排序算法之归并排序和外部排序
文章目录
- 一、归并排序
- 1、算法描述
- 2、算法图解
- (1)合并相邻有序子序列
- (2)整体过程
- 3、算法demo
- 4、算法总结
- 二、外部排序
- 1、算法描述
- 2、算法图解
- 3、算法demo
一、归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
1、算法描述
1. 把长度为n的输入序列分成两个长度为n/2的子序列;
2. 对这两个子序列分别采用归并排序;
3. 将两个排序好的子序列合并成一个最终的排序序列。
2、算法图解
(1)合并相邻有序子序列
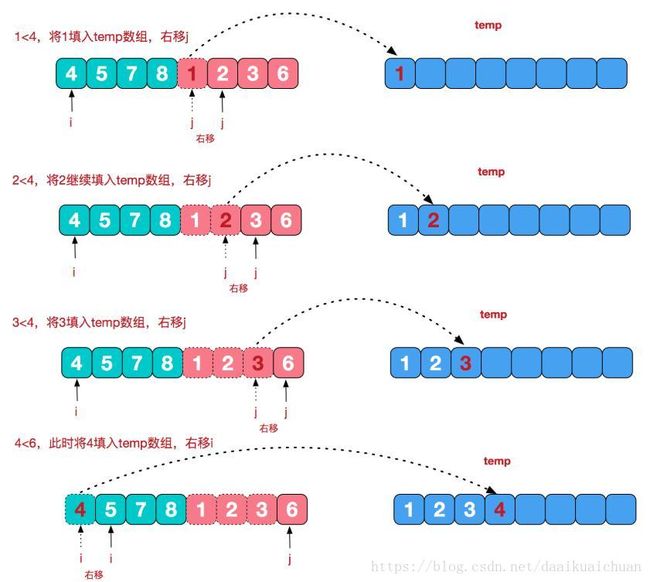

(2)整体过程
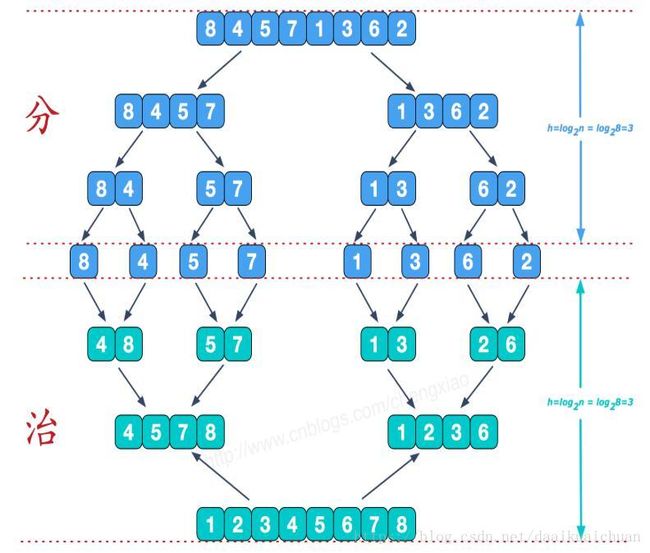
3、算法demo
#include 4、算法总结
归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。归并排序的最大好处是在数据呈现最坏情况时,是所有排序算法中表现最好的。
二、外部排序
当所要排序的的数据量太多或者文件太大,无法直接在内存里排序,而需要依赖外部设备时,就会使用到外部排序。
1、算法描述
假设文件需要分成k块读入,需要从小到大进行排序。
1. 依次读入每个文件块,在内存中对当前文件块进行排序(应用恰当的内排序算法),此时,每块文件相当于一个由小到大排列的有序队列;
2. 在内存中建立一个最小堆,读入每块文件的队列头;
3. 弹出堆顶元素,如果元素来自第i块,则从第i块文件中补充一个元素到最小值堆。弹出的元素暂存至临时数组;
4. 当临时数组存满时,将数组写至磁盘,并清空数组内容;
5. 重复过程3、4,直至所有文件块读取完毕。
2、算法图解

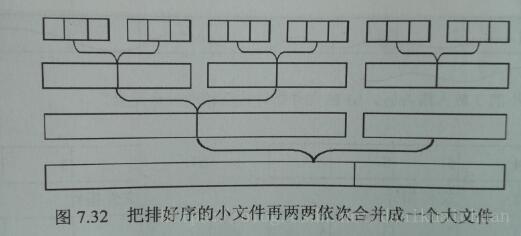
3、算法demo
#include 参考:https://www.cnblogs.com/chengxiao/p/6194356.html
https://blog.csdn.net/jfkidear/article/details/52947264