(git上的源码:https://gitee.com/rain7564/spring_microservices_study/tree/master/second-discovery-euraka)
何为服务发现
在许多分布式系统架构中,都需要去获取机器的物理地址(微服务实例部署的服务器地址及端口)。这一认知在分布式系统架构开始的时候就已经存在,而等到分布式计算出现的时候,被正式称为服务发现(service discovery)。
服务发现可以做一些简单的事情,比如维护一个带有所有远程服务地址的属性文件,或一个UDDI(Universal Description, Discovery and Integration)存储库。
服务发现对微服务、分布式应用/基于云的应用至关重要。有两个主要原因:
- 它为应用程序开发团队提供了快速扩展的能力,以及缩减在一个环境中运行的服务实例数量。
通过服务发现,服务消费者(service consumers)可以从服务提供者(service provider)的物理地址中抽象出来。因为消费者并不知道提供者的实例的实际物理地址(多个实例就有多个地址),新的服务实例也可以添加到"可用服务池",失效的服务也会被移除,即消费者根本没办法具体知道会消费服务提供者哪个的实例,服务提供者实例的物理地址对消费者来说是透明的。
以往,庞大的单体应用要扩大业务处理能力,只能通过将应用部署到更大更好的机器上(纵向扩展),这种办法取得的效果与成本的比值越来越低,而且也无法无限扩展;而服务发现能让开发团队从这一困境走出,因为服务发现使将服务部署到更多的廉价机器上(横向扩展)成为可能。 - 服务发现使整体应用更有弹性。当机器出现异常使正在运行的服务实例处理能力变弱(频繁报错)或不可用,服务发现会将该实例从可用服务列表中移除,外部或应用内的其他微服务不会再"消费"这个服务实例。这样,因意外导致部分服务实例不可用,服务发现会将对该服务的"消费"路由到其他可用的服务实例,绕过了已衰掉的实例,该服务还是能正常被"消费",从而将影响降到了最低。
服务发现的实现方案
我们已经初步了解服务发现带来的好处。那么有没有好的方案来实现"服务发现"?例如DNS或负载均衡器(此处指服务端负载均衡,还有客户端负载均衡。注意:后文分析DNS+负载均衡模式,都是指服务端负载均衡)。
开发过程中,经常会有一种情况——从第三方获取资源,在获取的时候就必须定位这些资源所在的物理地址。若不是基于云架构的应用,大都采用DNS和负载均衡器实现。大体架构如下图所示:

应用调用第三方服务过程中,通过DNS将域名解析得到一个商业负载均衡器的物理地址,然后将请求转发到给负载均衡器,负载均衡器维护了一张路由表,然后根据这张路由表将请求路由给正确的服务。
为了获得高可用,会有一个处于空闲状态的次负载均衡器一直发送ping请求来确认主负载均衡器是否正常运行,若已经衰掉,次负载均衡器会被激活然后接管主负载均衡器。
然而这种解决方案并不适合基于云的微服务应用,原因如下:
- 单点故障:负载均衡会成为整体架构的一个单点故障。首先,如果负载均衡器衰掉,那么所有依赖负载均衡器的服务都会受到牵连。虽然主次负载均衡器能实现高可用,但当请求剧增时,会成为整体架构的性能瓶颈,单位时间内能处理的请求数有限。
- 限制水平扩展能力:通过负载均衡器将服务集中到单个集群,限制了负载均衡架构水平扩展的能力。大多数商业负载平衡器使用冗余的热交换模型,所以只有一台服务器来处理负载,而故障转移的次负载平衡器只有在停机的情况下才成为主负载均衡器。
- 静态托管:许多商业负载均衡器并不支持为服务快速注册/注销。他们将路由规则存储在一个集中式数据库中,而且添加新路由规则通常需要通过供应商提供的专有API。
- 复杂:因为负载均衡器只是服务的一个代理,服务消费者的请求必须通过它才能定位到服务提供者的物理地址。整个应用架构因为多了负载均衡这一转换层变得更复杂,因为所有路由规则都是通过人工定义和发布的。
以上四个原因并不是想说明服务端负载均衡架构不好,而是为了说明不适合基于云的微服务应用。因为服务端负载均衡能很好的作用于应用的大小、规模能通过集中式网络架构支撑的情况。
然而,基于云的应用中,需要处理大量的事务和数据信息,集中式网络架构并不能很好支撑这种情况,因为这种架构扩展能力弱,扩展成本效益低。下面开始介绍如何实现一个健壮的扩展性强的适用于云微服务应用的服务发现。
适用于云的服务发现
基于云的微服务环境的服务发现解决方案,必须具备以下特征:
- 高可用:服务发现需要具备支持"热"集群环境的能力。即服务的信息可以在服务发现集群的多个节点中共享。当集群中的某个节点不可用,其它节点可以完全接管。
- 所有节点对等:集群中的所有节点共享所有注册到服务发现的服务实例的状态信息。
- 负载均衡:服务发现需要动态地、均衡地将请求分配到所有注册到服务发现的服务实例。当然,服务发现可以根据不同的分配策略进行分配,比如轮询、随机等。服务发现取代了类似上文提及的静态的、需要人工配置的负载均衡器。
- 弹性:服务发现的客户端(服务发现分服务端和客户端,后文会详细说明)应该在本地缓存服务实例信息。这样做有很多好处,比如:不用每次远程请求都去服务发现的服务端获取目标服务的信息、当服务发现服务端衰掉了,短时间内还可以依赖本地缓存继续正常运行等。
- 容错:服务发现需要及时发现那些不可用的服务实例并将其从可用服务列表中移除。即可以自动发现并处理而不用认为干预。
至此,应该对适用于云的服务发现有一定的了解,接下来将会对如下几个方面进行分析:
- 基于云的服务发现代理是如何运作
- 当服务发现代理不可用时,客户端负载均衡是如何能继续运作
- 如何使用Spring Cloud和Netflix Eureka实现服务发现代理
服务发现架构
在讨论服务发现架构之前,需要了解四个概念,这四个概念在所有服务发现架构都会涉及到的,如下:
- 服务注册:服务是怎样把自己注册到服务发现代理?
- 客户端获取服务地址:客户端是怎样从服务发现代理获取其他同样注册到服务发现代理的服务的信息?
- 信息共享:服务发现代理集群之间是如何共享服务注册信息?
- 健康监控:服务客户端是怎样通知服务发现代理自己的状态信息?
下图中序号1-4分别对应上面所说的四个概念。
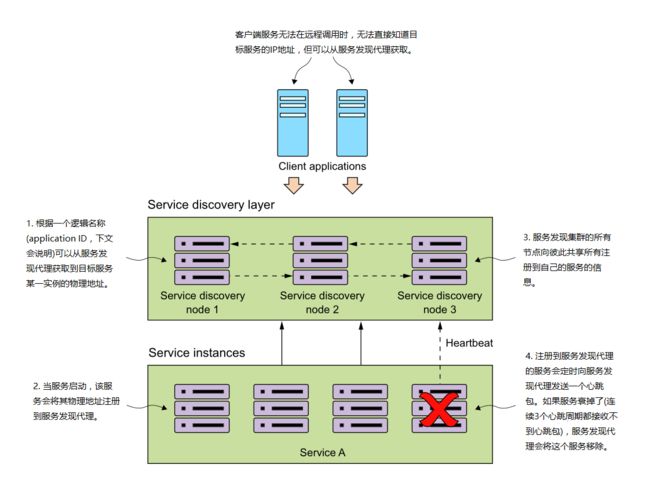
当服务启动后,它们会将自己注册到一个或多个服务发现代理,即将物理地址、端口等信息发送。虽然某个服务的所有实例有不同的IP和端口号,但它们都会注册在同一个服务ID(上文已经提到的逻辑名称,application name)下,这个服务ID只是被服务发现代理用来给不同服务分组而已,即相同服务的不同实例,它们的服务ID是相同的。
一般情况下,一个服务只需要注册到一个服务发现代理。因为大多服务发现实现都采用数据共享模型,即一个服务发现集群的所有节点会共享它们维护的数据。
当一个服务实例注册到服务发现代理,就意味着它随时可以被其他应用或服务调用,注册到服务发现的所有服务之间的调用是相互的。客户端服务在"发现"服务上有多种模式。比如:客户端服务的每次远程调用,都依靠服务发现引擎去解析得到目标服务的地址。这种模式(服务端服务发现,如DNS+负载均衡器)是非常脆弱的,因为客户端服务的每一个远程调用完全依赖于服务发现引擎,所以需要有一个更好、更健壮的模式——客户端负载均衡。下图说明了何为客户端负载均衡:
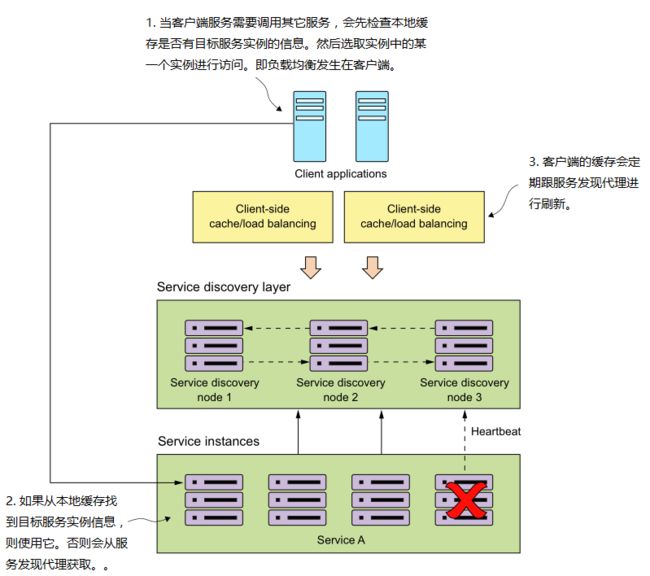
另外,当服务调用失败,客户端会让本地缓存失效,然后重新从服务发现代理获取新的服务注册信息。
使用Netflix Eureka实现服务发现
接下来,我们会创建一个服务发现代理并向该代理注册两个服务。然后其中的一个服务使用从服务发现代理获取的服务信息去调用另一个服务。Netflix Eureka的服务发现引擎可以实现服务发现,而客户端负载均衡的实现则使用Netflix的Ribbon库。
当然,Spring Cloud为实现服务发现提供了多种解决方案。下文也会分析各自的优劣势。
在上一节,我们已经创建了一个微服务应用,该应用中只有license一个微服务。现在我们会在现有应用的基础上,再创建一个organization服务和一个服务发现代理,并将license服务和organization服务注册到服务发现代理。
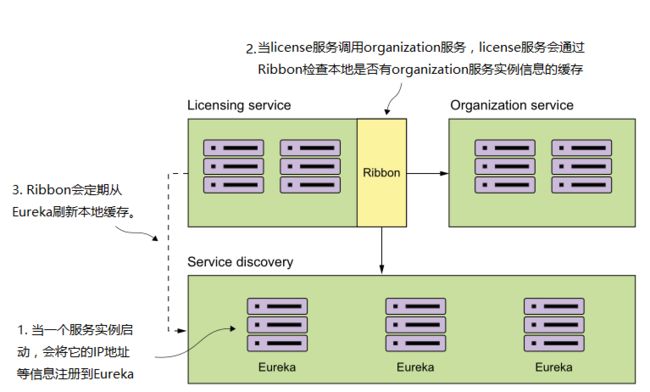
假设当license服务被调用,它会去调用organization服务,organization服务再根据organization ID获取对应的organization信息并返回。在从organization服务获取数据前,必须先知道organization服务可用的实例信息,这些信息是organization服务启动的时候就注册到服务发现代理并由它维护的。而license服务在调用organization服务时,会从本地获取organization服务实例的信息。下图说明了这个过程:
在上一节创建的应用的基础上,再创建一个organization微服务,由于创建步骤与创建license服务时大同小异,这里就不贴代码出来,需要的可以去git上查看。(由于需要将license服务和organization服务注册到Eureka上,实现这一功能的代码会在下文贴出)
接下来我们开始进入本节的重头戏,服务发现代理的搭建。
搭建Spring Eureka服务
我们会使用Spring Boot搭建Eureka服务,因为服务发现本质上也是一个微服务。
- pom文件
首先,把注意力放在pom.xml文件上,代码如下:
eureka服务:
4.0.0
cn.study.microservice
discovery-eureka
0.0.1-SNAPSHOT
jar
discovery-eureka
cn.study.microservice
second-discovery-euraka
0.0.1-SNAPSHOT
org.springframework.cloud
spring-cloud-starter-eureka-server
可以看到,pom文件中的依赖很少,只有一个"spring-cloud-starter-eureka-server",这是因为Spring Cloud的Eureka server启动依赖,其中包含多个必须的jar包,如"spring-cloud-netflix-eureka-server"、"spring-cloud-starter-ribbon"等。
同样的,因为license服务和organization服务会注册到Eureka上,所以对应的pom文件也需要作出修改,如下:
license服务:
4.0.0
cn.study.microservice
license-service
0.0.1-SNAPSHOT
jar
license-service
cn.study.microservice
second-discovery-euraka
0.0.1-SNAPSHOT
org.springframework.boot
spring-boot-starter-web
org.springframework.cloud
spring-cloud-starter-eureka
org.springframework.cloud
spring-cloud-starter-feign
org.springframework.boot
spring-boot-starter-data-jpa
com.h2database
h2
organization服务:
4.0.0
cn.study.microservice
organization-service
0.0.1-SNAPSHOT
jar
organization-service
cn.study.microservice
second-discovery-euraka
0.0.1-SNAPSHOT
org.springframework.boot
spring-boot-starter-web
org.springframework.cloud
spring-cloud-starter-eureka
org.springframework.boot
spring-boot-starter-data-jpa
com.h2database
h2
上面两个pom文件中,可以看到都引入了一个与eureka相关的依赖——"spring-cloud-starter-eureka",与服务发现引入的依赖——"spring-cloud-starter-eureka-server"略有不同,多了一个"-server",那么不同在哪里呢?可以打开idea提供的"Maven Project"视图,打开方法如下:
打开后可以看到类似如下图所示:
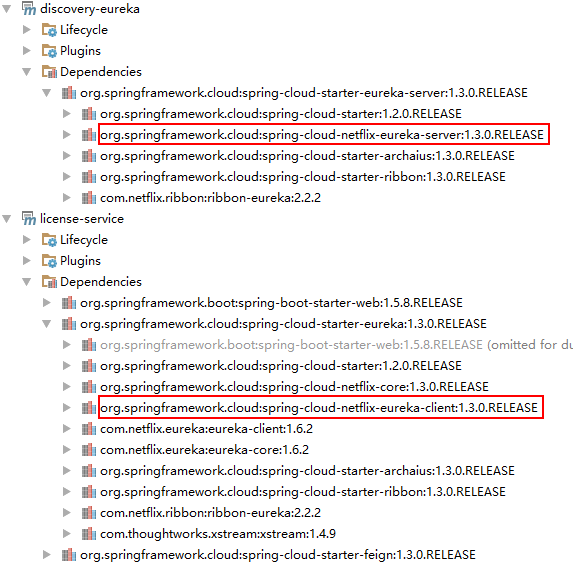
可以看到,"spring-cloud-starter-eureka-server"会引入"spring-cloud-netflix-eureka-server",而"spring-cloud-starter-eureka"会引入"spring-cloud-netflix-eureka-client",分别代表eureka服务端和客户端。
另外,license、organization两个服务还添加"spring-boot-starter-data-jpa"、"com.h2database.h2"。即数据库使用的是h2,因为要确保教程的代码能开箱即用,如果使用mysql等其他开源数据库,读者还要去新建数据库,如果数据库账户密码不同,还需要去改配置文件;数据访问层框架使用的是"spring data jpa","spring-boot-starter-data-jpa"是spring boot提供的启动依赖,里边包含spring data jpa和hibernate-core等jar包,若之前未了解过spring data jpa,建议先去熟悉下。
最后,license服务pom文件中还多出了一个依赖:"spring-cloud-starter-feign"。该依赖是spring cloud提供的启动依赖,主要包含了Netflix的一个开源项目feign项目的jar包,feign主要功能是对上文提及的实现了客户端负载均衡的Ribbon的封装,下文会详细说明。
- 配置文件
eureka服务的application.yml配置文件:
#默认端口号为8761
server:
port: 8761
eureka:
client:
#由于该应用为注册中心,所以设置为false,代表不向注册中心注册自己
registerWithEureka: false
#由于注册中心的职责就是维护服务实例,它并不需要去检索服务,所以也设置为false
fetchRegistry: false
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
#关闭自我保护模式。自我保护模式是指,出现网络分区、eureka在短时间内丢失过多客户端时,会进入自我保护模式。
#自我保护:一个服务长时间没有发送心跳包,eureka也不会将其删除,默认为true。
enable-self-preservation: false
#在Eureka服务器获取不到集群里对等服务器上的实例时,需要等待的时间,单位为毫秒,默认为1000 * 60 * 5
wait-time-in-ms-when-sync-empty: 0
license服务的application.yml配置文件:
server:
port: 10000
#服务发现客户端
eureka:
instance:
#向Eureka注册时,是否使用IP地址+端口号作为服务实例的唯一标识。推荐设置为true
prefer-ip-address: true
#============分界线================
#以下为基本不需要配置的属性,属性的值为默认值
#服务续约的调用时间间隔,默认30秒
lease-renewal-interval-in-seconds: 30
#服务失效的时间,默认90秒
lease-expiration-duration-in-seconds: 90
#非安全的通信端口号
non-secure-port: 80
#安全的通信端口号
secure-port: 443
#是否启用非安全的通信端口号
non-secure-port-enabled: true
#是否启用安全的通信端口号
secure-port-enabled: false
client:
#是否将自身的实例信息注册到Eureka服务端
register-with-eureka: true
#是否拉取并缓存其他服务注册表副本到本地
fetch-registry: true
#注册到哪个Eureka服务实例
service-url:
defaultZone: http://localhost:8761/eureka/
#============分界线================
#以下为基本不需要配置的属性,属性的值为默认值
#更新其他服务注册表时间间隔,默认30秒
registry-fetch-interval-seconds: 30
#更新实例信息的变化到Eureka服务端的间隔时间,单位为秒
instance-info-replication-interval-seconds: 30
#初始化实例信息到Eureka服务端的间隔时间,单位为秒
initial-instance-info-replication-interval-seconds: 40
#轮询Eureka服务端地址更改的间隔时间,单位为秒。
#当我们与Sping Cloud Config配合,动态刷新Eureka的service url地址时需要关注该参数
eureka-service-url-poll-interval-seconds: 300
#读取Eureka Server信息的超时时间,单位为秒
eureka-server-read-timeout-seconds: 8
#连接Eureka Server的超时时间,单位为秒
eureka-server-connect-timeout-seconds: 5
#从Eureka客户端到所有Eureka服务端的连接总数
eureka-server-total-connections: 200
#从Eureka客户端到每个Eureka服务端主机的连接总数
eureka-server-total-connections-per-host: 50
#Eureka服务连接的空闲关闭时间,单位为秒
eureka-connection-idle-timeout-seconds: 30
#心跳连接池的初始化线程数
heartbeat-executor-thread-pool-size: 2
#心跳超时重试延迟时间的最大乘数值
heartbeat-executor-exponential-back-off-bound: 10
#缓存刷新线程池的初始化线程数
cache-refresh-executor-thread-pool-size: 2
#缓存刷新重试延迟时间的最大乘数值
cache-refresh-executor-exponential-back-off-bound: 10
#使用DNS来获取Eureka服务端的service url
use-dns-for-fetching-service-urls: false
#是否优先使用处于相同Zone的Eureka服务端
perfer-same-zone-eureka: true
#获取实例时是否过滤,仅保留UP状态的实例
filter-only-up-instances: true
#数据源的配置
spring:
datasource:
platform: h2
schema: classpath:schema.sql
data: classpath:data.sql
driver-class-name: org.h2.Driver
jpa:
show-sql: true
hibernate:
ddl-auto: none
organization服务的application.yml配置文件:
server:
port: 11000
eureka:
instance:
preferIpAddress: true
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://localhost:8761/eureka/
spring:
datasource:
platform: h2
schema: classpath:schema.sql
data: classpath:data.sql
driver-class-name: org.h2.Driver
jpa:
show-sql: true
hibernate:
ddl-auto: none
每一个注册到eureka的服务实例,eureka中都有两个属性与它关联起来,分别为:application ID、instance ID。application ID是用来标识某一个服务的实例集合,即同一个服务的不同实例,它们的application ID都是相同的;基于Spring Boot的微服务,可以通过设置属性spring.application.name来定义application ID(一般在bootstrap.yml中配置),上面的配置,license服务的application ID为licensingservice,organization服务的为organizationservice;instance ID默认是一个随机数,用来定位服务的实例集合中某一实例,通常会配置eureka.instance.instance-id,如${spring.cloud.client.ipAddress}:${server.port},上面给出的配置并没有配置该属性,读者可自行配置。
下面介绍几个主要的属性的作用:
属性eureka.instance.preferIpAddress:会通知eureka使用服务实例的IP地址进行注册,而不是它的主机名(hostname)。一般情况下,该属性会被设置为true,其中一个原因是:基于云的微服务的生存周期很短暂且是无状态的,这些微服务可以随意启动和关闭。因此使用IP地址更适合这种微服务。
属性eureka.client.registerWithEureka:代表该服务是否将自己注册到eureka中;属性eureka.client.fetchRegistry表明该服务是否从eureka服务端获取其他服务的注册信息到本地,将该属性设置为true,就不用在每一次调用其他服务的接口时都要去eureka获取目标服务的信息。另外,若eureka.client.fetchRegistry设置为true,服务每隔30s会从eureka刷新服务信息到本地。
属性eureka.client.serviceUrl.defaultZone:代表服务会注册到哪个eureka服务端实例。实现eureka的高可用需要关注这个属性,这里不过多说明,需要了解更多关于eureka高可用,请自行Google或百度。
配置文件中的大多数属性的作用都已在文件中给出注释,就不过多赘述了。
另外license、organization两个服务还多出一个bootstrap.yml文件,该文件主要配置微服务的application.name和profiles.active,该文件会在application.yml之前被加载。
- 启动类
eureka服务:
@SpringBootApplication
@EnableEurekaServer
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
观察上面的代码,可以看出相比普通的微服务启动类,只多出了一个注解——@EnableEurekaServer,该注解表明该微服务会成为一个Eureka服务,即服务发现的服务端。
启动该服务,可以看到控制台会打印如下字符串:
Started Eureka Server
Tomcat started on port(s): 8761 (http)
表明eureka服务已成功启动,并且在端口8761启动,之前在配置文件中配置的server.port: 8761已经起作用了。
接着在浏览器访问: http://localhost:8761/,如下图所示:
上图圈中的区域是一个注册到该eureka服务实例的所有服务实例列表,因为此时尚未有任何服务注册,所以列表为空。
organization服务:
//该注解表明该类是项目(微服务)的启动类
@SpringBootApplication
@EnableEurekaClient
public class Application {
//运行该方法,会启动整个Spring Boot服务
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
观察上面organization服务启动类的代码,与eureka服务的相比,@EnableEurekaServer注解变成了@EnableEurekaClient,使用该注解的服务,会在服务启动的时候将自己注册到eureka服务端。如果查看@EnableEurekaClient的源码,如下:
@EnableDiscoveryClient
public @interface EnableEurekaClient {
}
可以看到,该注解其实是Netflix Eureka对注解@EnableDiscoveryClient的封装,注解@EnableDiscoveryClient可以说是服务可以使用DiscoveryClient和Ribbon库的触发器,并将自己注册到服务发现代理。所以你也可以选择使用@EnableDiscoveryClient代替@EnableEurekaClient。
启动organization服务,可以看到控制台有类似下图的输出:

此时若再次访问http://localhost:8761/,可以看到类似如下图的界面:
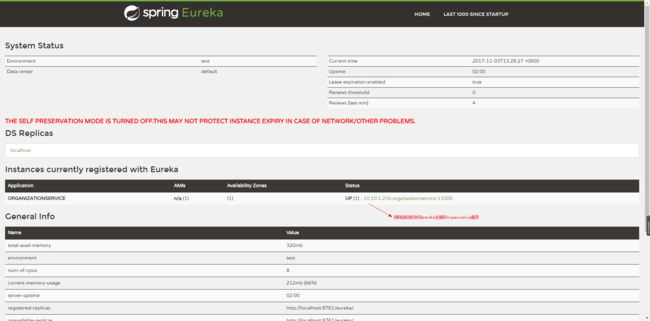
若出现的界面与上图类似,说明到此为止应用的搭建还算顺利。可以看到上图的注册到eureka服务的所有服务实例列表不为空,多出了一行,这一行列出的信息代表有一个application Id为"ORGANIZATIONSERVICE",instance ID为"10.10.1.216:organizationservice:11000"的服务实例注册到eureka,"UP(1)"则代表该服务只有一个实例正在运行。
license服务:
此时先不考虑license服务会消费organization服务,所以启动类的代码跟organization服务的相同,这里就不贴出来。
启动license服务,然后刷新http://localhost:8761/,可以看到向eureka服务注册的服务列表中多出了一行,说明刚刚启动的license服务也注册成功。

使用服务发现
接下来我们会通过三种方式来实现服务的发现。分别如下:
- Spring Discovery client
- Netflix Ribbon client
- Netflix Feign client
首先,把license和organization服务关掉,eureka无所谓;然后把organization服务的其他相关代码加上,如controller包、repository包、service包,详细代码请参考git上的代码。我们把重点放在license服务代码编写上。下面开始进入正题。
(License和Organization实体类请读者自行加上)
- Spring Discovery client
首先创建一个服务发现客户端类——OrganizationDiscoveryClient,路径:cn.study.microservice.license.client.OrganizationDiscoveryClient,如下:
@Component
public class OrganizationDiscoveryClient {
//当服务启动类加上@EnableEurekaClient或@EnableDiscoveryClient注解后,会自动注入实现DiscoveryClient接口的对象。此处会注入EurekaDiscoveryClient对象
@Autowired
private DiscoveryClient discoveryClient;
public Organization getOrganization(String organizationId) {
RestTemplate restTemplate = new RestTemplate();
//会从eureka服务端获取organizationservice服务的所有实例集合
List instances = discoveryClient.getInstances("organizationservice");
if (instances.size()==0) return null;
String serviceUri = String.format("%s/v1/organizations/%s",instances.get(0).getUri().toString(), organizationId);
System.out.println("!!!! SERVICE URI: " + serviceUri);
ResponseEntity< Organization > restExchange =
restTemplate.exchange(
serviceUri,
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
}
上面代码中,涉及到一个类:RestTemplate,该类是Spring用于客户端http同步访问的主要类。具体用法,请读者自行了解。
接着,创建cn.study.microservice.license.service.LicenseService,如下:
@Service
public class LicenseService {
@Autowired
private LicenseRepository licenseRepository;
@Autowired
private OrganizationDiscoveryClient organizationDiscoveryClient;
private Organization retrieveOrgInfo(String organizationId, String clientType){
Organization organization = null;
switch (clientType) {
case "discovery":
System.out.println("I am using the discovery client");
organization = organizationDiscoveryClient.getOrganization(organizationId);
break;
default:
organization = organizationDiscoveryClient.getOrganization(organizationId);
}
return organization;
}
public License getLicense(String organizationId, String licenseId, String clientType) {
License license = licenseRepository.findByOrganizationIdAndLicenseId(organizationId, licenseId);
Organization org = retrieveOrgInfo(organizationId, clientType);
return license
.withOrganizationName( org.getName())
.withContactName( org.getContactName())
.withContactEmail( org.getContactEmail() )
.withContactPhone( org.getContactPhone() )
.withComment("");
}
}
最后,编写controller类,如下:
@RestController
@RequestMapping(value="v1/organizations/{organizationId}/licenses")
public class LicenseServiceController {
@Autowired
private LicenseService licenseService;
@RequestMapping(value="/{licenseId}/{clientType}",method = RequestMethod.GET)
public License getLicensesWithClient( @PathVariable("organizationId") String organizationId,
@PathVariable("licenseId") String licenseId,
@PathVariable("clientType") String clientType) {
return licenseService.getLicense(organizationId,licenseId, clientType);
}
}
到此,代码编写完毕,启动服务,然后使用postman访问http://localhost:10000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a/discovery,结果如下:
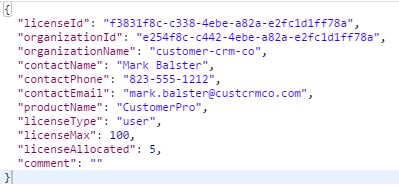
可以看到,返回的结果是licenseId为"f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a"的License对象的json字符串,其中"organizationName"、"contactName"、"contactPhone"和"contactEmail"都是根据organizationId访问organization服务提供的接口:/v1/organizations/{organizationId},然后返回一个Organization对象,最后将对象中的信息赋值到License对象中。实现这一功能的核心代码如下:
...
ResponseEntity< Organization > restExchange =
restTemplate.exchange(
serviceUri,
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
...
exchange方法的方法签名为:
public ResponseEntity exchange(
String url, //需要访问的资源的url
HttpMethod method, //HTTPMethod枚举,分别代表http定义的各种安全方法,如:GET、POST、PUT、DELETE等。
HttpEntity requestEntity, //请求实体,即请求携带的数据。为空时,赋null
Class responseType, //返回对象的Class类型
Object... uriVariables //url路径上变量对应的值
)
此处,可以看成是license服务调用了organization服务的接口。该接口在organization服务的OrganizationServiceController类中被定义。读者可以自行验证,在控制台会答应出变量"serviceUri"的值:http://10.10.1.216:11000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a,请读者将"10.10.1.216"换成自己的IP或"localhost",然后用postman访问。
至此,第一种实现服务发现方式完成。原理是:使用DiscoveryClient从服务端获取对应服务的所有实例列表,然后取其中的一个实例,并获取该实例的物理地址,最后调用该服务的接口。看到这里,读者应该对服务发现有更深的理解。license服务在调用organization服务的接口时,没有使用硬编码也行不通,因为在代码编写阶段,根本不知道服务会被部署到哪个服务器的哪个端口,而通过服务发现,则可以动态地获取目标服务实例的物理地址(前提是目标服务也注册到eureka),进而调用该服务的接口。
- Netflix Ribbon client
在编写服务发现客户端类前,先修改启动类,添加一下代码:
//该注解告知Spring Cloud创建一个基于Ribbon的RestTemplate,才可以实现客户端负载均衡
@LoadBalanced
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
接着,编写服务发现客户端类——OrganizationRestTemplateClient,如下:
@Component
public class OrganizationRestTemplateClient {
@Autowired
RestTemplate restTemplate;
public Organization getOrganization(String organizationId){
ResponseEntity restExchange =
restTemplate.exchange(
"http://organizationservice/v1/organizations/{organizationId}",
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
}
然后,修改LicenseService类,注入OrganizationRestTemplateClient、修改方法retrieveOrgInfo,如下:
...
@Autowired
private OrganizationRestTemplateClient organizationRestClient;
...
switch (clientType) {
case "discovery":
System.out.println("I am using the discovery client");
organization = organizationDiscoveryClient.getOrganization(organizationId);
break;
case "rest":
System.out.println("I am using the rest client");
organization = organizationRestClient.getOrganization(organizationId);
break;
default:
organization = organizationDiscoveryClient.getOrganization(organizationId);
}
...
至此,代码修改完毕,启动服务。使用postman调用:http://localhost:10000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a/rest。正确返回后,可以发现返回结果与第一种方式返回的结果相同。接下来,开始分析第二种方式是如何内部工作的:
查看服务发现客户端类OrganizationRestTemplateClient,可以发现同样是使用RestTemplate的exchange方法来调用organization服务的接口,唯一不同的是方法的第一个参数值,这里硬编码为:"http://organizationservice/v1/organizations/{organizationId}"。为什么这里可以这样直接写死在程序里,而且是使用"organizationservice"代替常规的服务实例物理地址。还记得在启动类中注入的RestTemplate吗,我们在注入的时候另外加了一个注解@LoadBalanced,答案就在这里。
加了注解@LoadBalanced后,代表在注入RestTemplate时,Ribbon会对其进行加工,加工后的RestTemplate的能力有:
- 在调用其他服务的接口时,会从访问的url中截取得到目标服务的application ID,此处为"organizationservice",然后根据该服务获取对应的实例,最后正常访问;
- 实现客户端负载均衡
读者可以自行验证,把注解去掉,然后重启服务,再访问一次,结果肯定是报错。如下:
{
"timestamp": 1509695097081,
"status": 500,
"error": "Internal Server Error",
"exception": "org.springframework.web.client.ResourceAccessException",
"message": "I/O error on GET request for \"http://organizationservice/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a\": organizationservice; nested exception is java.net.UnknownHostException: organizationservice",
"path": "/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a/rest"
}
可以看出,报的错是未知主机名:organizationservice。如果将"organizationservice"换成"localhost:11000"就能正常访问。
最后,我们来对可能是大家最关心的问题进行验证,客户端负载均衡。
- 打包项目
打开idea的Maven Projects,如下:
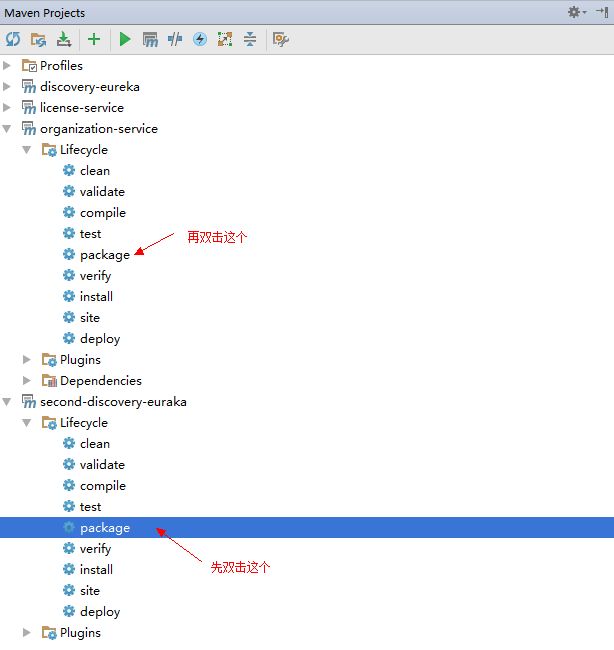
- 启动多个organization服务
使用快捷键组合:Alt + F12,打开终端控制台,然后进入organization项目的target目录,最后使用命令:
java -jar organization-service-0.0.1-SNAPSHOT.jar --server.port=11000
执行该命令后,会在端口11000启动一个organization服务。
接着按照同样的方式在不同端口启动一个或多个服务。首先点击终端控制台左上角的"+"图标,创建一个新的终端,然后进入target目录,使用命令:
java -jar organization-service-0.0.1-SNAPSHOT.jar --server.port=11001
启动多个organization服务后,多次访问:http://localhost:10000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a/rest
观察两个终端控制台,会出现如下图所示的输出:


由上图可知客户端负载均衡验证成功。license服务多次调用organization服务的接口,会随机的访问organization服务的某一实例,从而避免频繁访问某一个实例,达到负载均衡的目的。
使用Netflix Ribbon client可以很方便地实现对其它服务接口的调用,但每个接口的调用都要写类似OrganizationRestTemplateClient.getOrganization方法的代码,虽然不多,但有没有更方便、简介的实现方法呢?下面开始讲如何使用"Netflix Feign client"实现。
- Netflix Feign client
在编写服务发现客户端类前,向启动类添加一个类注解:@EnableFeignClients。
接着,编写服务发现客户端类——OrganizationFeignClient,其实是一个接口:
@FeignClient("organizationservice")
public interface OrganizationFeignClient {
@RequestMapping(
method= RequestMethod.GET,
value="/v1/organizations/{organizationId}",
consumes="application/json")
Organization getOrganization(@PathVariable("organizationId") String organizationId);
}
最后修改,LicenseService类,注入OrganizationRestTemplateClient、修改方法retrieveOrgInfo。如下:
...
@Autowired
OrganizationFeignClient organizationFeignClient;
...
switch (clientType) {
case "discovery":
System.out.println("I am using the discovery client");
organization = organizationDiscoveryClient.getOrganization(organizationId);
break;
case "rest":
System.out.println("I am using the rest client");
organization = organizationRestClient.getOrganization(organizationId);
break;
case "feign":
System.out.println("I am using the feign client");
organization = organizationFeignClient.getOrganization(organizationId);
break;
default:
organization = organizationDiscoveryClient.getOrganization(organizationId);
}
...
代码修改完成,重启license服务。然后访问http://localhost:10000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a/feign。返回的结果与之前两种方式一样。
下面分析接口OrganizationFeignClient:
可以看到该接口上方添加了一个注解——FeignClient,注解的value值为:organizationservice,看到这里,应该能猜出organizationservice代表的是需要调用的接口所属的服务的application ID,而该接口的作用是:用于通知Feign组件对该接口进行代理,而不需要编写任何逻辑代码。在服务启动时,Feign会扫描标有@FeignClient注解的接口,生成代理,并注册到Spring容器中,因此可通过@Autowired注入。
接着就是接口中的方法的编写。可以看到方法getOrganization添加了一个@RequestMapping注解,注解的value值就是目标服务的接口。如果与第二种方式调用RestTemplate.exchange方法做对比,服务application ID+@RequestMapping的value值与exchange的第一个参数url对应;@RequestMapping的method与第二个 参数对应;接口方法的返回值与第四个参数对应;接口方法的所有带@PathVariable注解的参数合并成一个数组与第五个参数对应;至于第三个参数,由于该接口的请求体为空,所以在方法getOrganization的签名中没体现出来。
假设启动多个organization服务实例,那么多次访问http://localhost:10000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a/feign,也会负载均衡, 其负载均衡的默认实现是基于 Netflix Ribbon。
完!