Python高级可视化库seaborn回归分析(基础整理)
探索变量间的关系
两个变量:lmplot,绘制回归模型
(1.1)两个维度数据都是连续的:散点图 + 线性回归 + 95%置信区间
(1.2)一个维度数据是连续的,一个维度数据是离散的,连续轴抖动x_jitter参数
(1.3)x_estimator参数将“离散取值维度”用均值和置信区间代替散点
拟合不同模型
(1.1)lmplot默认参数线性拟合
(1.2)lmplot的order参数,设置高阶拟合
(1.3)lmplot的robust参数,设置抗噪声鲁棒性
(1.4)lmplot的logistic参数,设置拟合曲线是logistic(二类分类模型)
某特征内部分组对比
(1.1)lmplot的hue参数按cloumns分组,一图多组
(1.2)lmplot的hue参数按cloumns分组,加col参数——列增加,加row参数——行增加
(1.3)lmplot的col参数分出来多组后,col_wrap参数控制图形显示排布;size参数设置图形大小,aspect参数设置图形横纵比
——————————————————————————————————
探索变量间的关系
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
np.random.seed(sum(map(ord, "regression")))
tips = sns.load_dataset("tips")
tips.head()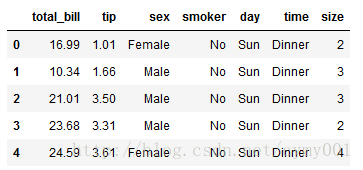
两个变量:lmplot,绘制线性回归模型
(1.1)两个维度数据都是连续的:散点图 + 线性回归 + 95%置信区间
sns.lmplot(x="total_bill", y="tip", data=tips)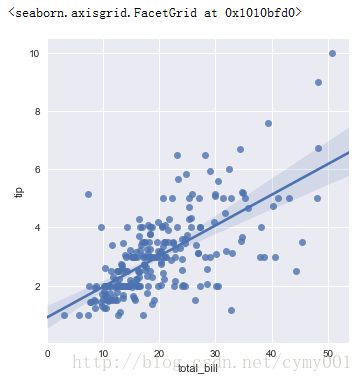
(1.2)一个维度数据是连续的,一个维度数据是离散的,连续轴抖动x_jitter参数
sns.lmplot(x="size", y="tip", data=tips, x_jitter=.08)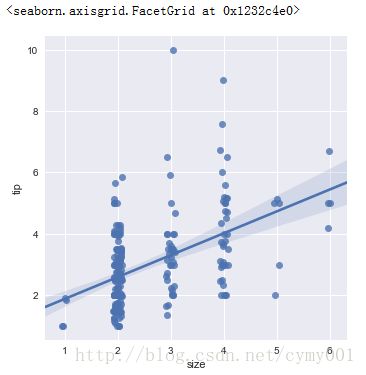
(1.3)x_estimator参数将“离散取值维度”用均值和置信区间代替散点
sns.lmplot(x="size", y="tip", data=tips, x_estimator=np.mean)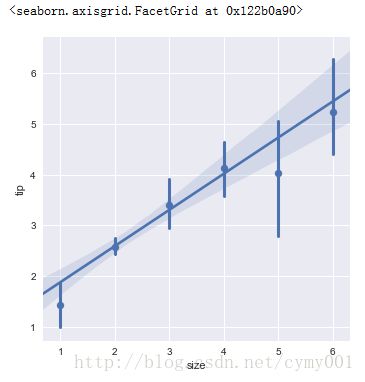
拟合不同模型
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
anscombe = sns.load_dataset("anscombe")
anscombe.groupby('dataset').groups
#输出类别:
{'I': Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype='int64'),
'II': Int64Index([11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype='int64'),
'III': Int64Index([22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32], dtype='int64'),
'IV': Int64Index([33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43], dtype='int64')}(1.1)lmplot默认参数线性拟合
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
anscombe = sns.load_dataset("anscombe")
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),\
ci=None, scatter_kws={"s": 80})
#anscombe.query("dataset == 'I'")是取anscombe
#ci默认值95,Size of the confidence interval for the regression estimate.Bootstrap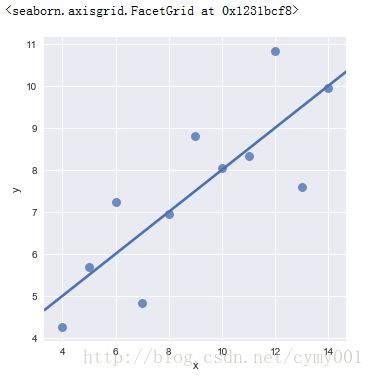
(1.2)lmplot的order参数,设置高阶拟合
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"), \
order=2, ci=None, scatter_kws={"s": 80}) #lmplot默认order参数是一阶的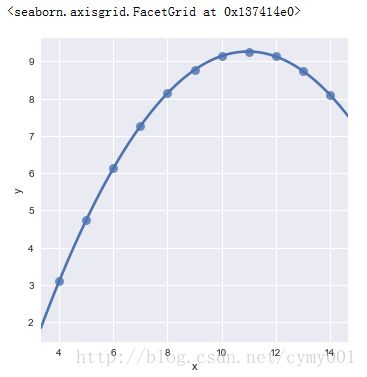
(1.3)lmplot的robust参数,设置抗噪声鲁棒性
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"), \
robust=True, ci=None, scatter_kws={"s": 80})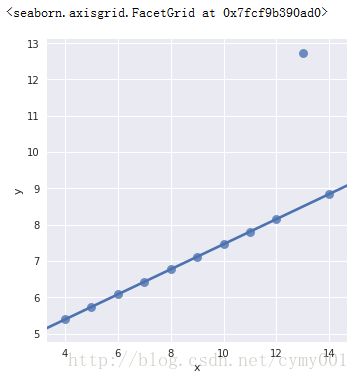
(1.4)lmplot的logistic参数,设置拟合曲线是logistic(二类分类模型)
sns.lmplot(x="total_bill", y="big_tip", data=tips, \
logistic=True, y_jitter=.03, ci=None)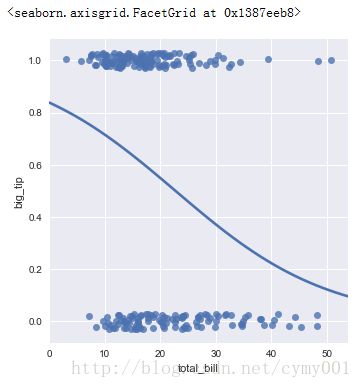
(2)residplot评价不同模型拟合效果,画残差曲线(对比一阶拟合直线的残差)
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
anscombe = sns.load_dataset("anscombe")
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'I'"), scatter_kws={"s": 80})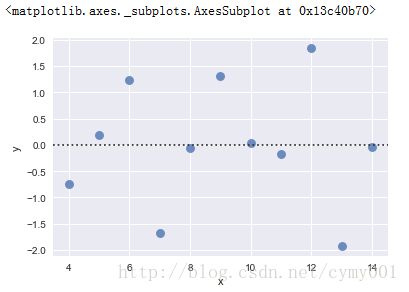
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'II'"), scatter_kws={"s": 80})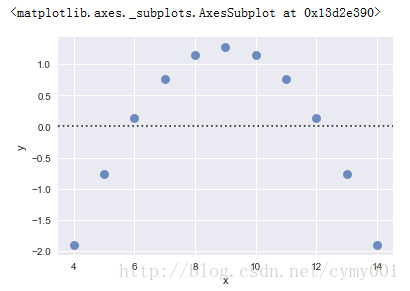
某特征内部分组对比
(1.1)lmplot的hue参数按cloumns分组,一图多组
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
np.random.seed(sum(map(ord, "regression")))
tips = sns.load_dataset("tips")
sns.lmplot(x="total_bill", y="tip", hue="day", data=tips)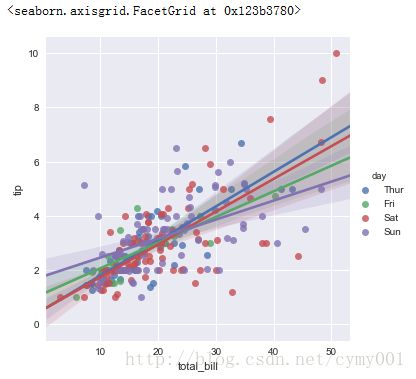
(1.2)lmplot的hue参数按cloumns分组,加col参数——列增加,加row参数——行增加
sns.lmplot(x="total_bill", y="tip", hue="smoker", col="time", row="sex", data=tips, markers=["o", "x"], size=3)
#markers参数标示实例点,size参数控制图形大小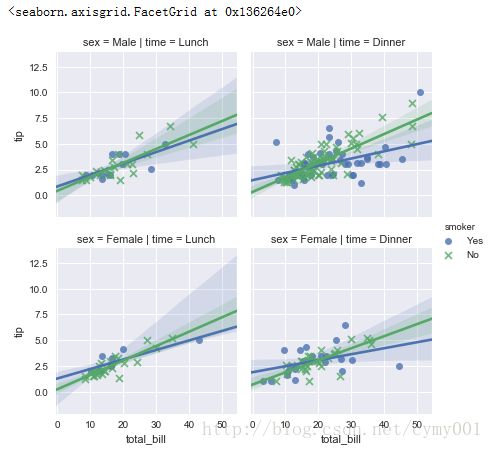
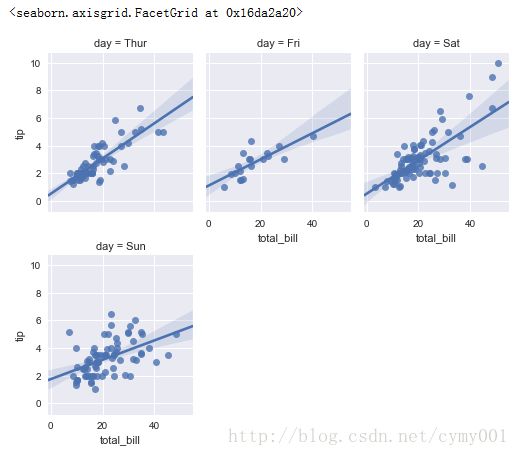
(1.3)lmplot的col参数分出来多组后,col_wrap参数控制图形显示排布;size参数设置图形大小,aspect参数设置图形横纵比
sns.lmplot(x="total_bill", y="tip", col="day", data=tips, col_wrap=3, size=3, aspect=0.8)#