【日常】写给妈妈的微信机器人(用于知网论文下载)
最近妈妈工作需求突然要写论文,我长这么大第一次听说就她还能写论文。可惜我不是学医的,这方面跨得太大基本上无能为力,最多给她润色一下。她那边下论文又不方便,我当天连夜赶了一份微信机器人出来,供她下载论文。
实现逻辑非常简单,微信端用itchat,调用之前就编写好的类CNKI,稍加修改就可以满足妈妈在微信上与我交互,我这边可以自动向她展示知网搜索结果,翻页,查看简介,及下载论文再通过微信发送给她。
典型的类前后端架构,前端用itchat编写,代码如下:
前端
基本上考虑了所有的业务逻辑,我简化了一下,就是下载完论文自动退出系统(否则流程分叉太多我觉得也不是很好写);
#-*- coding:UTF-8 -*-
import re
import os
import sys
sys.path.append(r"F:\Programming Software\Python\Project\Project_16(CNKI)")
sys.path.append(r"C:\Users\lenovo\Downloads")
import time
import itchat
from itchat.content import TEXT
from CNKI import CNKI
import json
import numpy
import pandas
import random
from PIL import Image
from requests import Session
from bs4 import BeautifulSoup
from selenium import webdriver
from matplotlib import pyplot as plt
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
""" 设置自动回复 """
global cnki, dialcount, flag1, flag2, flag3, flag4, judge1, judge2, judge3, judge4, page, driver, results, URL
dialcount = 0
flag1 = True # 下一句话是搜索?
flag2 = False # 下一句话是看简介?
flag3 = False # 下一句话是要下载论文?
flag4 = False # 下一句话是要翻页?
judge1 = False # 下一句话是搜索完后的一个判断?
judge2 = False # 下一句话是看完简介后的一个判断?
judge3 = False # 下一句话是下载完后的一个判断?
judge4 = False # 下一句话是搜索完后的一个判断?
driver = None
results = None
page = 1 # 目前在第几页: 处理翻页
URL = None # 记录当前所在URL
string1 = "欢迎使用简化版中国知网系统,请输入你需要查询的关键词!任何时候只要你输入'退出'即可退出当前会话,系统将会重置,你之后可以随时开始一次新的会话。会话中请根据引导信息进行文字输入操作"
string2 = "上面是第{}页的论文信息\n如果需要查看下一页请输入1\n如果重新搜索请输入2\n如果需要查看简介请输入'a+<序号>'\n如果需要下载论文请输入'b+<序号>'".format(page)
string3 = "该论文没有PDF下载选项,如需要下载转人工服务"
string4 = "系统内部逻辑错误,请联系管理员调试代码"
@itchat.msg_register(TEXT,isFriendChat=True,isGroupChat=False,isMpChat=False)
def text_reply(msg):
global cnki, dialcount, flag1, flag2, flag3, flag4, judge1, judge2, judge3, judge4, page, driver, results, URL
#itchat.send_msg("[%s]收到好友@%s 的信息:%s\n" %(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(msg["CreateTime"])),msg["User"]["NickName"], msg["Text"]), "filehelper")
if msg["User"]["NickName"]=="妈妈":
string = msg["Text"]
if dialcount==0:
dialcount = 1
itchat.send_msg("正在启动系统,这可能需要一段时间...",toUserName=msg["FromUserName"])
cnki = CNKI() # 新建类
return string1
elif string=="退出": # 重置会话
try:
dialcount = 0
flag1 = True # 下一句话是搜索?
flag2 = False # 下一句话是看简介?
flag3 = False # 下一句话是要下载论文?
flag4 = False # 下一句话是要翻页?
judge1 = False # 下一句话是搜索完后的一个判断?
judge2 = False # 下一句话是看完简介后的一个判断?
judge3 = False # 下一句话是搜索完后的一个判断?
judge4 = False # 下一句话是搜索完后的一个判断?
driver = None
results = None
page = 1
URL = None
driver.quit()
except:
pass
return "感谢您的使用,欢迎下次再来!"
else:
if flag1: # 处理搜索
results = cnki.search(string)
for i in range(len(results["序号"])):
itchat.send_msg("序号{}\n{}".format(i+1,results["题名"][i]),toUserName=msg["FromUserName"])
judge1 = True
flag1 = False
page = 1
return string2
elif judge1: # 处理搜索后的选择
if string==1: # 下一页?说实话我害怕driver过期就很麻烦
results = cnki.search(string,page=page+1,headless=True) # 查询下一页
for i in range(len(results["序号"])):
itchat.send_msg("序号{}\n{}".format(i+1,results["题名"][i]),toUserName=msg["FromUserName"])
judge1 = True # 仍然是处于搜索后选择的状态
flag1 = False # 可以省略
page += 1
return string2
elif string==2: # 重新搜索
judge1 = False # 取消judge1
flag1 = True # 重新进入搜索
page = 1 # 重置page
return "搜索引擎已重置,请重新输入关键词!"
elif string[0]=="a": # 查看简介
try: index = int(string[1:].strip())
except: return "序号无法转化为整数型, 请重新输入!"
if index<=20 and index>=1:
URL = results["链接"][index-1]
response = cnki.search_for_details(URL)
itchat.send_msg("{}的简介如下:\n".format(results["题名"][index-1],response),toUserName=msg["FromUserName"])
judge1 = False # 取消judge1
judge2 = True # 进入judge2
return "简介如上!如需下载该论文请输入1, 如需翻页请按2, 重新搜索请按3"
else:
return "序号不在范围内(1~20), 请重新输入!"
elif string[0]=="b": # 下载文件
try: index = int(string[1:].strip())
except: return "序号无法转化为整数型, 请重新输入!"
if index<=20 and index>=1:
flag = cnki.download(results["链接"][index-1]) # 下论文了呗
if flag==0:
itchat.send_msg(string3,toUserName=msg["FromUserName"])
return "请重新输入您要进行的操作"
elif flag==1:
itchat.send_msg(string4,toUserName=msg["FromUserName"])
return "请重新输入您要进行的操作"
else:
itchat.send_file("F:\Temp\{}.pdf".format(flag),toUserName=msg["FromUserName"])
try:
dialcount = 0
flag1 = True # 下一句话是搜索?
flag2 = False # 下一句话是看简介?
flag3 = False # 下一句话是要下载论文?
flag4 = False # 下一句话是要翻页?
judge1 = False # 下一句话是搜索完后的一个判断?
judge2 = False # 下一句话是看完简介后的一个判断?
judge3 = False # 下一句话是搜索完后的一个判断?
judge4 = False # 下一句话是搜索完后的一个判断?
driver = None
results = None
page = 1
URL = None
driver.quit()
except:
pass
return "下载完毕!系统已退出!"
else:
return "序号不在范围内(1~20), 请重新输入!"
elif judge2: # 查看简介后的judge
if string=="1":
flag = cnki.download(URL) # 下论文了呗
if flag==0:
itchat.send_msg(string3,toUserName=msg["FromUserName"])
return "请重新输入您要进行的操作"
elif flag==1:
itchat.send_msg(string4,toUserName=msg["FromUserName"])
return "请重新输入您要进行的操作"
else:
itchat.send_file("F:\Temp\{}.pdf".format(flag),toUserName=msg["FromUserName"])
try:
dialcount = 0
flag1 = True # 下一句话是搜索?
flag2 = False # 下一句话是看简介?
flag3 = False # 下一句话是要下载论文?
flag4 = False # 下一句话是要翻页?
judge1 = False # 下一句话是搜索完后的一个判断?
judge2 = False # 下一句话是看完简介后的一个判断?
judge3 = False # 下一句话是搜索完后的一个判断?
judge4 = False # 下一句话是搜索完后的一个判断?
driver = None
results = None
page = 1
URL = None
driver.quit()
except:
pass
return "下载完毕!系统已退出!"
pass
elif string=="2": # 翻页
results = cnki.search(string,page=page+1,headless=True) # 查询下一页
for i in range(len(results["序号"])):
itchat.send_msg("序号{}\n{}".format(i+1,results["题名"][i]),toUserName=msg["FromUserName"])
judge1 = True # 仍然是处于搜索后选择的状态
judge2 = False # 可以省略
page += 1
return string2
elif string=="3": # 重新搜索
judge1 = False # 取消judge1
flag1 = True # 重新进入搜索
page = 1 # 重置page
return "搜索引擎已重置,请重新输入关键词!"
else:
return "您输入的不是1,2,3,请重新输入"
if __name__ == "__main__":
itchat.auto_login()
itchat.run()
后端
后端主要就是CNKI类,被前端调用,这里我也不说太多,因为代码基本上也很难在其他计算机上跑起来,我写的比较硬,因为赶时间,妈妈急着要,我就记几个坑:
一
知网的搜索结果是被iframe给封装了,所以用selenium时要用switch_to_frame方法先进入iframe才能拿到搜索结果的html;说实话这个问题坑了我很长时间,因为我一直搞不清楚为什么不能获取到搜索结果的html,明明元素都能定位的到;
二
知网的搜索结果中的论文题目的标签中的href超链接地址是没有用的,点进去直接返回知网首页(比如你右键这个论文题目的超链接,选择打开链接,将直接返回知网首页)会重定向应该是,我看了一下只有URLID之后那串神秘代码是有用的,你们可以自己看看,每个论文所在
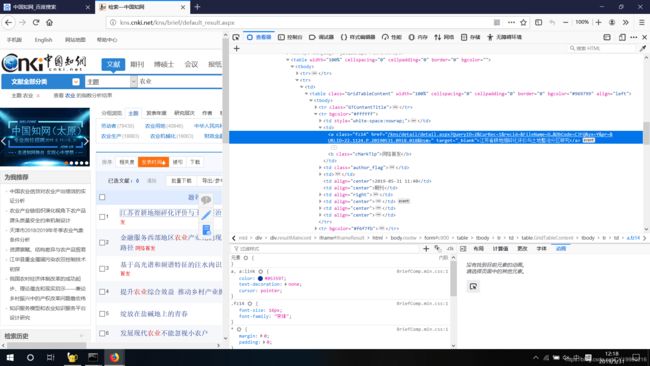
三
完事点击进来就下载PDF咯,妈妈太笨,只能给她全部弄好,CAJ又不会看,只能把PDF打印出来咯。这里因为下载会有弹窗,我想的办法是用pykeyboard模拟敲击ENTER键下载。我看到的办法还有就是对webdriver进行set_preference,但是我发现无论我怎么设定,webdriver都没有变化(比如设定默认下载路径,禁止弹窗之类的),无奈只能让它下到默认路径再剪切到我要的路径上来了。。。
self.profile = webdriver.FirefoxProfile()
profile.set_preference("browser.download.folderList", 2)
profile.set_preference("browser.download.dir", "d:\\tmp") # 下载路径
option.set_preference("dom.webnotifications.enabled",False) # 不弹窗(指一个窗口只能有一个标签页)
browser = webdriver.Firefox(option)给个CNKI的类吧,可能会跑不起来,反正我能跑就完事了。爬虫还是要自己写的
#-*- coding:UTF-8 -*-
import re
import os
import sys
import time
import json
import numpy
import pandas
import random
from PIL import Image
from requests import Session
from bs4 import BeautifulSoup
from selenium import webdriver
from matplotlib import pyplot as plt
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from pykeyboard import PyKeyboard
class CNKI():
def __init__(self,
userAgent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0",
): # 构造函数
""" 类构造参数 """
self.userAgent = userAgent
""" 类常用参数 """
self.workspace = os.getcwd() # 类工作目录
self.date = time.strftime("%Y%m%d") # 类构造时间
self.mainURL = "http://www.cnki.net/" # 中国知网主页
self.searchURL = "http://kns.cnki.net/kns/brief/default_result.aspx"
self.options = webdriver.FirefoxOptions() # 火狐驱动配置
self.profile = webdriver.FirefoxProfile()
self.session = Session() # 初始化一个可能需要用得到的session: CNKI反爬虫仍然很强势, requests包不太好办
self.headers = {"User-Agent": userAgent} # 设置请求头
self.downloadFolder = "download" # 下载文件夹
self.tempFolder = "temp" # 存储临时文件的文件夹
self.labelCompiler = re.compile(r"<[^>]+>",re.S) # 标签正则编译
""" 类初始化 """
self.session.headers = self.headers.copy()
self.session.get(self.mainURL) # 定位中国知网主页
#self.profile.set_preference("dom.webnotifications.enabled",False)
self.profile.set_preference("browser.download.folderList",2);
self.profile.set_preference("browser.download.dir","{}\\{}".format(self.workspace,self.downloadFolder))
#self.profile.set_preference("browser.helperApps.neverAsk.saveToDisk","pdf,caj");
#self.profile.set_preference("browser.link.open_newwindow",3)
if not os.path.exists("{}\\{}".format(self.workspace,self.downloadFolder)):
string = "正在新建文件夹以存储下载文件..."
print(string)
os.mkdir("{}\\{}".format(self.workspace,self.downloadFolder))# 新建文件夹存储下载文件
if not os.path.exists("{}\\{}".format(self.workspace,self.tempFolder)):
string = "正在新建文件夹以存储临时文件..."
print(string)
os.mkdir("{}\\{}".format(self.workspace,self.tempFolder)) # 新建文件夹存储临时文件
def search_for_details(self,url):
html = self.session.get(url).text
soup = BeautifulSoup(html,"lxml")
div = soup.find("div",class_="wxBaseinfo")
response = str()
for p in div.find_all("p"):
string = labelCompiler.sub("",str(p)).replace("\n","").replace("\t","")
response += "{}\n".format(string)
if string[:3] == "分类号": break
return response
def search(self,keyword,
headless=False,
page=1,
):
options = self.options.add_argument("--headless") if headless else self.options
driver = webdriver.Firefox(self.profile)
driver.implicitly_wait(10) # 设置等待超时
driver.get(self.searchURL)
driver.find_element_by_xpath("//input[@class='rekeyword']").send_keys(keyword)
driver.find_element_by_xpath("//input[@class='researchbtn']").click()
driver.switch_to_frame("iframeResult")
if page==1:
html = driver.find_element_by_xpath("//table[@width='100%' and @cellspacing='0' and @border='0' and @bgcolor='']").get_attribute("innerHTML")
soup = BeautifulSoup(html,"lxml")
aLabels = soup.find_all("a",class_="fz14")
results = {
"序号": [],
"题名": [],
"链接": [],
}
for i in range(len(aLabels)):
results["序号"].append(i+1)
title = self.labelCompiler.sub("",str(aLabels[i])).strip("\n").strip("\t").strip()
results["题名"].append(title)
href = aLabels[i].attrs["href"] # 这个链接是个伪链接, 如果打开它则会重定向回主页, 但是里面有一部分字段是有用的, 我找规律找出了这段有用的字段
index1 = href.find("URLID")
index2 = href.find("&",index1)
trueURL = "http://kns.cnki.net/KCMS/detail/{}.html".format(href[index1+6:index2])
results["链接"].append(trueURL)
return results,driver
else:
driver.find_element_by_xpath("//a[text()='{}']".format(i)).click()
html = driver.find_element_by_xpath("//table[@width='100%' and @cellspacing='0' and @border='0' and @bgcolor='']").get_attribute("innerHTML")
soup = BeautifulSoup(html,"lxml")
aLabels = soup.find_all("a",class_="fz14")
results = {
"序号": [],
"题名": [],
"链接": [],
}
for i in range(len(aLabels)):
results["序号"].append(i+1)
title = self.labelCompiler.sub("",str(aLabels[i])).strip("\n").strip("\t").strip()
results["题名"].append(title)
href = aLabels[i].attrs["href"] # 这个链接是个伪链接, 如果打开它则会重定向回主页, 但是里面有一部分字段是有用的, 我找规律找出了这段有用的字段
index1 = href.find("URLID")
index2 = href.find("&",index1)
trueURL = "http://kns.cnki.net/KCMS/detail/{}.html".format(href[index1+6:index2])
results["链接"].append(trueURL)
driver.quit()
return results
def download(self,url,
headless=False,
default_download_path=r"C:\Users\lenovo\Downloads",
download_path=r"F:\Temp",
):
k = PyKeyboard()
options = self.options.add_argument("--headless") if headless else self.options
driver = webdriver.Firefox(self.profile,options=options) if headless else webdriver.Firefox(self.profile)
driver.get(url)
try: driver.find_element_by_id("pdfDownF").click()
except:
return 0 # return 0 是没有pdf下载的选项
count = 0
while True:
if count==0: time.sleep(5.) # 第一次等5秒
else: time.sleep(1.) # 之后等1秒
k.tap_key(13) # 敲击回车键
isFile = len(list(os.walk(default_download_path))[0][2]) # 看看默认路径下有几个文件
if isFile==0: # 没下好, 继续下
count += 1
continue
elif isFile==1:
rename = time.strftime("%Y%m%d%H%M%S")
os.system(r"rename {}\*.pdf {}\{}.pdf".format(default_download_path,default_download_path,rename))
os.system(r"move *.pdf {}".format(download_path)) # 移动到下载路径(不能有空格)
driver.quit()
return rename
else: #
driver.quit()
return 1 # return 1 是系统逻辑错误
if __name__=="__main__":
cnki = CNKI()
#cnki.search("农业")
cnki.download("http://kns.cnki.net/KCMS/detail/44.1267.S.20190529.1324.004.html")
分享学习,共同进步!