从AlexNet到DenseNet,再到SENet,一文看懂图像分类领域的突破性进展

本文转自将门创投(thejiangmen)
来源 | ParallelDots
编译 | Tom Ren
深度学习模型近年来在图像分类领域的能力得到了指数级的提升,并成为了AI领域最为活跃的研究领域。但其实深度学习的历史并不长,Yann Lecun在1998年的时候发表了卷积神经网络的前言探索,但是在深度学习真正爆发之前经历了多年的沉积。
几年来深度学习的爆发归功于机器处理能力的大幅提升(GPU),以及海量的数据(Imagenet)和先进的算法技术。这一次深度学习的革命兴起于2012年的AlexNet,这一大规模的深度卷积神经网络赢得了当年ILSVRC的冠军。(ILSVRC是一个在给定数据级上进行特定视觉识别任务的算法挑战赛。)从那时起,CNN家族就拿下了这一比赛,并超过了人类视觉5%~10%的准确率水平。
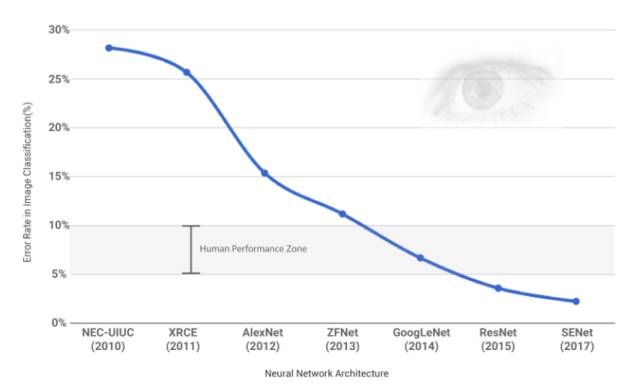
ILSVRC比赛见证了神经网络性能的不断提升,从2010年接近30%的错误率提升到了今年2.251%的错误率。
对于人类而言,理解一张图片的内容很容易,但是对于机器来说却很困难。因为机器面对的一个由数组构成的图片,从一堆数字里识别出猫的模样是十分困难的事情。更别提猫还有不同种类、毛色、大小和姿态了。
 我们看见的 vs 机器看见的世界
我们看见的 vs 机器看见的世界
深度学习经过了四五年的发展,衍生出了各种各样不同的架构并取得一系列的突破。我们列举了这一领域曾经发生的一系列突破性研究,来为大家呈现出深度学习的发展脉络。最后我们提出了两个全新的算法,也许未来会对计算机视觉的研究带来新的变革。
▌图像分类研究领域的突破性研究论文
AlexNet
在ILSVRC2012中, Alex Krizhevsky, Ilya Sutskever, 和 Geoffrey Hinton 提出了名为AlexNet的深度神经网络,它首次达到了15.4%的错误率,比当时的第二名整整低了10%。Alexnet这一令人瞩目的成就极大地震动了整个计算机视觉领域,并直接带了近年来深度学习和卷积网络的爆发性增长。
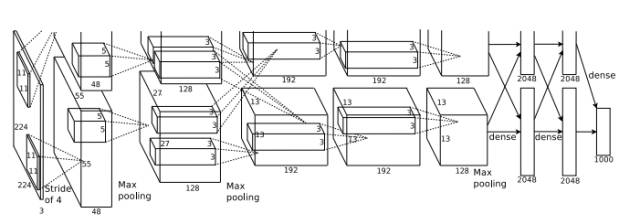
AlexNet在两个GPU上分别部署的架构图
这是历史上第一次模型能在曾经如此困难的ImageNet的数据集上表现如此之好,AlexNet同时也奠定了深度学习里程碑式的基础。这篇文章也是迄今为止深度学习引用最高的文章之一,约7000次。
ZFNet
Matthew D Zeiler(Clarifai的创始人) 和 Rob Fergus 赢得了ILSVRC 2013的比赛,其准确率超过了AlexNet达到了11.2%的错误率。ZFNet在模型中引入了新颖的可视化技术,给予了研究人员对于中间特征层以及分类器操作更多的解读,弥补了AlexNet在这方面的不足。
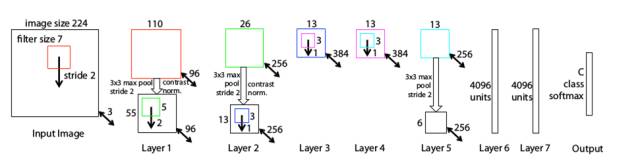
ZFNet网络架构
ZFNet 利用解卷积网络的技术使得检验不同特征激活及其与输入空间的关系成为了可能。
VGG Net
来自于牛津大学的Karen Simonyan 和 Andrew Zisserman于2014年创造的VGGnet在2014年ISLVRC上取得了第二名的优秀结果。VGGnet展示了可以在先前网络架构的基础上通过增加网络层数和深度来提高网络的性能。VGGnet包含16-19层权重网络,比先前的网络架构更深层数更多。
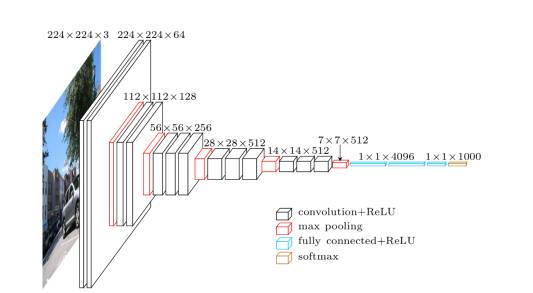 MVGG Net.的架构
MVGG Net.的架构
这一架构广受好评的原因来自于它简单的结构,更易于理解,但是依旧拥有可以优化的空间。它的特征图目前被广泛应用于迁移学习和其他需要与训练的网络结构中,例如绝大多数的GANs。
GoogleNet
来自Google的Christian Szegedy等人提出了称为GoogleNet的22层神经网络赢得了14年ISLVRC的冠军。这错误率只有6.7%的模型奠定了Google在计算机视觉领域的地位。这一模型最引人注目的地方在于模型架构极大的改善了计算机计算资源的利用率,在精心设计的网络下,模型的计算开销在深度和宽度增加的情况下保持常数。GoogleNet在模型中引入了Inception Module,利用非序列化的并行方式来提高模型的性能。
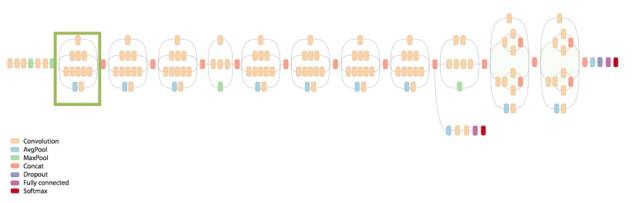
GoogLeNet 的架构和其中的 inception 单元
GoogleNet令人瞩目的是其识别准确率已经达到了人类的水平(5%~10%)。GoogleNet第一次引入了CNN模块的非序列化概念,Inception-module提供了一种更具创造性的结构,并能极大提高模型表现和计算效率。
ResNet
微软的Kaiming He, Xiangyu Zhang, Shaoqing Ren 和 Jian Sun提出了ResNet,这是一个比先前网络都要深的残差网络学习框架。这一网络的优点是更加容易优化,并能从网络层数的增加带来显著的精度提升。
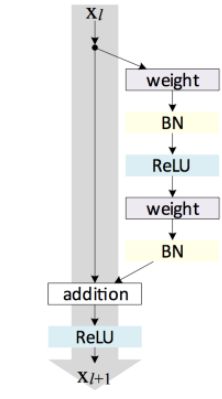
ResNet架构中的残差单元
ResNet以3.57%的表现超过了人类的识别水平,并以152层的网络架构创造了新的模型记录。
Wide ResNets
Sergey Zagoruyko 和Nikos Komodakis 在仔细研究分析ResNet的基础上,提出了一种新颖的模型架构。他们通过减小残差神经网络的深度并扩大网络的宽度得到了一种能够更充分使用模型特征的残差网络。虽然有人表示这种网络容易过拟合,但是它确实有效。
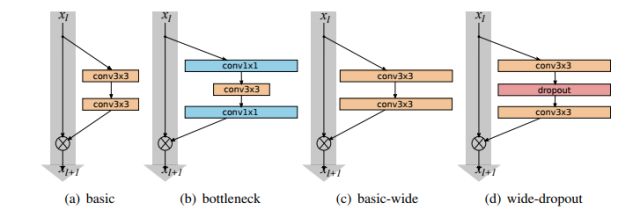
Various residual blocks used by the authors
作者将这一网络命名为宽残差神经网络(WRNs),并展示了其相较于超过很深很细架构的优势。相较于ResNet,其卷基层中拥有2-12x丰富的特征图。
ResNeXt
ResNeXt赢得了ILSCRV2016的第二名的成绩,它是一个用于图像分类的高度模块化网络。这一网络架构设计的均匀多分支的网络结构中仅仅只需要设置很少的几个超参数。
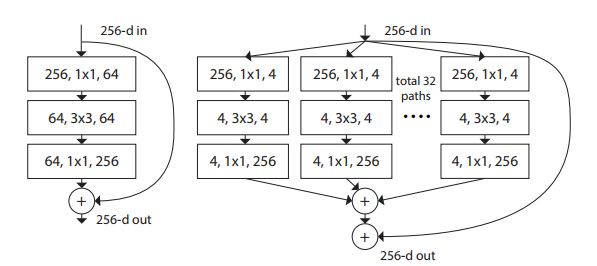 ResNet(Left)单元与ResNeXt单元的比较(右)
ResNet(Left)单元与ResNeXt单元的比较(右)
这一网络对于新进维度的策略是基于一种称为“基数”(进行变化序列的大小)的基本模块展开的。这一网络证明增加“基数”模块比单纯的增加深度和宽度更有效。所以这一网络结构的精度要高于ResNet和WideResNet。
DenseNet
Gao Huang, Zhuang Liu, Kilian Q. Weinberger 和Laurens van der Maaten于2016年提出了密集卷积神经网络DenseCNN的概念,在前馈过程中将每一层与其他的层都链接起来。对于每一层网络来说,前面所有网络的特征图都被作为输入,同时其特征图也都被其他网络层作为输入所利用。
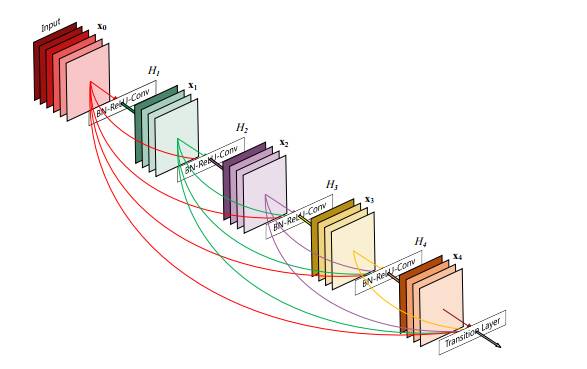
5层的致密网络,每一层将所有层都视为自己的输入
DenseCNN具有很多的有点,包括缓解梯度消失的问题,强化特征传播和特征的复用,并减少了参数的数目。DenseNet相较于ResNet所需的内存和计算资源更少,并达到更好的性能。
▌两个有前景的的新架构
新的模型层出不穷,其中Attention Modules和SENet是值得我们关注的新型模型。
SENet
在ILSCRV2017上取得冠军的缩聚-激发网络(SENet),包含特征压缩、激发(特征通道权重计算)和重配权重等过程,如下图所示。在不引入新的空间维度的前提下这种架构使用了“特征重标定”的策略来对特征进行处理。通过学习获取每个特征通道的重要程度,根据重要性去抑制或者提升相应的特征,最终在今年的比赛测试集中实现了2.251%的Top-5错误率。
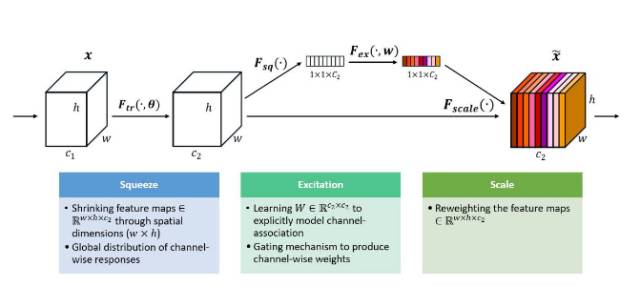
SENet 模型示意图: Squeeze, Excitation 和 Scaling Operations
Residual Attention Networks
残差注意力网络是一种应用了注意力机制的卷积神经网络,可将最先进的前馈网络架构融合到端到端的训练过程中。注意力残差学习被用于十分深的残差注意力网络(这种网络可以达到几百层的规模)。

Resi双注意力网络分类示意图:上述的图像显示了不同特征在残差注意力网络中用于不同的相应。天空部分的掩膜 减小了底层背景蓝色特征,二气球掩膜的实例则强调了气球底部的高级特征。
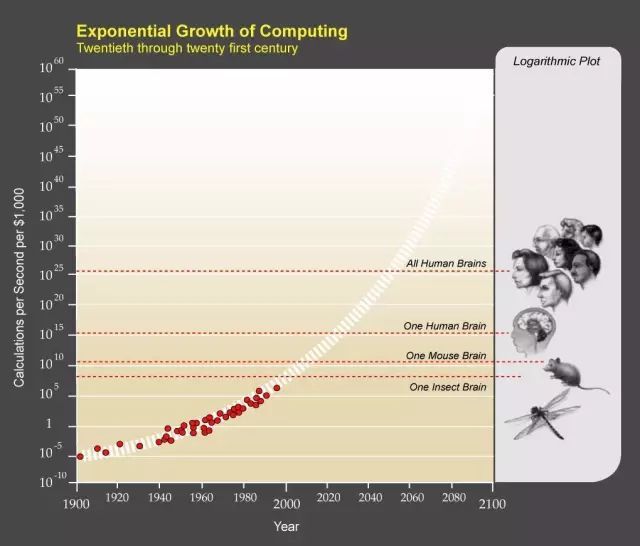
现在,每1000$可以买到的计算机处理能力大概相当于人脑的1/1000。根据摩尔定律,我们可以在2025年达到人脑的水平并在2050年超过所有人类的水平。AI的能力必将会随时间加速增长。随着机器处理能力的不断提高和越来越多的数据,深度学习研究必将会更迅猛的发展,算法的精度和能力也将会越来越高。作为AI领域的前线打拼者,我们正在见证和参与着这一激动人心的变革。
新一年,AI科技大本营的目标更加明确,有更多的想法需要落地,不过目前对于营长来说是“现实跟不上灵魂的脚步”,因为缺人~~
所以,AI科技大本营要壮大队伍了,现招聘AI记者和资深编译,有意者请将简历投至:[email protected],期待你的加入!
如果你暂时不能加入营长的队伍,也欢迎与营长分享你的精彩文章,投稿邮箱:[email protected]
如果以上两者你都参与不了,那就加入AI科技大本营的读者群,成为营长的真爱粉儿吧!(无法加入?请添加营长微信1092722531)





☟☟☟点击 | 阅读原文 | 查看更多精彩内容