、FuzzyQuery相似度搜索
Query query = new FuzzyQuery(new Term(“title”,”lad”),2);六、BooleanQuery布尔搜索(组合查询)
MUST : 必须包含
MUST_NOT :不能包含
SHOULD : 或者
BooleanQUery boolEAN= new BooleanQuery();
Query query1 = new TermQuery(new Term(“trilr”,”xxx”));
Boolean.add(query1,Occur.MUST);
例子:
package com.mjf.lucene.example;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class MyLuceneSearch {
public static void main(String[] args) throws Exception {
/** 词条查询 */
Term term = new Term("title","手");
TermQuery query = new TermQuery(term);
search(query);
/** 范围查询 */
/** 设置的参数为需要查询的字段,最小值,最大值,是否包含最小值,是否包含最大值 */
//Query query = NumericRangeQuery.newLongRange("id", 1L, 691300L, true, true);
//search(query);
/** 全部匹配查询 */
//Query query = new MatchAllDocsQuery();
//search(query);
/** 模糊查询 */
//Query query = new WildcardQuery(new Term("title","传智?"));
//search(query);
/** 相似度查询 */
//Query query = new FuzzyQuery(new Term("title","传说"),2);
//search(query);
//BooleanQuery 布尔搜索
// BooleanQuery booleanQuery =new BooleanQuery();
//
// Query query1 = new TermQuery(new Term("title", "老人"));
// booleanQuery.add(query1, Occur.MUST);
//
// Query query2 = new TermQuery(new Term("title", "手机"));
// booleanQuery.add(query2, Occur.MUST_NOT);
//
// Query query3 = new TermQuery(new Term("title", "苹果"));
// booleanQuery.add(query3, Occur.SHOULD);
//
// search(booleanQuery);
}
private static void search(Query query) throws Exception {
//定义索引 的目录
Directory directory = FSDirectory.open(new File("index"));
//定义indexReader查看器
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearch = new IndexSearcher(indexReader);
//查看 前面的10条记录
TopDocs topDocs = indexSearch.search(query, 5133);
System.out.println("命中数:" + topDocs.totalHits);
//取出数据
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document doc = indexSearch.doc(scoreDoc.doc);
System.out.println("id:" + doc.get("id"));
System.out.println("title:" + doc.get("title"));
System.out.println("sellPoint:" + doc.get("sellPoint"));
}
indexReader.close();
}
}