Hadoop IO
文章从《Hadoop权威指南》中总结而来。
HDFS检验数据完整性
会对写入的所有数据计算校验和,并在读取数据时验证校验和。
写时校验
由io.bytes.per.checksum=512指定字节的数据计算校验和。计算出来的CRC-32校验和(额外存储开销)为4字节,占原数据的总开销低于1%
校验和由客户端产生,发送到DataNode管线。
DataNode在收到客户端数据或是复制其间其他DataNode的数据时,验证数据后存储数据及其校验和。
管线中的最后一个DataNode负责验证校验和(其他DataNode只进行存储?),检测错误即抛出ChecksumException(是IOException子类)异常。
读取校验
客户端读取数据时验证校验和。
每个DataNode均持久保持有一个用于验证的校验和日志,存储着每个数据块最后的验证时间。
每次客户端验证成功后,都会让数据块所在的DataNode进行日志更新。
每个DataNode运行线程(DataBlockScanner)定期验证自身所有的数据块
错误修复
客户端读取数据块若检测到错误,向NameNode报告损坏的数据块以及所在的DataNode,然后抛出异常。
NameNode将其他复本(replica)的同个数据块标记为已损坏,安排DataNode其中一个复本复制到已损坏的DataNode上进行修复。
LocalFileSystem(位于客户端)
执行客户端写入时的校验和读取时的验证。
写入文件时,文件系统客户端会在包含每个文件块校验和的同一个目录内,隐性地创建一个.filename.crc的隐藏文件。
文件块的大小(默认io.bytes.per.checksum=512字节)作为元数据存储在.crc文件中,如果设置发生变化,也可以通过读取该crc文件得知,而后正确读取数据文件。
使用RawLocalFileSystem替代LocalFileSystem可以禁用校验和计算。(Raw即为底层文件系统的意思)
要想在一个应用中实现全局校验和验证,需要将fs.file.impl属性设置为org.apache.hadoop.fs.RawLocalFileSystem进而对文件URI实现重新映射?
LocalFileSystem通过new ChecksumFileSystem使用。
FileSystem ChecksummedFs = new ChecksumFileSystem((FileSystem)rawFs);如果在读取文件时,ChecksumFileSystem类检测到错误,会调用自己的reportChecksumFailure()方法。默认的实现为空方法,LocalFileSystem类会将这个出错的文件及其校验和移动到同一个设备上,一个名为bad_files的side directory中以便检查。
压缩和输入分片
如果输入文件是压缩的,根据文件扩展名可以推断出相应的codec,MapReduce会在读取文件时自动解压文件
通过mapred.output.compress控制是否对输出进行压缩
通过mapred.output.compression.codec控制压缩的算法
通过mapred.output.compression.type控制对一条记录压缩或是对一组进行压缩
对于巨大的,没有存储边界的文件,有如下存储方式:
1. 存储未经压缩的文件
2. 使用支持切分的压缩格式,如bzip2(有些压缩算法不支持分片,Map只能任务只能使用一个节点执行)
3. 在应用中将文件切分成块,就可以使用任意压缩方式对每一个数据块进行压缩,尽量保证压缩后的数据块大小接近HDFS块大小。
4. 使用顺序文件(Sequence File)或一个Avro数据文件,可以支持压缩和切分
对map阶段的输出进行压缩,而后写入磁盘并通过网络传输到reducer,可以提升性能,因为传输的数据量变少了。
序列化(serialization)
是指将结构化对象转化为字节流,以便在网络上传输或写到磁盘进行永久存储。
反序列化(deserialization)是指将字节流转化回结构化对象的逆过程。
主要用于进程间通信以及永久存储
在hadoop中,系统中多个节点上进程间的通信是通过远程过程调用(RPC)实现的。
RPC协议将消息序列化成二进制流后发送到远程节点,远程节点接着将二进制流反序列化为原始消息。
对象--(序列化)-->字节流-->(RPC序列化)-->二进制流
Writable接口(序列化格式接口)
两种方法:
1. 将其状态写到DataOutput二进制流
2. 从DataInput二进制流读取其状态
使用IntWritable封装Java int;使用java.io.DataOutputStream(java.io.DataOutput的一个实现)来封装java.io.ByteArrayOutputStream,以便在序列化中捕捉字节流。
public static byte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
}
一个整数占用4个字节,每个字节按照大端序写入(最重要的字节先写到流,高位数字存在低位内存地址处,低位数字存在高位内存地址处)。
IntWritable实现了WritableComparable接口,该接口继承自Writable和java.lang.Comparable接口
public interface WritableComparable extends Writable, Comparable{}
Hadoop提供了一个优化接口继承自Java Comparator的RawComparator接口。
public interface RawComparator extends Comparable{
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
该接口允许其实现直接比较数据流中的记录,无需先把数据流反序列化为对象,这样避免了新建对象的额外开销。
通过对每个字节数组,截取起始位置(s1,s2),截取长度(l1,l2)来进行比较。
WritableComparator是对RawComparator类(继承自WritableComparable)的一个通用实现。它主要提供两个功能:
1. 提供了对原始compare()方法的一个默认实现,该方法能够反序列化在流中进行比较的对象,并调用对象的compare()方法
2. 充当的是RawComparator实例的工厂。
RawComparator comparator = WritableComparator.get(IntWritable.class);
Writable类可以对Java的基本类型提供封装(short和char可以封装在IntWritable中),均提供set(),get()方法。
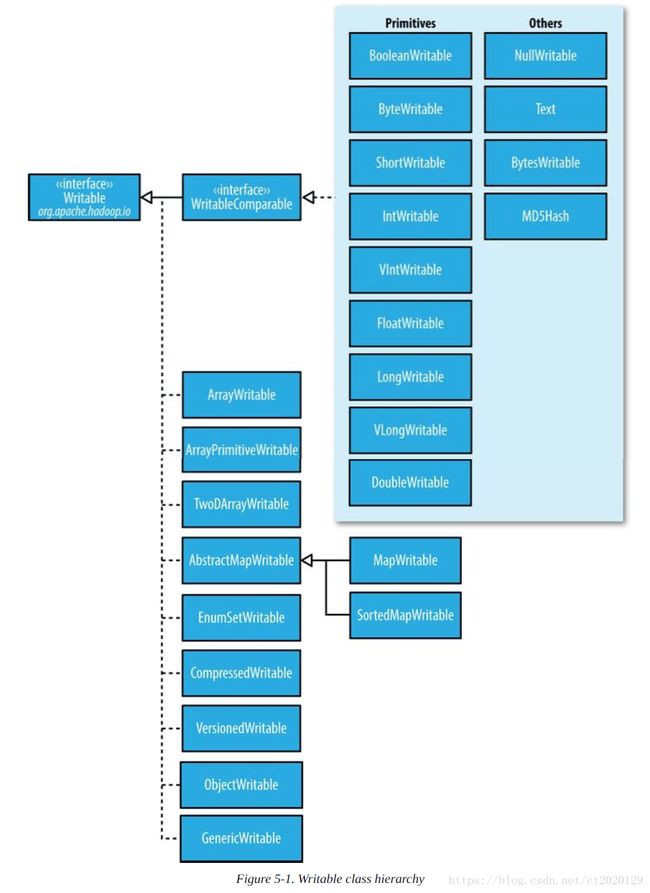
Text类型
是针对UTF-8序列的Writable类。一般可以认为它等价于java.lang.String的Writable。
对Text类的索引是根据编码后字节序列中的位置实现的,并非字符串中的Unicode字符,也不是Java Char的编码单元(如String)。
Text为单例对象,可以通过set()方法来重用Text实例。