组复制官方文档翻译(组复制原理)
Group Replication Background(组复制技术原理)
创建容错系统的最常见方法是使组件冗余,换句话说,部分组件可以删除,系统应该继续按预期运行。这产生了一系列挑战,将这种系统的复杂性提高到一个完全不同的水平。具体来说,复制的数据库必须处理这样的情况,即它们需要维护和管理几个服务器而不是一个。此外,由于多个服务器组成了一个“组”的概念来相互协同工作,必须处理几个其他经典分布式系统问题,诸如网络划分或裂脑情况。
因此,最终的挑战是将数据库的逻辑和多个实例之间的数据复制,以一致和简单的方式融合好。换句话说,使多个服务器同意系统的状态和系统经历的每个改变的数据。这可以被概括为使所有服务器在每个数据库实例状态转换上达成一致,使得它们都作为一个单个数据库能否正常运行或者它们最终收敛到相同状态。意味着整个集群下的每个节点需要作为一个(分布式)状态机操作。
MySQL组复制提供分布式状态机复制,在服务器之间具有强协调。当数据库服务器是属于同一组时,组复制机制可以自动协调它们。该组可以在具有自动选择新主库功能的单主模式下操作,这种情况下一个组只有主节点才可以做写操作。或者,对于更高级的用户,该组可以以多主模式部署,即多个节点都可以做写操作,即使它们是同时发过来的写请求。不过这种情况下,应用层会有部分额外的限制。
有一个内置的组成员服务称为group membership service,用以确保在任何给定的时间点该组的可用性和一致性的视图。各个节点可以脱离和加入该组,并相应地更新该视图。有时,组成员可能会意外脱离组,在这种情况下,故障检测机制会检测到此情况,并通知组视图已更改。以上这些都是自动的。
一个事务要提交时,必须通过查看它在全局事务序列中的顺序,并在得到大多数组成员同意的情况下按照该顺序提交。决定提交或废弃一个已经执行过的事务是由每个成员单独完成的,但所有成员必须做出相同的决定。假设这种情况,存在一个存在网络分区,导致成员无法达成协议的分割,则系统将不会进行,直到此问题解决。因此,还有一个内置的,自动的,裂脑保护机制。
所有上述功能都由组通信协议实现。它提供了故障检测机制failure detection mechanism,组成员服务group membership service以及安全和完全有序的消息传递。所有这些属性是保证创建出来的系统在多个节点之间进行复制时的数据一致性的关键。该技术的核心是Paxos算法的实现,它充当群组通信系统引擎。
ReplicationTechnologies(复制技术对比)
Primary-Secondary Replication(传统主从复制)
传统的MySQL复制提供了一种简单的主 – 从复制架构。它有一个primary节点(master节点)和一个或多个secondary节点(slave节点)。主节点执行写操作,然后将该写操作稍后(因此异步地)发送到从节点,从节点重新执行该SQL(在基于语句的复制中)或应用该操作影响的结果行(在基于行的复制中)。它是一个shared-nothing系统,默认情况下所有节点都有一个完整的数据副本。
还有一个半同步复制,它向异步复制协议添加一个同步步骤。这意味着主节点在提交时等待从节点ACK确认它已经接收到事务。只有这样,主节点才恢复提交操作。
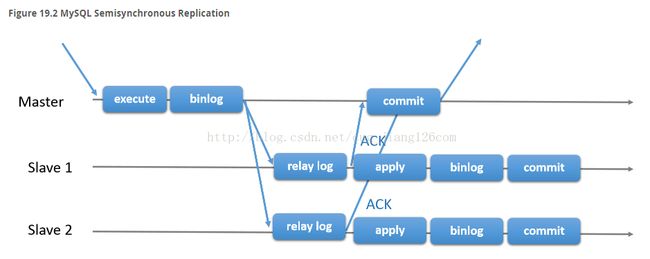
在上面的两个图片中,您可以看到经典异步MySQL复制协议(以及它的半同步变体)的图。蓝色箭头表示在数据节点之间交换的消息或者在服务器和客户端应用之间交换的消息。
Group Replication(组复制)
组复制是一种可用于实现容错系统的技术。复制组是一个通过消息传递相互交互的服务器组。通信层提供了很多保证,例如原子消息和总消息序号的传递。通过这些强大的特性,我们可以构建更高级的数据库复制解决方案。
MySQL组复制构建在这些属性和抽象之上,并实现多主复制协议的更新。实质上,复制组由多个数据库实例组成,并且组中的每个实例都可以独立地执行事务。但是所有读写(RW)事务只有在被组批准后才会提交。只读(RO)事务不需要在组内协调,因此立即提交。换句话说,对于任何RW事务,组需要决定是否提交,因此提交操作不是来自始发服务器的单向决定。准确地说,当事务准备好在始发服务器上提交时,该始发服务器原子地广播写入值(已改变的行)和对应的写入集(已更新的行的唯一标识符)。然后为该事务建立一个全局总序号。最终,这意味着所有服务器以相同的顺序接收同一组事务。因此,所有服务器以相同的顺序应用相同的一组更改,因此它们在组内保持一致。
但是,在不同服务器上并发执行的事务之间可能存在冲突。通过检查两个不同的并发事务的写集合来检测这样的冲突,这个检查过程称为认证(certification)。如果在不同的服务器上执行的两个并发事务更新同一行,则会出现冲突。解析过程会这么做,首先发起的事务在所有服务器上提交,而后发起的事务将在源服务器上回滚,并由组中的其他服务器删除。这实际上是一个分布式环境下“优先提交者赢”的规则。
最后,组复制是一种无共享复制方案(shared_nothing),即每个服务器都有自己的整个数据副本。 上图描述了MySQL组复制协议,并通过将其与MySQL复制(或甚至MySQL半同步复制)进行比较,您可以看到一些差异。注意,为了清楚起见,这个图片中缺少一些基本的共识和Paxos相关信息。
Group ReplicationUse Cases(组复制应用场景)
组复制使您能够通过在一组服务器中复制系统状态来创建具有冗余的容错系统。因此,即使一些服务器发生故障,只要它不是全部或大多数,虽然可能降低系统性能或可扩展性,但系统仍然可用。单一服务器故障是隔离和独立的。它们由group membership service跟踪,它依赖于分布式故障检测器,分布式故障检测器能够在任何节点成员自愿地或由于意外停止而离开群组时发出信号。分布式恢复过程能够确保当有新节点加入组时,该节点会自动更新到最新。Multi-master特性确保即使在单个服务器故障的情况下也不会阻止更新。因此,MySQL组复制保证数据库服务持续可用。
不过需要重点理解,尽管组复制存在高可用,但连接到它的客户端必须被重定向或故障转移到不同的服务器。这不是组复制尝试解决的问题,而是连接器,负载均衡器,路由器或一些其他中间件更适合处理这个问题。
总而言之,MySQL组复制提供了高可用性,高弹性,可靠的MySQL服务。
Examples of Use Case Scenarios(应用案例)
·弹性复制 - 需要非常流畅的复制基础架构的环境,其中服务器的数量必须动态增长或收缩,尽可能减少副作用。例如,云的数据库服务。
·高可用分片 - 分片是实现写扩展的常用方法。使用MySQL组复制实现高可用性分片,其中每个分片映射到复制组。
·替代主从复制 - 在某些情况下,使用单一主节点可能使其成为单点争用。在某些情况下,写入整个组可能更具可扩展性。
·自动化系统 - 可以将MySQL组复制当做一个纯粹的自动化复制系统
Group ReplicationDetails(组复制详解)
Failure Detection(失败检测)
组复制提供了一种故障检测机制,其能够找到和报告哪些服务器是没有响应的,并假定其是死的。更深入地说,故障检测器是提供关于哪些服务器可能已死的信息的分布式服务。后续如果组同意怀疑可能是真的,则由组来决定该服务器确实已经失败。这意味着组中的其余成员进行协调决定排除给定成员。
服务器无响应时触发怀疑机制。当服务器A在给定时间段内没有从服务器B接收消息时,发生超时就会引起怀疑。
如果服务器与组的其余部分隔离,则它怀疑所有其他服务器都失败。由于无法与组达成协议(因为它无法获得大多数成员认可),因此其怀疑没有后果。当服务器以此方式与组隔离时,它无法执行任何本地事务。
Group Membership(组成员服务)
MySQL组复制依赖于组成员服务group membership service。这是内置的插件。它定义哪些服务器是在线的并参与在复制组中。在线服务器列表通常称为视图view。因此,组中的每个服务器具有一致的视图,其是在给定时刻积极参与到组中的成员。
复制组的成员们不仅需要同意事务是否提交,而且也需要决定当前视图。因此,如果服务器同意新的服务器成为组的一部分,则该组本身被重新配置以将该服务器集成在其中,从而触发视图改变。相反的情况也发生,如果服务器自愿地离开组,则该组动态地重新布置其配置,并且触发视图改变。
请注意,当成员自愿离开时,它首先启动动态组重新配置。这触发一个过程,所有成员必须同意新的视图(也就是新视图中没有该离开成员)。然而,如果成员不由自主地离开(例如它已意外停止或网络连接断开),则故障检测机制实现这一事实,并且提出该组的重新配置(新视图没有该离开成员)。如上所述,这需要来自组中大多数成员的同意。如果组不能够达成一致(例如,以不存在大多数服务器在线的方式进行分区),则系统不能动态地改变配置,从而阻止脑裂情况引起的多写。最终,这意味着管理员需要介入并解决这个问题。
Fault-tolerance(容错机制)
MySQL组复制构建在Paxos分布式算法的实现上,以提供服务器之间的分布式协调。因此,它需要大多数服务器处于活动状态以达到选举条件,从而做出决定。这对系统可以容忍的故障数量有直接影响,一个组复制中成员数量设置(n)为n = 2×f + 1。
在实践中,这意味着为了容忍一个故障,组必须有三个服务器。因此,如果一个服务器故障,仍然有两个服务器形成大多数(三分之二)并且允许系统自动地继续运行。但是,如果第二个服务器也异常失败,则该组(剩下一个服务器)阻塞,因为没有多数可以做出决定。
以下是说明上述公式的小表。
| Group Size |
Majority |
Instant Failures Tolerated |
| 1 |
1 |
0 |
| 2 |
2 |
0 |
| 3 |
2 |
1 |
| 4 |
3 |
1 |
| 5 |
3 |
2 |
| 6 |
4 |
2 |
| 7 |
4 |
3 |