大数据舞台中的Flink
说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习CSDN官网课程:
Flink大数据项目实战:http://t.cn/ExrHPl9
2014 年 Flink 作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角。区别于 Storm、Spark Streaming 以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级功能。比如它提供有状态的计算,支持状态管理,支持强一致性的数据语义以及支持 Event Time,WaterMark 对消息乱序的处理等。
2015 年是流计算百花齐放的时代,各个流计算框架层出不穷。Storm, JStorm, Heron, Flink, Spark Streaming, Google Dataflow (后来的 Beam) 等等。其中 Flink 的一致性语义和最接近 Dataflow 模型的开源实现,使其成为流计算框架中最耀眼的一颗。也许这也是阿里看中 Flink的原因,并决心投入重金去研究基于 Flink的 Blink框架。

Flink为何受青睐
Flink之所以受到越来越多公司的青睐,肯定有它很多过人之处。
1.支持批处理和数据流程序处理。
2.优雅流畅的支持java和scala api。
3.同时支持高吞吐量和低延迟。
4.支持事件处理和无序处理通过SataStream API,基于DataFlow数据流模型。
5.在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器)。
6.拥有仅处理一次的容错担保,Flink支持刚好处理一次。
7.拥有自动反压机制,当Flink处理数据达到上限的时候,源头会自动减少数据的输入,避免造成Flink应用的崩溃。
8.支持图处理(批)、 机器学习(批)、 复杂事件处理(流)。
9.在dataSet(批处理)API中内置支持迭代程序(BSP)。
10.高效的自定义内存管理和健壮的在in-memory和out-of-core中的切换能力。
11.同时兼容hadoop的mapreduce和storm。
12.能够集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件。
Flink生态与未来
核心组件栈
Flink发展越来越成熟,已经拥有了自己的丰富的核心组件栈,如下图所示。
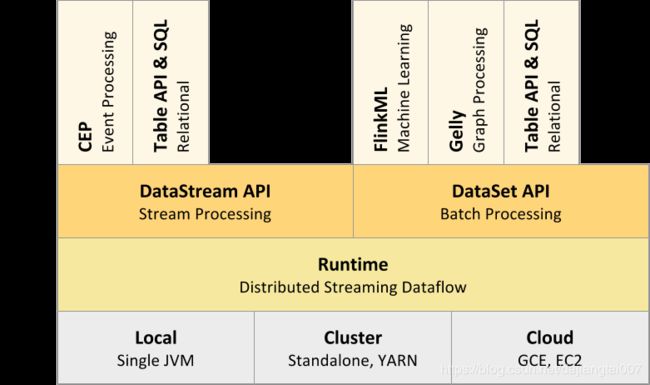
从上图可以看出Flink的底层是Deploy,Flink可以Local模式运行,启动单个 JVM。Flink也可以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行。另外Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)。
Deploy的上层是Flink的核心(Core)部分Runtime。在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)。在核心API之上又扩展了一些高阶的库和API,比如CEP流处理,Table API和SQL,Flink ML机器学习库,Gelly图计算。SQL既可以跑在DataStream API,又可以跑在DataSet API。
生态

从上图可以看出Flink拥有更大更丰富的生态圈:
中间最底层Deploy模式包含 Local本地模式、Cluster(包含Standalone和YARN)集群模式以及Cloud云服务模式,然后它的上层是Flink runtime运行时,然后它的上层是Flink DataSet批处理和DataStream流处理,然后它的上层又扩展了Hadoop MR、Table、Gelly(图计算)、ML(机器学习)、Zoppelin(可视化工具)等等。
左边为输入Connectors。流处理方式包含Kafka(消息队列),AWS kinesis(实时数据流服务),RabbitMQ(消息队列),NIFI(数据管道),Twitter(API)。批处理方式包含HDFS(分布式文件系统),HBase(分布式列式数据库),Amazon S3(文件系统),MapR FS(文件系统),ALLuxio(基于内存分布式文件系统)。
右边为输出Connectors。流处理方式包含Kafka(消息队列),AWS kinesis(实时数据流服务),RabbitMQ(消息队列),NIFI(数据管道),Cassandra(NOSQL数据库),ElasticSearch(全文检索),HDFS rolling file(滚动文件)。批处理包含HBase(分布式列式数据库),HDFS(分布式文件系统)。
未来
Flink会进行批计算的突破、流处理和批处理无缝切换、界限越来越模糊、甚至混合。
Flink会开发更多语言支持
Flink会逐步完善Machine Learning 算法库,同时 Flink 也会向更成熟的机器学习、深度学习去集成(比如Tensorflow On Flink)。
