TensorFlow 使用 tf.estimator 训练模型(预训练 ResNet-50)
看过 TensorFlow-slim 训练 CNN 分类模型(续) 及其相关系列文章的读者应该已经感受到了 tf.contrib.slim 在训练卷积神经网络方面的极其方便之处,特别是它让构建模型变得非常直观。但不可忽视的是,它还存在一在很大的缺点,就是它在训练模型的同时,没有开放接口让用户可以快速且方便的在验证集上测试模型的性能。比如,现在有训练集和测试集,我们希望在训练集上训练模型,训练的同时又希望能时时看到它在测试集上的效果,以求快速的知道模型是否存在过拟合等问题。但 tf.contrib.slim 的训练函数 slim.learning.train 并没有提供验证数据接口,因此除非自己另外补充代码,否则训练的同时并不能监控模型在测试集上的性能。这个缺陷对于那些想快速调参的人来说是比较致命的,幸好 TensorFlow 推出了新的高级 API tf.estimator.Estimator 可以弥补这个缺陷。简单来说,estimator 这个接口就是为了方便模型的训练过程而开发的,它可以同时训练和验证模型,让训练过程更简单可控。
本文意在结合 slim 在构建模型时的易用之处,以及 estimator 在训练模型时的方便之处,取长补短,兼容并蓄,进一步提升深度学习项目实现的效率。
本文的数据使用猫狗分类数据集(kaggle比赛猫狗数据集百度网盘分享),其中猫对应类标号 0,狗对应类标号 1,所有代码请访问 GitHub: slim_cnn_test。
一、模型定义
模型定义仍然使用 tf.contrib.slim 来写(命名为 model.py):
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 11 17:21:12 2018
@author: shirhe-lyh
"""
import tensorflow as tf
from tensorflow.contrib.slim import nets
import preprocessing
slim = tf.contrib.slim
class Model(object):
"""xxx definition."""
def __init__(self, is_training,
num_classes=2,
fixed_resize_side=256,
default_image_size=224):
"""Constructor.
Args:
is_training: A boolean indicating whether the training version of
computation graph should be constructed.
num_classes: Number of classes.
"""
self._num_classes = num_classes
self._is_training = is_training
self._fixed_resize_side = fixed_resize_side
self._default_image_size = default_image_size
@property
def num_classes(self):
return self._num_classes
def preprocess(self, inputs):
"""preprocessing.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_inputs: A float32 tensor with shape [batch_size,
height, width, num_channels] representing a batch of images.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
preprocessed_inputs = preprocessing.preprocess_images(
inputs, self._default_image_size, self._default_image_size,
resize_side_min=self._fixed_resize_side,
is_training=self._is_training,
border_expand=False, normalize=False,
preserving_aspect_ratio_resize=False)
preprocessed_inputs = tf.cast(preprocessed_inputs, tf.float32)
return preprocessed_inputs
def predict(self, preprocessed_inputs):
"""Predict prediction tensors from inputs tensor.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_inputs: A float32 tensor with shape [batch_size,
height, width, num_channels] representing a batch of images.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
net = tf.squeeze(net, axis=[1, 2])
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None,
scope='Predict/logits')
return {'logits': logits}
def postprocess(self, prediction_dict):
"""Convert predicted output tensors to final forms.
Args:
prediction_dict: A dictionary holding prediction tensors.
**params: Additional keyword arguments for specific implementations
of specified models.
Returns:
A dictionary containing the postprocessed results.
"""
postprocessed_dict = {}
for logits_name, logits in prediction_dict.items():
logits = tf.nn.softmax(logits)
classes = tf.argmax(logits, axis=1)
classes_name = logits_name.replace('logits', 'classes')
postprocessed_dict[logits_name] = logits
postprocessed_dict[classes_name] = classes
return postprocessed_dict
def loss(self, prediction_dict, groundtruth_lists):
"""Compute scalar loss tensors with respect to provided groundtruth.
Args:
prediction_dict: A dictionary holding prediction tensors.
groundtruth_lists: A list of tensors holding groundtruth
information, with one entry for each branch prediction.
Returns:
A dictionary mapping strings (loss names) to scalar tensors
representing loss values.
"""
logits = prediction_dict.get('logits')
slim.losses.sparse_softmax_cross_entropy(logits, groundtruth_lists)
loss = slim.losses.get_total_loss()
loss_dict = {'loss': loss}
return loss_dict
def accuracy(self, postprocessed_dict, groundtruth_lists):
"""Calculate accuracy.
Args:
postprocessed_dict: A dictionary containing the postprocessed
results
groundtruth_lists: A dict of tensors holding groundtruth
information, with one entry for each image in the batch.
Returns:
accuracy: The scalar accuracy.
"""
classes = postprocessed_dict['classes']
accuracy = tf.reduce_mean(
tf.cast(tf.equal(classes, groundtruth_lists), dtype=tf.float32))
return accuracy
网络结构非常简单(见 predict 函数),只替换了 ResNet-50 的最后一个全连接层,使用 slim 写神经网络的模型可以参考文章 TensorFlow-slim 训练 CNN 分类模型。其它函数顾名思义,也都非常简单。
二、模型训练
利用 tf.estimator 训练模型时需要写两个重要的函数,一个用于数据输入的函数(input_fn),另一个用于模型创建的函数(model_fn)。下面逐一来说明。(这里沿用以前文章 ,数据格式仍然采用 TFRecord)。
首先我们从调用顺序来介绍一下大概的训练过程(完整官方文档:tf.estimator):
- 使用
tf.estimator.train_and_evaluate启动训练和验证过程。该函数的完整形式是:
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
其中 estimator 是一个 tf.estimator.Estimator 对象,用于指定模型函数以及其它相关参数;train_spec 是一个 tf.estimator.TrainSpec 对象,用于指定训练的输入函数以及其它参数;eval_spec 是一个 tf.estimator.EvalSpec 对象,用于指定验证的输入函数以及其它参数。
- 使用
tf.estimator.Estimator定义 Estimator 实例 estimator。类 Estimator 的完整形式是:
tf.estimator.Estimator(model_fn, model_dir=None, config=None,
params=None, warm_start_from=None)
其中 model_fn 是模型函数;model_dir 是训练时模型保存的路径;config 是tf.estimator.RunConfig 的配置对象;params 是传入 model_fn 的超参数字典;warm_start_from 或者是一个预训练文件的路径,或者是一个tf.estimator.WarmStartSettings 对象,用于完整的配置热启动参数。
- 使用
tf.estimator.TrainSpec指定训练输入函数及相关参数。该类的完整形式是:
tf.estimator.TrainSpec(input_fn, max_steps, hooks)
其中 input_fn 用来提供训练时的输入数据;max_steps 指定总共训练多少步;hooks是一个 tf.train.SessionRunHook 对象,用来配置分布式训练等参数。
- 使用
tf.estimator.EvalSpec指定验证输入函数及相关参数。该类的完整形式是:
tf.estimator.EvalSpec(
input_fn,
steps=100,
name=None,
hooks=None,
exporters=None,
start_delay_secs=120,
throttle_secs=600)
其中 input_fn 用来提供验证时的输入数据;steps 指定总共验证多少步(一般设定为 None 即可);hooks 用来配置分布式训练等参数;exporters 是一个 Exporter 迭代器,会参与到每次的模型验证;start_delay_secs 指定多少秒之后开始模型验证;throttle_secs 指定多少秒之后重新开始新一轮模型验证(当然,如果没有新的模型断点保存,则该数值秒之后不会进行模型验证,因此这是新一轮模型验证需要等待的最小秒数)。
- 定义模型函数
model_fn,返回类 tf.estimator.EstimatorSpec 的一个实例。model_fn 的完整定义形式是(函数名任取):
def create_model_fn(features, labels, mode, params=None):
params = params or {}
loss, train_op, ... = None, None, ...
prediction_dict = ...
if mode in (tf.estimator.ModeKeys.TRAIN, tf.estimator.ModeKeys.EVAL):
loss = ...
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = ...
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=prediction_dict,
loss=loss,
train_op=train_op,
...)
其中 features,labels 可以是一个张量,也可以是由张量组成的一个字典;mode 指定训练模式,可以取 (TRAIN, EVAL, PREDICT)三者之一;params 是一个(可要可不要的)字典,指定其它超参数。model_fn 必须定义模型的预测结果、损失、优化器等,它返回类 tf.estimator.EstimatorSpec 的一个对象。
- 类
tf.estimator.EstimatorSpec的完整形式是:
tf.estimator.EstimatorSpec(
mode,
predictions=None,
loss=None,
train_op=None,
eval_metric_ops=None,
export_outputs=None,
training_chief_hooks=None,
training_hooks=None,
scaffold=None,
evaluation_hooks=None,
prediction_hooks=None)
其中 mode 指定当前是处于训练、验证还是预测状态;predictions 是预测的一个张量,或者是由张量组成的一个字典;loss 是损失张量;train_op 指定优化操作;eval_metric_ops 指定各种评估度量的字典,这个字典的值必须是如下两种形式:
- Metric 类的实例;
- 调用某个评估度量函数的结果对 (metric_tensor, update_op);
参数 export_outputs 只用于模型保存,描述了导出到 SavedModel 的输出格式;参数scaffold 是一个 tf.train.Scaffold 对象,可以在训练阶段初始化、保存等时使用。
- 定义输入函数
input_fn,返回如下两种格式之一:
- tf.data.Dataset 对象:这个对象的输出必须是元组队 (features, labels),而且必须满足下一条返回格式的同等约束;
- 元组 (features, labels):features 以及 labels 都必须是一个张量或由张量组成的字典。
了解了这些之后,我们来看使用 tf.estimator 的训练代码(命名为:train.py):
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 30 19:27:44 2018
@author: shirhe-lyh
Train a CNN model to classifying 10 digits.
Example Usage:
---------------
python3 train.py \
--train_record_path: Path to training tfrecord file.
--val_record_path: Path to validation tfrecord file.
--model_dir: Path to log directory.
"""
import functools
import logging
import os
import tensorflow as tf
import exporter
import model
slim = tf.contrib.slim
flags = tf.app.flags
flags.DEFINE_string('gpu_indices', '0', 'The index of gpus to used.')
flags.DEFINE_string('train_record_path',
'./datasets/train.record',
'Path to training tfrecord file.')
flags.DEFINE_string('val_record_path',
'./datasets/val.record',
'Path to validation tfrecord file.')
flags.DEFINE_string('checkpoint_path',
None,
'Path to a pretrained model.')
flags.DEFINE_string('model_dir', './training', 'Path to log directory.')
flags.DEFINE_float('keep_checkpoint_every_n_hours',
0.2,
'Save model checkpoint every n hours.')
flags.DEFINE_string('learning_rate_decay_type',
'exponential',
'Specifies how the learning rate is decayed. One of '
'"fixed", "exponential", or "polynomial"')
flags.DEFINE_float('learning_rate',
0.0001,
'Initial learning rate.')
flags.DEFINE_float('end_learning_rate',
0.000001,
'The minimal end learning rate used by a polynomial decay '
'learning rate.')
flags.DEFINE_float('decay_steps',
1000,
'Number of epochs after which learning rate decays. '
'Note: this flag counts epochs per clone but aggregates '
'per sync replicas. So 1.0 means that each clone will go '
'over full epoch individually, but replicas will go once '
'across all replicas.')
flags.DEFINE_float('learning_rate_decay_factor',
0.5,
'Learning rate decay factor.')
flags.DEFINE_integer('num_classes', 2, 'Number of classes.')
flags.DEFINE_integer('batch_size', 64, 'Batch size.')
flags.DEFINE_integer('num_steps', 5000, 'Number of steps.')
flags.DEFINE_integer('input_size', 224, 'Number of steps.')
FLAGS = flags.FLAGS
def get_decoder():
"""Returns a TFExampleDecoder."""
keys_to_features = {
'image/encoded':
tf.FixedLenFeature((), tf.string, default_value=''),
'image/format':
tf.FixedLenFeature((), tf.string, default_value='jpeg'),
'image/class/label':
tf.FixedLenFeature([1], tf.int64, default_value=tf.zeros([1],
dtype=tf.int64))}
items_to_handlers = {
'image': slim.tfexample_decoder.Image(image_key='image/encoded',
format_key='image/format',
channels=3),
'label': slim.tfexample_decoder.Tensor('image/class/label', shape=[])}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers)
return decoder
def transform_data(image):
size = FLAGS.input_size + 32
image = tf.squeeze(tf.image.resize_bilinear([image], size=[size, size]))
image = tf.to_float(image)
return image
def read_dataset(file_read_fun, input_files, num_readers=1, shuffle=False,
num_epochs=0, read_block_length=32, shuffle_buffer_size=2048):
"""Reads a dataset, and handles repeatition and shuffling.
This function and the following are modified from:
https://github.com/tensorflow/models/blob/master/research/
object_detection/builders/dataset_builder.py
Args:
file_read_fun: Function to use in tf.contrib.data.parallel_iterleave,
to read every individual file into a tf.data.Dataset.
input_files: A list of file paths to read.
Returns:
A tf.data.Dataset of (undecoded) tf-records.
"""
# Shard, shuffle, and read files
filenames = tf.gfile.Glob(input_files)
if num_readers > len(filenames):
num_readers = len(filenames)
tf.logging.warning('num_readers has been reduced to %d to match input '
'file shards.' % num_readers)
filename_dataset = tf.data.Dataset.from_tensor_slices(filenames)
if shuffle:
filename_dataset = filename_dataset.shuffle(100)
elif num_readers > 1:
tf.logging.warning('`shuffle` is false, but the input data stream is '
'still slightly shuffled since `num_readers` > 1.')
filename_dataset = filename_dataset.repeat(num_epochs or None)
records_dataset = filename_dataset.apply(
tf.contrib.data.parallel_interleave(
file_read_fun,
cycle_length=num_readers,
block_length=read_block_length,
sloppy=shuffle))
if shuffle:
records_dataset = records_dataset.shuffle(shuffle_buffer_size)
return records_dataset
def create_input_fn(record_paths, batch_size=64,
num_epochs=0, num_parallel_batches=8,
num_prefetch_batches=2):
"""Create a train or eval `input` function for `Estimator`.
Args:
record_paths: A list contains the paths of tfrecords.
Returns:
`input_fn` for `Estimator` in TRAIN/EVAL mode.
"""
def _input_fn():
decoder = get_decoder()
def decode(value):
keys = decoder.list_items()
tensors = decoder.decode(value)
tensor_dict = dict(zip(keys, tensors))
image = tensor_dict.get('image')
image = transform_data(image)
features_dict = {'image': image}
return features_dict, tensor_dict.get('label')
dataset = read_dataset(
functools.partial(tf.data.TFRecordDataset,
buffer_size=8 * 1000 * 1000),
input_files=record_paths,
num_epochs=num_epochs)
if batch_size:
num_parallel_calles = batch_size * num_parallel_batches
else:
num_parallel_calles = num_parallel_batches
dataset = dataset.map(decode, num_parallel_calls=num_parallel_calles)
if batch_size:
dataset = dataset.apply(
tf.contrib.data.batch_and_drop_remainder(batch_size))
dataset = dataset.prefetch(num_prefetch_batches)
return dataset
return _input_fn
def create_predict_input_fn():
"""Creates a predict `input` function for `Estimator`.
Modified from:
https://github.com/tensorflow/models/blob/master/research/
object_detection/inputs.py
Returns:
`input_fn` for `Estimator` in PREDICT mode.
"""
def _predict_input_fn():
"""Decodes serialized tf.Examples and returns `ServingInputReceiver`.
Returns:
`ServingInputReceiver`.
"""
example = tf.placeholder(dtype=tf.string, shape=[], name='tf_example')
decoder = get_decoder()
keys = decoder.list_items()
tensors = decoder.decode(example, items=keys)
tensor_dict = dict(zip(keys, tensors))
image = tensor_dict.get('image')
image = transform_data(image)
images = tf.expand_dims(image, axis=0)
return tf.estimator.export.ServingInputReceiver(
features={'image': images},
receiver_tensors={'serialized_example': example})
return _predict_input_fn
def create_model_fn(features, labels, mode, params=None):
"""Constructs the classification model.
Modifed from:
https://github.com/tensorflow/models/blob/master/research/
object_detection/model_lib.py.
Args:
features: A 4-D float32 tensor with shape [batch_size, height,
width, channels] representing a batch of images. (Support dict)
labels: A 1-D int32 tensor with shape [batch_size] representing
the labels of each image. (Support dict)
mode: Mode key for tf.estimator.ModeKeys.
params: Parameter dictionary passed from the estimator.
Returns:
An `EstimatorSpec` the encapsulates the model and its serving
configurations.
"""
params = params or {}
loss, acc, train_op, export_outputs = None, None, None, None
is_training = mode == tf.estimator.ModeKeys.TRAIN
cls_model = model.Model(is_training=is_training,
num_classes=FLAGS.num_classes)
preprocessed_inputs = cls_model.preprocess(features.get('image'))
prediction_dict = cls_model.predict(preprocessed_inputs)
postprocessed_dict = cls_model.postprocess(prediction_dict)
if mode == tf.estimator.ModeKeys.TRAIN:
if FLAGS.checkpoint_path:
init_variables_from_checkpoint()
if mode in (tf.estimator.ModeKeys.TRAIN, tf.estimator.ModeKeys.EVAL):
loss_dict = cls_model.loss(prediction_dict, labels)
loss = loss_dict['loss']
classes = postprocessed_dict['classes']
acc = tf.reduce_mean(tf.cast(tf.equal(classes, labels), 'float'))
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', acc)
scaffold = None
if mode == tf.estimator.ModeKeys.TRAIN:
global_step = tf.train.get_or_create_global_step()
learning_rate = configure_learning_rate(FLAGS.decay_steps,
global_step)
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9)
train_op = slim.learning.create_train_op(loss, optimizer,
summarize_gradients=True)
keep_checkpoint_every_n_hours = FLAGS.keep_checkpoint_every_n_hours
saver = tf.train.Saver(
sharded=True,
keep_checkpoint_every_n_hours=keep_checkpoint_every_n_hours,
save_relative_paths=True)
tf.add_to_collection(tf.GraphKeys.SAVERS, saver)
scaffold = tf.train.Scaffold(saver=saver)
eval_metric_ops = None
if mode == tf.estimator.ModeKeys.EVAL:
accuracy = tf.metrics.accuracy(labels=labels, predictions=classes)
eval_metric_ops = {'Accuracy': accuracy}
if mode == tf.estimator.ModeKeys.PREDICT:
export_output = exporter._add_output_tensor_nodes(postprocessed_dict)
export_outputs = {
tf.saved_model.signature_constants.PREDICT_METHOD_NAME:
tf.estimator.export.PredictOutput(export_output)}
return tf.estimator.EstimatorSpec(mode=mode,
predictions=prediction_dict,
loss=loss,
train_op=train_op,
eval_metric_ops=eval_metric_ops,
export_outputs=export_outputs,
scaffold=scaffold)
def configure_learning_rate(decay_steps, global_step):
"""Configures the learning rate.
Modified from:
https://github.com/tensorflow/models/blob/master/research/slim/
train_image_classifier.py
Args:
decay_steps: The step to decay learning rate.
global_step: The global_step tensor.
Returns:
A `Tensor` representing the learning rate.
"""
if FLAGS.learning_rate_decay_type == 'exponential':
return tf.train.exponential_decay(FLAGS.learning_rate,
global_step,
decay_steps,
FLAGS.learning_rate_decay_factor,
staircase=True,
name='exponential_decay_learning_rate')
elif FLAGS.learning_rate_decay_type == 'fixed':
return tf.constant(FLAGS.learning_rate, name='fixed_learning_rate')
elif FLAGS.learning_rate_decay_type == 'polynomial':
return tf.train.polynomial_decay(FLAGS.learning_rate,
global_step,
decay_steps,
FLAGS.end_learning_rate,
power=1.0,
cycle=False,
name='polynomial_decay_learning_rate')
else:
raise ValueError('learning_rate_decay_type [%s] was not recognized' %
FLAGS.learning_rate_decay_type)
def init_variables_from_checkpoint(checkpoint_exclude_scopes=None):
"""Variable initialization form a given checkpoint path.
Modified from:
https://github.com/tensorflow/models/blob/master/research/
object_detection/model_lib.py
Note that the init_fn is only run when initializing the model during the
very first global step.
Args:
checkpoint_exclude_scopes: Comma-separated list of scopes of variables
to exclude when restoring from a checkpoint.
"""
exclude_patterns = None
if checkpoint_exclude_scopes:
exclude_patterns = [scope.strip() for scope in
checkpoint_exclude_scopes.split(',')]
variables_to_restore = tf.global_variables()
variables_to_restore.append(slim.get_or_create_global_step())
variables_to_init = tf.contrib.framework.filter_variables(
variables_to_restore, exclude_patterns=exclude_patterns)
variables_to_init_dict = {var.op.name: var for var in variables_to_init}
available_var_map = get_variables_available_in_checkpoint(
variables_to_init_dict, FLAGS.checkpoint_path,
include_global_step=False)
tf.train.init_from_checkpoint(FLAGS.checkpoint_path, available_var_map)
def get_variables_available_in_checkpoint(variables,
checkpoint_path,
include_global_step=True):
"""Returns the subset of variables in the checkpoint.
Inspects given checkpoint and returns the subset of variables that are
available in it.
Args:
variables: A dictionary of variables to find in checkpoint.
checkpoint_path: Path to the checkpoint to restore variables from.
include_global_step: Whether to include `global_step` variable, if it
exists. Default True.
Returns:
A dictionary of variables.
Raises:
ValueError: If `variables` is not a dict.
"""
if not isinstance(variables, dict):
raise ValueError('`variables` is expected to be a dict.')
# Available variables
ckpt_reader = tf.train.NewCheckpointReader(checkpoint_path)
ckpt_vars_to_shape_map = ckpt_reader.get_variable_to_shape_map()
if not include_global_step:
ckpt_vars_to_shape_map.pop(tf.GraphKeys.GLOBAL_STEP, None)
vars_in_ckpt = {}
for variable_name, variable in sorted(variables.items()):
if variable_name in ckpt_vars_to_shape_map:
if ckpt_vars_to_shape_map[variable_name] == variable.shape.as_list():
vars_in_ckpt[variable_name] = variable
else:
logging.warning('Variable [%s] is avaible in checkpoint, but '
'has an incompatible shape with model '
'variable. Checkpoint shape: [%s], model '
'variable shape: [%s]. This variable will not '
'be initialized from the checkpoint.',
variable_name,
ckpt_vars_to_shape_map[variable_name],
variable.shape.as_list())
else:
logging.warning('Variable [%s] is not available in checkpoint',
variable_name)
return vars_in_ckpt
def main(_):
# Specify which gpu to be used
os.environ["CUDA_VISIBLE_DEVICES"] = FLAGS.gpu_indices
estimator = tf.estimator.Estimator(model_fn=create_model_fn,
model_dir=FLAGS.model_dir)
train_input_fn = create_input_fn([FLAGS.train_record_path],
batch_size=FLAGS.batch_size)
train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn,
max_steps=FLAGS.num_steps)
eval_input_fn = create_input_fn([FLAGS.val_record_path],
batch_size=FLAGS.batch_size,
num_epochs=1)
predict_input_fn = create_predict_input_fn()
eval_exporter = tf.estimator.FinalExporter(
name='servo', serving_input_receiver_fn=predict_input_fn)
eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn, steps=None,
exporters=eval_exporter)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
if __name__ == '__main__':
tf.app.run()
【说明】
1.如果训练时训练数据被分别写到 多个 tfrecord 里,则修改 main 函数里的
train_input_fn = create_input_fn([FLAGS.train_record_path],
batch_size=FLAGS.batch_size)
以及
eval_input_fn = create_input_fn([FLAGS.val_record_path],
batch_size=FLAGS.batch_size,
num_epochs=1)
将 [FLAGS.train_record_path] 以及 [FLAGS.val_record_path] 替换成你的 tfrecord 文件路径列表。
2.预训练路径由 FLAGS.checkpoint_path 指定,模型导入部分请参考函数init_variables_from_checkpoint。如果不传入预训练模型,请将 FLAGS.checkpoint_path 设置为 None 即可。
3.定义训练的输入函数时还有另一种方式(这种方式来自于以前的文章):
flags.DEFINE_integer('num_train_samples', 50000, 'Number of samples.')
def get_record_dataset(record_path, reader=None, num_samples=50000,
num_classes=10):
"""Get a tensorflow record file.
Args:
"""
if not reader:
reader = tf.TFRecordReader
decoder = get_decoder()
labels_to_names = None
items_to_descriptions = {
'image': 'An image.',
'label': 'A single integer.'}
return slim.dataset.Dataset(
data_sources=record_path,
reader=reader,
decoder=decoder,
num_samples=num_samples,
num_classes=num_classes,
items_to_descriptions=items_to_descriptions,
labels_to_names=labels_to_names)
def create_train_input_fn(record_path, batch_size=64,
num_samples=50000, num_classes=2):
"""Creates a train `input` function for `Estimator`.
Returns:
`input_fn` for `Estimator` in TRAIN mode.
"""
def _train_input_fn():
dataset = get_record_dataset(record_path,
num_samples=num_samples,
num_classes=num_classes)
data_provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
image, label = data_provider.get(['image', 'label'])
image = transform_data(image)
inputs, labels = tf.train.batch([image, label],
batch_size=batch_size,
allow_smaller_final_batch=True)
return {'image': inputs}, labels
return _train_input_fn
使用时,直接由
train_input_fn = create_train_input_fn(FLAGS.train_record_path,
batch_size=FLAGS.batch_size,
num_samples=FLAGS.num_samples,
num_classes=FLAGS.num_classes)
指定。这种方式的缺陷是必须要知道 tfrecord 里面的样本数量,然后通过
flags.DEFINE_integer('num_train_samples', 50000, 'Number of samples.')
设置。
三、训练过程
1.生成 TFRecord
通过运行:
python3 generate_tfrecord.py --images_dir path/to/images
生成(请将 path/to/images 替换成你的猫狗数据训练集文件夹的具体路径)。其它参数,如 train_annotation_path 等可试情况指定,如果你都使用默认值,则会在当前路径下生成一个叫 datasets 的文件夹,里面包含了训练和验证用的 tfrecord:train.record和 val.record。
2.启动训练
通过运行
python3 train.py --train_record_path path/to/train.record
--val_record_path path/to/val.record
--checkpoint_path path/to/resnet_v1_50.ckpt
--model_dir path/to/directory/to/saved/trained/models
启动。其中 train_record_path 和 val_record_path 分别指向训练和验证的 tfrecord 文件路径,如果你运行 generate_tfrecord.py 使用了默认路径,则这里不需要额外指定,直接使用默认值即可。checkpoint_path 指定预训练模型 resnet_v1_50.ckpt 文件路径,如果不使用预训练模型,则直接省略这个参数,使用默认值 None。model_dir 指定模型保存的路径,可以使用默认值:当前路径下自动建立的文件夹 training。
如果你训练和验证的 tfrecord 都有 多个,请参考 二、模型训练 的 说明1。
3.训练曲线
通过运行
tensorboard --logdir path/to/model_dir
监督训练的损失和正确率曲线。其中参数 logdir 填写你的模型保存路径,即 2 中的 model_dir。
比如,我训练的曲线如下(其中:蓝线表示验证集上的评估结果,黄线是训练集上的评估结果):
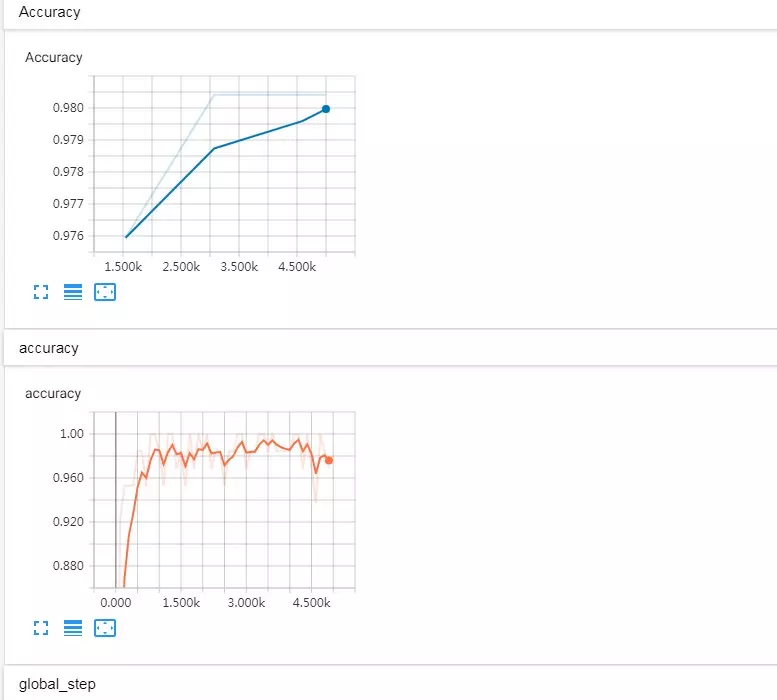
准确率曲线:蓝线验证准确率,黄线训练准确率
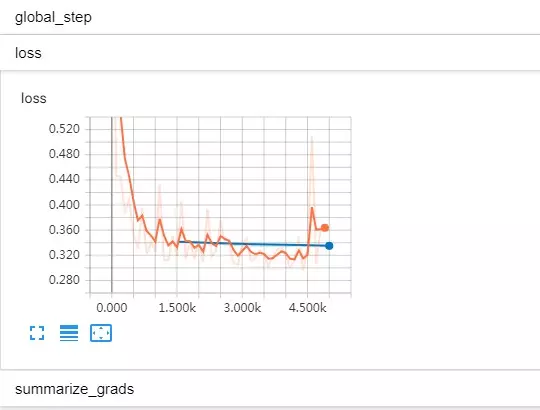
损失曲线:蓝线验证损失,黄线训练损失
4.模型导出
运行
python3 export_inference_graph.py \
--trained_checkpoint_prefix Path/to/model.ckpt-xxx \
--output_directory Path/to/exported_pb_file_directory
将 .ckpt 文件转化为 .pb 文件。如果你使用默认的训练步数:num_steps=5000,则参数trained_checkpoint_prefix 填写 model.ckpt-5000 的路径,比如 ./training/model.ckpt-5000。参数 output_directory 填写导出的 .pb 文件保存的文件夹路径,如./training/frozen_inference_graph_pb,该文件内生成的 frozen_inferece_graph.pb就是最后要调用的模型。
5.模型使用
请参考 predict.py 文件。