Variable和Tensor合并后,PyTorch的代码要怎么改?
昨日(4 月 25 日),Facebook 推出了 PyTorch 0.4.0 版本,该版本有诸多更新和改变,比如支持 Windows,Variable 和 Tensor 合并等等,详细介绍请查看文章《Pytorch 重磅更新》。
本文是一篇迁移指南,将介绍从先前版本迁移到新版本时,所需做出的一些代码更改:
Tensors/Variables 合并
支持零维(标量)张量
弃用 volatile 标志
dtypes,devices 和 Numpy-style Tensor 创建函数
编写一些不依赖设备的代码
▌合并 Tensor 和 Variable 类
新版本中,torch.autograd.Variable 和 torch.Tensor 将同属一类。更确切地说,torch.Tensor 能够追踪日志并像旧版本的 Variable 那样运行; Variable 封装仍旧可以像以前一样工作,但返回的对象类型是 torch.Tensor。这意味着你的代码不再需要变量封装器。
Tensor 中 type () 的变化
这里需要注意到张量的 type()不再反映数据类型,而是改用 isinstance() 或 x.type() 来表示数据类型,代码如下:
x = torch.DoubleTensor([1, 1, 1])print(type(x)) # was torch.DoubleTensor"
autograd 用于跟踪历史记录
作为 autograd 方法的核心标志,requires_grad 现在是 Tensors 类的一个属性。让我们看看这个变化是如何体现在代码中的。autograd 使用先前用于 Variable 的相同规则。当操作中任意输入 Tensor 的 require_grad = True 时,它开始跟踪历史记录。代码如下所示:
> x = torch.ones(1) # create a tensor with requires_grad=False (default)
> x.requires_grad
False
> y = torch.ones(1) # another tensor with requires_grad=False
> z = x + y
> # both inputs have requires_grad=False. so does the output
> z.requires_grad
False
> # then autograd won't track this computation. let's verify!
> z.backward()
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
>
>>> # now create a tensor with requires_grad=True
> w = torch.ones(1, requires_grad=True)
> w.requires_grad
True
> # add to the previous result that has require_grad=False
> total = w + z
> # the total sum now requires grad!
> total.requires_grad
True
> # autograd can compute the gradients as well
> total.backward()
> w.grad
tensor([ 1.])
> # and no computation is wasted to compute gradients for x, y and z, which don't require grad
> z.grad == x.grad == y.grad == None
True
requires_grad 操作
除了直接设置属性之外,你还可以使用 my_tensor.requires_grad_(requires_grad = True) 在原地更改此标志,或者如上例所示,在创建时将其作为参数传递(默认为 False)来实现,代码如下:
> existing_tensor.requires_grad_()> existing_tensor.requires_gradTrue> my_tensor = torch.zeros(3, 4, requires_grad=True)> my_tensor.requires_gradTrue
关于 .data
.data 是从 Variable 中获取底层 Tensor 的主要方式。 合并后,调用 y = x.data 仍然具有相似的语义。因此 y 将是一个与 x 共享相同数据的 Tensor,并且 requires_grad = False,它与 x 的计算历史无关。
然而,在某些情况下 .data 可能不安全。 对 x.data 的任何更改都不会被 autograd 跟踪,如果在反向过程中需要 x,那么计算出的梯度将不正确。另一种更安全的方法是使用 x.detach(),它将返回一个与 requires_grad = False 时共享数据的 Tensor,但如果在反向过程中需要 x,那么 autograd 将会就地更改它。
▌零维张量的一些操作
先前版本中,Tensor 矢量(1维张量)的索引将返回一个 Python 数字,但一个Variable矢量的索引将返回一个大小为(1,)的矢量。同样地, reduce函数存在类似的操作,即tensor.sum()会返回一个Python数字,但是 variable.sum()会调用一个大小为(1,)的向量。
幸运的是,新版本的PyTorch中引入了适当的标量(0维张量)支持! 可以使用新版本中的 torch.tensor 函数来创建标量(这将在后面更详细地解释,现在只需将它认为是PyTorch 中 numpy.array 的等效项),代码如下:
> torch.tensor(3.1416) # create a scalar directly
tensor(3.1416)
> torch.tensor(3.1416).size() # scalar is 0-dimensional
torch.Size([])
> torch.tensor([3]).size() # compare to a vector of size 1
torch.Size([1])
>
>>> vector = torch.arange(2, 6) # this is a vector
> vector
tensor([ 2., 3., 4., 5.])
> vector.size()
torch.Size([4])
> vector[3] # indexing into a vector gives a scalar
tensor(5.)
> vector[3].item() # .item() gives the value as a Python number
5.0
> mysum = torch.tensor([2, 3]).sum()
> mysum
tensor(5)
> mysum.size()
torch.Size([])
累计损失函数
考虑在 PyTorch0.4.0 版本之前广泛使用的 total_loss + = loss.data [0] 模式。Loss 是一个包含张量(1,)的 Variable,但是在新发布的 0.4.0 版本中,loss 是一个 0维标量。 对于标量的索引是没有意义的(目前的版本会给出一个警告,但在0.5.0中将会报错一个硬错误):使用 loss.item()从标量中获取 Python 数字。
值得注意得是,如果你在累积损失时未能将其转换为 Python 数字,那么程序中的内存使用量可能会增加。这是因为上面表达式的右侧,在先前版本中是一个 Python 浮点型数字,而现在它是一个零维的张量。因此,总损失将会张量及其历史梯度的累加,这可能会需要更多的时间来自动求解梯度值。
▌弃用volatile
新版本中,volatile 标志将被弃用且不再会有任何作用。先前的版本中,任何涉及到 volatile = True 的 Variable 的计算都不会由 autograd 追踪到。这已经被一组更灵活的上下文管理器所取代,包括 torch.no_grad(),torch.set_grad_enabled(grad_mode)等等。代码如下:
x = torch.zeros(1, requires_grad=True)with torch.no_grad(): y = x * 2y.requires_gradFalse>>>is_train = Falsewith torch.set_grad_enabled(is_train): y = x * 2y.requires_gradFalsetorch.set_grad_enabled(True) # this can also be used as a functiony = x * 2y.requires_gradTruetorch.set_grad_enabled(False)y = x * 2y.requires_gradFalse
▌dtypes,devices和Numpy式Tensor创建函数
在先前版本的 PyTorch 中,我们通常需要指定数据类型(例如 float vs double),设备类型(cpu vs cuda)和布局(dense vs sparse)作为“张量类型”。例如, torch.cuda.sparse.DoubleTensor 是 Tensor 类的 double 数据类型,用在 CUDA 设备上,并具有 COO 稀疏张量布局。
在新版本中,我们将引入 torch.dtype,torch.device 和 torch.layout 类,以便通过 NumPy 风格的创建函数来更好地管理这些属性。
torch.dtype
以下给出可用的 torch.dtypes(数据类型)及其相应张量类型的完整列表。
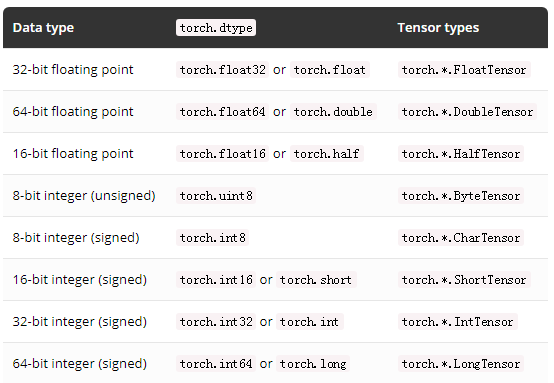
使用 torch.set_default_dtype 和 torch.get_default_dtype 来操作浮点张量的默认 dtype。
torch.device
torch.device 包含设备类型('cpu'或'cuda')及可选的设备序号(id)。它可以通过 torch.device('{device_type}') 或 torch.device('{device_type}:{device_ordinal}')来初始化所选设备。
如果设备序号不存在,则用当前设备表示设备类型:例如,torch.device('cuda')等同于 torch.device('cuda:X'),其中 x 是 torch.cuda.current_device()的结果。
张量所使用的设备可以通过访问 device 属性获取。
torch.layout
torch.layout 表示张量的数据布局。新版本中,torch.strided(密集张量)和torch.sparse_coo(带有 COO 格式的稀疏张量)均受支持。
张量的数据布局模式可以通过访问 layout 属性获取。
创建张量
新版本中,创建 Tensor 的方法还可以使用 dtype,device,layout 和 requires_grad 选项在返回的 Tensor 中指定所需的属性。代码如下:
> device = torch.device("cuda:1")
> x = torch.randn(3, 3, dtype=torch.float64, device=device)
tensor([[-0.6344, 0.8562, -1.2758],
[ 0.8414, 1.7962, 1.0589],
[-0.1369, -1.0462, -0.4373]], dtype=torch.float64, device='cuda:1')
> x.requires_grad # default is False
False
> x = torch.zeros(3, requires_grad=True)
> x.requires_grad
True
torch.tensor(data, …)
torch.tensor 是新添加的张量创建方法之一。它像所有类型的数据一样排列,并将包含值复制到一个新的 Tensor 中。如前所述,PyTorch 中的 torch.tensor 等价于 NumPy 中的构造函数 numpy.array。与 torch.*tensor 方法不同的是,你也可以通过这种方式(单个 Python 数字在 torch.*tensor 方法中被视为大小)创建零维张量(也称为标量)。此外,如果没有给出 dtype 参数,它会根据给定的数据推断出合适的 dtype。这是从现有数据(如 Python 列表)创建张量的推荐方法。代码如下:
> cuda = torch.device("cuda")> torch.tensor([[1], [2], [3]], dtype=torch.half, device=cuda)tensor([[ 1], [ 2], [ 3]], device='cuda:0')> torch.tensor(1) # scalartensor(1)> torch.tensor([1, 2.3]).dtype # type inferecetorch.float32> torch.tensor([1, 2]).dtype # type inferecetorch.int64
我们还添加了更多的张量创建方法。其中包括一些有 torch.*_like 或 tensor.new_ * 变体。
1. torch.*_like 输入一个 tensor 而不是形状。除非另有说明,它默认将返回一个与输入张量相同属性的张量。代码如下:
>>> x = torch.randn(3, dtype=torch.float64)
>>> torch.zeros_like(x)
tensor([ 0., 0., 0.], dtype=torch.float64)
>>> torch.zeros_like(x, dtype=torch.int)
tensor([ 0, 0, 0], dtype=torch.int32)
2. tensor.new_ * 也可以创建与 tensor 具有相同属性的 tensor,但它需要指定一个形状参数:
>>> x = torch.randn(3, dtype=torch.float64)
>>> x.new_ones(2)
tensor([ 1., 1.], dtype=torch.float64)
>>> x.new_ones(4, dtype=torch.int)
tensor([ 1, 1, 1, 1], dtype=torch.int32)
要得到所需的形状,在大多数情况下你可以使用元组(例如 torch.zeros((2,3)))或可变参数(例如 torch.zeros(2,3))来指定。
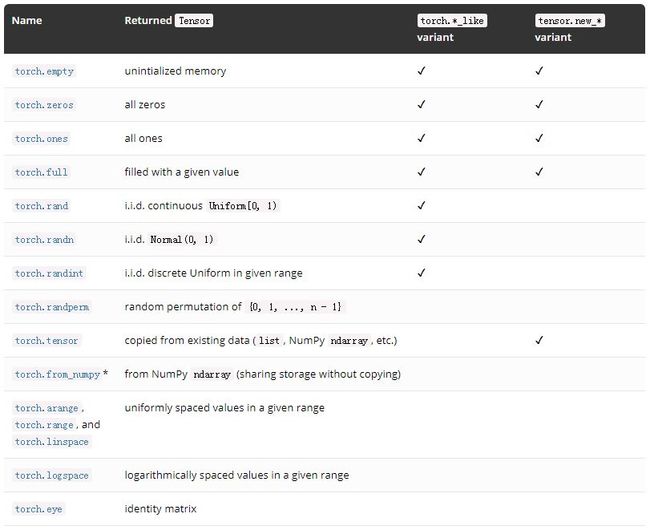
其中:torch.from_numpy 只接受一个 NumPy ndarray 类型作为其输入参数。
▌编写一些不依赖设备的代码
先前版本的 PyTorch 很难编写一些设备不可知或不依赖设备的代码(例如,可以在没有修改的情况下,在CUDA环境下和仅CPU环境的计算机上运行)。
在新版本PyTorch 0.4.0中,你通过一下两种方式让这一过程变得更容易:
张量的device属性将为所有张量提供 torch.device 属性(get_device 仅适用于 CUDA 张量)
Tensors 和 Modules 的 to 方法可用于将对象轻松移动到不同的设备(而不必根据上下文信息调用 cpu() 或 cuda())
我们推荐用以下的模式:
# at beginning of the scriptdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")...# then whenever you get a new Tensor or Module# this won't copy if they are already on the desired deviceinput = data.to(device)model = MyModule(...).to(device)
▌代码示例
为了更直观地得到0.4.0版本中代码模式的整体变化特征,我们来看一个0.3.1和0.4.0版本中一些常见的代码例子:
0.3.1旧版本
model = MyRNN()
if use_cuda:
model = model.cuda()
# train
total_loss = 0
for input, target in train_loader:
input, target = Variable(input), Variable(target)
hidden = Variable(torch.zeros(*h_shape)) # init hidden
if use_cuda:
input, target, hidden = input.cuda(), target.cuda(), hidden.cuda()
... # get loss and optimize
total_loss += loss.data[0]
# evaluate
for input, target in test_loader:
input = Variable(input, volatile=True)
if use_cuda:
...
...
0.4.0 新版本
# torch.device object used throughout this script
device = torch.device("cuda" if use_cuda else "cpu")
model = MyRNN().to(device)
# train
total_loss = 0
for input, target in train_loader:
input, target = input.to(device), target.to(device)
hidden = input.new_zeros(*h_shape) # has the same device & dtype as `input`
... # get loss and optimize
total_loss += loss.item() # get Python number from 1-element Tensor
# evaluate
with torch.no_grad(): # operations inside don't track history
for input, target in test_loader:
...
作者:The PyTorch Team
原文链接:
http://pytorch.org/2018/04/22/0_4_0-migration-guide.html
(转载声明:如需转载,请联系营长:微信1092722531)
招聘
AI科技大本营现招聘AI记者和资深编译,有意者请将简历投至:[email protected],期待你的加入!
AI科技大本营读者群(计算机视觉、机器学习、深度学习、NLP、Python、AI硬件、AI+金融、AI+PM方向)正在招募中,和你志同道合的小伙伴也在这里!关注AI科技大本营微信公众号,后台回复:读者群,添加营长请务必备注姓名,研究方向。





☟☟☟点击 | 阅读原文 | 查看更多精彩内容