Hadoop伪分布式、完全分布式搭建和测试(详细版)
安装
Hadoop 入门学习,快速搭建伪分布式环境。
注:需要下载的安装包在文章底部,请自行获取。
1. 修改主机名
vim /etc/hostname
vim /etc/hosts
rebootreboot 重启主机使修改配置文件生效,这里我设置的主机名是 : cx。
注意:出于安全考虑,如果只想局域网访问 127.0.0.1 cx 就可以 如果不在远程服务器,不在一个局域网,可以配置成 0.0.0.0 cx 运行所以IP都可以访问 【hadoop安装完成并正确启动会,后查看监听端口 netstat -tpnl |grep 8020,就会看到你配置的IP及监听的8020端口】
[root@cx hadoop]# cat /etc/hosts
0.0.0.0 cx
127.0.0.1 localhost
127.0.1.1 localhost
::1 localhos
[root@cx hadoop]# netstat -tpnl |grep 8020
tcp 0 0 0.0.0.0:8020 0.0.0.0:* LISTEN 10046/java [root@cx ~]# hostname
cx2. 免密登陆
删除已有的 ssh 配置,使用命令 rm -r ~/.ssh 进行删除 ;
生成新的 ssh-key ,使用命令 ssh-keygen -t rsa ;
-为本机进行公钥的注册:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh-keygen -t rsa
clear
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys或者 ssh-copy-id slave2形式 这个也可以自己给自己copy
ssh-copy-id cx
3. 安装JDK
下载JDK包,开始安装,默认安装的位置是在/usr/java/ 目录下
rpm -ivh jdk-8u91-linux-x64.rpm 设置java环境变量 vim /etc/profile
JAVA_HOME=JAVA_HOME=/usr/java/jdk1.8.0_91
PATH=$PATH:$JAVA_HOME/bin:
export PATH JAVA_HOMEsource /etc/profile 是环境变量生效
[root@cx local]# vim /etc/profile
[root@cx local]# source /etc/profile
[root@cx local]# java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)java -version 验证是否安装成功
4. 安装Hadoop
将下载好的hadoop包解压移动到 /user/local/ 目录下
mv hadoop-2.7.3.tar.gz /usr/local/解压文件
cd /usr/local/hadoop
tar -xvf hadoop-2.7.3.tar.gz重命名解压出来的文件,并进去改名后的文件夹,分别建立 hdfs/tmp、hdfs/name、hdfs/data目录
mv hadoop-2.7.3.tar.gz hadoop
cd ./hadoop
mkdir -p hdfs/{data,name,tmp}5. Hadoop配置
在 /usr/local/hadoop/etc/hadoop 下配置各个文件
进入目录 cd /usr/local/hadoop/etc/hadoop
- 配置hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_91
export HADOOP_PID_DIR=/usr/local/hadoop/hdfs/tmp- 配置mapred-env.sh 【计算引擎】
export HADOOP_MAPRED_PID_DIR=/usr/local/hadoop/hdfs/tmp- 配置yarn-env.sh
export YARN_PID_DIR=/usr/local/hadoop/hdfs/tmp- 配置core-site.xml文件
hdfs系统会把用到的数据存储在core-site.xml中由hadoop.tmp.dir指定,而这个值默认位于/tmp/hadoop-${user.name}下面, 由于/tmp目录在系统重启时候会被删除,所以应该修改目录位置。
<property>
<name>fs.defaultFSname>
<value>hdfs://cx:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/hdfs/tmpvalue>
property>- 配置hdfs-site.xml文件
可以关闭权限检查 在namenode的hdfs-site.xml上
<property>
<name>dfs.replicationname>
<value>1value>
property>
#这个是设置block大小为3M,默认为124M
<property>
<name>dfs.block.sizename>
<value>3145728value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/local/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/local/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>- 创建配置mapred-site.xml文件,直接执行命令cp mapred-site.xml.templete mapred-site.xml
cp mapred-site.xml.templete mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>- 配置yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>- 配置slaves指定datanode节点
vim slaves 将localhost改成主机名/添加主机名- 修改环境变量文件”/etc/profile”,并使其生效
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbinHadoop启动
第一次启动hadoop之前需要格式化namenode节点,命令为hadoop namenode -format。
两种方式启动方式,可按需选择,全部启动还是,只启动相应功能
1、全部启动 :start-all.sh
2、分开启动:单独启动hdfs start-hdfs.sh;单独启动yarn start-yarn.sh
jps 查看是否启动成功。
start-hdfs.sh 会启动文件系统的 namenode datanode
start-yarn.sh 会启动资源调度 ResourceManager NodeManager
停止也有2种方式:
1、停止全部 stop-all.sh
2、分开停止:1、停止hdfs stop-hdfs.sh;2、停止yarn stop-yarn.sh
输入 jps 查看
[root@cx hadoop]# jps
23104 DataNode
23265 SecondaryNameNode
23810 Jps
1971 Application
10951 ResourceManager
22972 NameNode
7406 Bootstrap
12302 NodeManager
浏览器输入你搭建的服务器地址加端口 50070 查看网页版hadoop集群信息
实例:http://127.0.0.1:50070
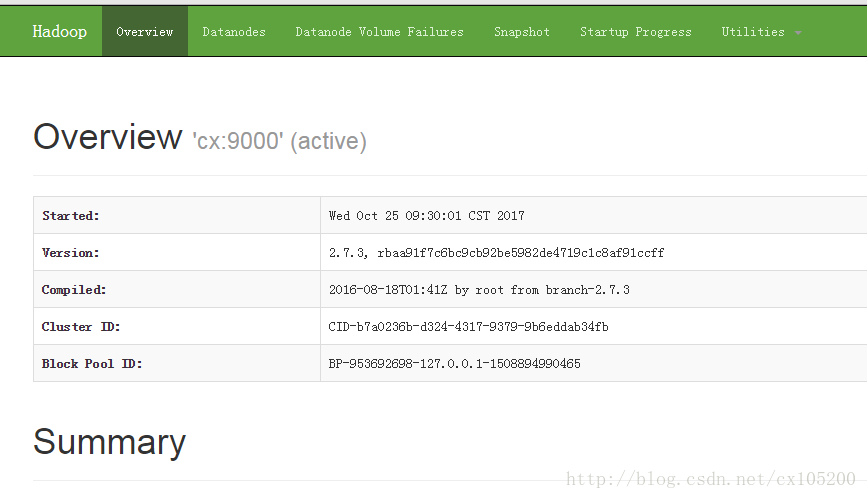
测试
- HDFS测试
建立一个hello.txt 文件,输入命令上传到hadopp并查看
hadoop fs -ls / 查看上传的文件
[root@cx ~]# hadoop fs -put ./hello.txt /
[root@cx ~]# hadoop fs -ls /
Found 1 items
-rw-r--r-- 1 root supergroup 44 2017-10-25 09:30 /hello.txt浏览器上查看
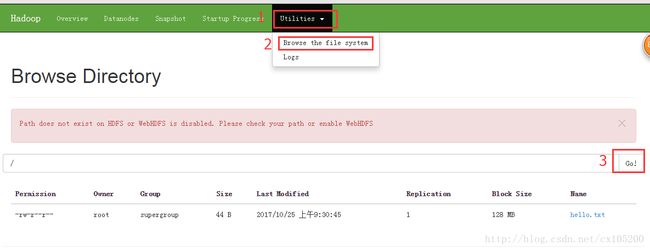
- YARN、Map/Reduce测试
建立一个文本输入以下内容放入到hdfs文件系统里去
hello java
hello java
hello c
hello c++
hello python
hello java这里我建立了一个input.txt放入到 hdfs /input/目录下,使用hadoop提供的demo做词频统计
hadoop fs -mkdir /input
hadoop fs -put /input/input.txt
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/input.txt /output回车后,在http://127.0.0.1:8088 查看该次任务的执行情况
完毕后,在http://127.0.0.1:50070 里查看文件,在/output目录下会有一个_SUCCESS 文件 和 part-r-00000文件
输入命令 hadoop fs -text /input/input.txt 查看输出结果
[root@cx hadoop]# hadoop fs -text /input/input.txt
hello java
hello java
hello c
hello c++
hello python
hello java**
完全分布式搭建
单台hadoop布置完毕后
先给集群机器配置 IP和主机名(有多少加多少)
改主机名参阅 伪分布式第一步
vim /etc/hostname
vim /etc/hosts
reboot
[root@master ~]# cat /etc/hosts
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
192.168.56.105 master1
ssh-keygen -t -rsa 在master上生产私钥公钥
然后把公钥copy到集群主机上,master也需要一份,因为即使是本次操作,对于hadoop而言也是远程登陆操作
[root@master ~]# ssh-copy-id slave1
[root@master ~]# ssh-copy-id slave2
[root@master ~]# ssh-copy-id slave3
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id master1单独配置HDFS
core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/hdfs/tmpvalue>
<description>Abase for other temporary directories.description>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master1:50090value>
property>
property>
hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///usr/local/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///usr/local/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.block.sizename>
<value>3145728value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
slaves
[root@master hadoop]# cat slaves
slave1
slave2
slave3
masters 这个要新建
[root@master hadoop]# cat masters
master1
配置完毕复制配置到每个datanode上
scp -r /usr/local/hadoop/etc/hadoop slave1:/usr/local/hadoop/etc/hadoop
然后 start-dfs.sh启动集群,hdfs文件系统启动
192.168.56.100:50070 查看hdfs集群信息
单独配置启动yarn
yarn的ResourceManager NodeManager配置
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>
集中管理这个不需要所有节点都配置,只需要namenode上配置
[root@master hadoop]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-master.out
slave3: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave3.out
slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave2.out
[root@master hadoop]# jps
2132 ResourceManager
2206 Jps
192.168.56.100:8088(默认端口) 查看yarn集群信息
单独配置启动Map/Reduce
配置 mapred-site.xml
没有的话这个配置文件的话,先从模板复制一份
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
mapreduce默认在本地运行,这里写死在yarn框架上运行。
测试方式和伪分布式运行一样。
浏览器查看Hadoop集群信息:
- HDFS查看
http://127.0.0.1:50070
- YARN查看
http://127.0.0.1:8088
需要下载的安装包:
百度网盘链接:http://pan.baidu.com/s/1mif14Qs 密码:wg7p
如有疑问,请及时联系作者。
安装可能存在问题:
datanode无法启动
多次格式化导致版本不一致,解决办法,删除hdfs/{data,name,tmp} 文件夹,并重新建立HDFS启动不了时,先互相ping,看是否测试成功,若不成功,注意防火墙的影响。关闭windows或虚拟机的防火墙。
systemctl stop firewalld
systemctl disable firewalld未完,待续……
大佬的风向标