Spark 集群搭建详细步骤
1修改主机名和hosts
[root@localhost ~] hostname master
[root@localhost ~] vi /etc/hostname
#将里面内容改为: master
[root@localhost ~] vi /etc/hostname
#将下面内容加入
192.168.8.12 master
#注意:如果要搭建集群,需要将其它的主机名和IP也加进来,并且在每台主机上都要加
2配置秘钥登录
A添加用户
[root@localhost ~] useradd spark
[root@localhost ~]# passwd spark
B配置秘钥登录
[root@localhost ~]# vi /etc/ssh/sshd_config
#将54,55行的注释取消,改为:
RSAAuthentication yes
PubkeyAuthentication yes
[root@master ~]# systemctl restart sshd.service
[root@master ~]# su - spark
[spark@master ~]$ ssh-keygen -t rsa
#一路回车

[spark@master ~]$ cd .ssh
[spark@master .ssh]$ cat id_rsa.pub > authorized_keys
如果直接用ssh连接不用输密码就能登录,表示秘钥配置成功

要注意文件的权限:

3配置JDK,Scala,环境变量
A.需要的文件列表如下:
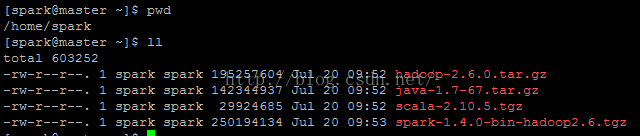
下载方法:分别到对应的官网,再到下载链接,使用wget下载,具体步骤省略
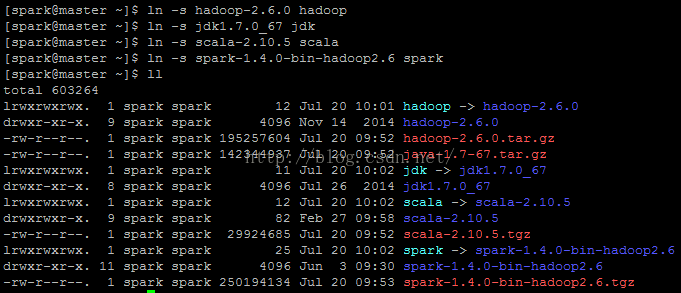
B.分别解压每个文件,注意:本人将所有的文件放到spark用户的主目录下,即:/home/spark
解压后的目录结构如下:

建立相应的软链接(也可以不建软链接,只是为了看着舒服和操作方便):
[spark@master ~]$ ln -s hadoop-2.6.0 hadoop
[spark@master ~]$ ln -s jdk1.7.0_67 jdk
[spark@master ~]$ ln -s scala-2.10.5 scala
[spark@master ~]$ ln -s spark-1.4.0-bin-hadoop2.6 spark
C.配置环境变量(root用户)
[root@master ~]# vi /etc/profile
#在文件最后加入
export JAVA_HOME=/home/spark/jdk
export SCALA_HOME=/home/spark/scala
export HADOOP_HOME=/home/spark/hadoop
export SPARK_HOME=/home/spark/spark
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin

注意:上面的路径需要根据自己的实际路径做出修改
加载环境变量(spark):
[spark@master ~]$ source /etc/profile
4配置Hadoop
[spark@master ~]$ cd $HADOOP_HOME/etc/hadoop
[spark@master hadoop]$ vi slaves
[spark@master hadoop]$ vi slaves
#将slave的主机名加入,每行一个主机名
[spark@master hadoop]$ vi core-site.xml
#将里面的内容改为(简单的配置,具体配置请查阅官方文档):
[spark@master hadoop]$ vi hdfs-site.xml
#改为
[spark@master hadoop]$ vi yarn-site.xml
#改为
创建对应的目录:
[spark@master hadoop]$ mkdir -p /home/spark/hadoop/hdfs/{data,name}
[spark@master hadoop]$ mkdir /home/spark/hadoop/tmp
初始化Namenode:
[spark@master hadoop]$ hadoop namenode -format

如图中的status为0,说明初始化成功,若为1,则失败,需要检查日志,找到错误原因。
启动Hadoop集群:
[spark@master hadoop]$ $HADOOP_HOME/sbin/start-all.sh
若报如下错误:
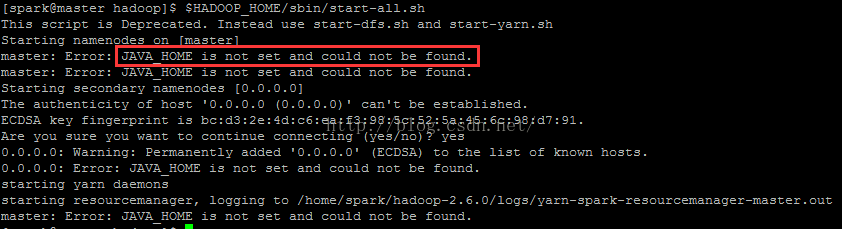
则需要如下操作:
[spark@master hadoop]$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
#将 export JAVA_HOME=${JAVA_HOME}
#改为 export JAVA_HOME=/home/spark/jdk (jdk的具体路径)
再次启动集群:
[spark@master hadoop]$ $HADOOP_HOME/sbin/start-all.sh
得到:
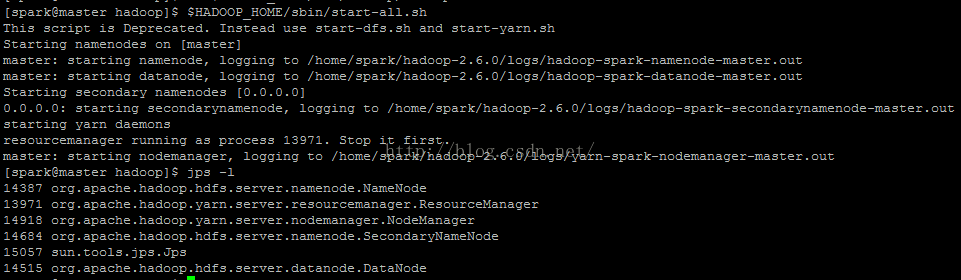
使用jps -l查看是否有如上图所示相应的进程。
至此,Hadoop集群已经好了。
5配置Spark
[spark@master hadoop]$ cd $SPARK_HOME/conf
[spark@master conf]$ vi slaves
#将Worker主机名加入
master
[spark@master conf]$ cp spark-env.sh.template spark-env.sh
#spark-env.sh 为Spark进程启动时需要加载的配置
#改模板配置中有选项的具体说明
#此处本人稍微加入了一些配置:
export JAVA_HOME=/home/spark/jdk
export HADOOP_HOME=/home/spark/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MERMORY=2G
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_DAEMON_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/home/spark/spark/logs -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+DisableExplicitGC -Xms1024m -Xmx2048m -XX:PermSize=128m -XX:MaxPermSize=256m"
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=7777 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000/sparkHistoryLogs -Dspark.yarn.historyServer.address=master:7788 -Dspark.history.fs.updateInterval=10"
创建相应目录:
[spark@master conf]$ mkdir /home/spark/spark/{logs,worker}
[spark@master conf]$ hadoop fs -mkdir hdfs://master:9000/sparkHistoryLogs
配置spark-defaults.conf,该文件为spark提交任务时默认读取的配置文件
[spark@master conf]$ cp spark-defaults.conf.template spark-defaults.conf
[spark@master conf]$ vi spark-defaults.conf
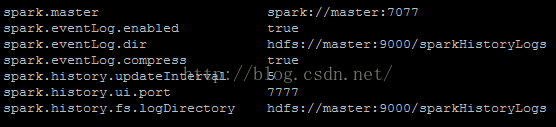
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/sparkHistoryLogs
spark.eventLog.compress true
spark.history.updateInterval 5
spark.history.ui.port 7777
spark.history.fs.logDirectory hdfs://master:9000/sparkHistoryLogs
启动Spark进程:
[spark@master conf]$ $SPARK_HOME/sbin/start-all.sh
![]()
启动Spark历史任务记录:
[spark@master conf]$ $SPARK_HOME/sbin/start-history-server.sh
![]()
Spark和Hadoop相关的所有进程如下图:

至此Spark集群也已经运行起来了。
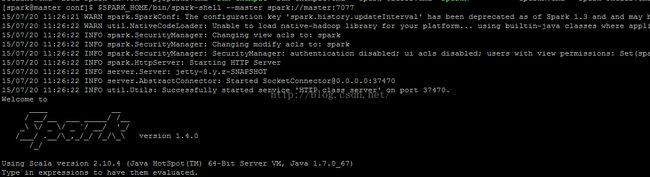
Spark-shell测试Spark集群:
[spark@master conf]$ $SPARK_HOME/bin/spark-shell --master spark://master:7077

scala> val data=Array(1,2,3,4,5,6,7,8,9,10)
data: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
![]()
scala> val pdata = sc.parallelize(data)
pdata: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at
![]()
scala> pdata.reduce(_+_)

上图展示了运行过程的一些信息,能正确得到结果,说明Spark集群已经OK了。
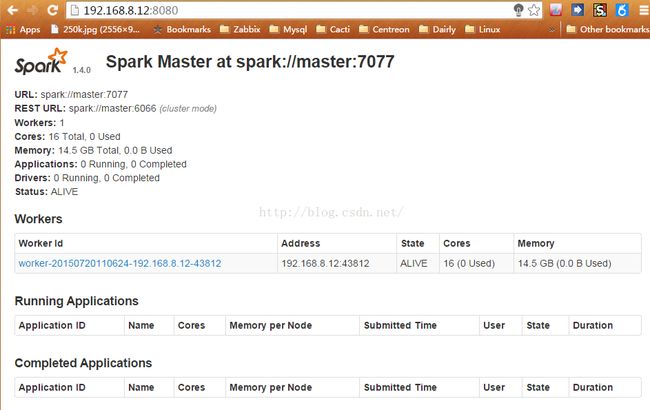
一些web浏览界面:
集群节点信息:http://master:8080
历史任务:http://master:7777
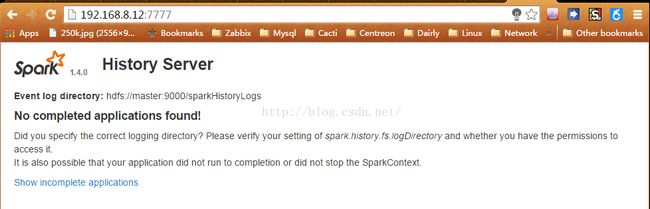
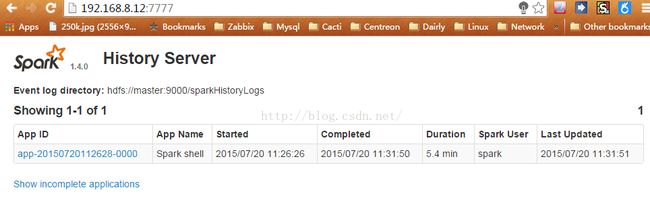
在Spark-Shell中运行测试后,就能看到历史任务了:
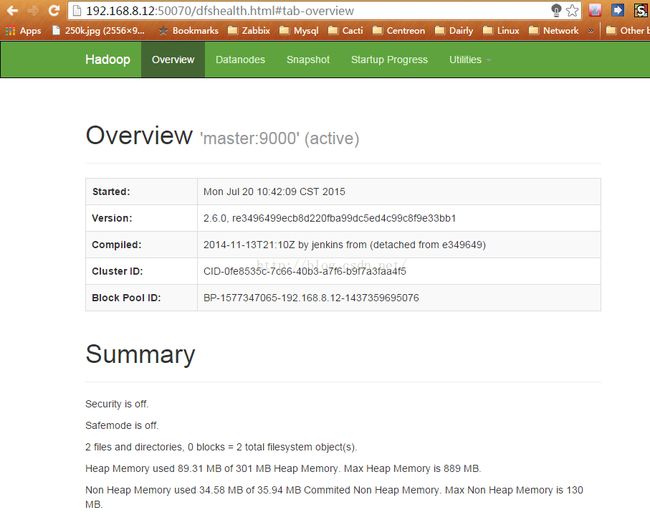
Hadoop 集群信息: http://192.168.8.12:50070/