Webbench源码分析之socket及http协议(二)
概述:通过阅读webbench源码,我个人总结了大致以下六个知识点。我第一个参数输入我在上篇博客中说过了,今天主要是http协议和socket客户端编程的一个学习记录,后面的4,5,6知识点都属于多进程的一个学习,我下篇再一起说了。
知识点:
1,参数输入函数getopt_long()函数使用。
2,http协议。
3,socket客户端网络编程知识。
4,多进程编程知识。
5,多进程中父子进程管道通信pipe()函数使用。
6,多进程中信号量编程。
首先在说socket和http协议之前呢,还是先把源码中的全局变量含义说一下,这样以便于后面说到函数时更容易理解。
全局变量含义说明
/* values */
volatile int timerexpired=0; /*压测时间到达标志符,1表示压测时间到*/
int speed=0; /*用于记录请求服务器成功次数*/
int failed=0; /*用于记录请求服务器失败次数*/
int bytes=0; /*用于记录请求服务器获得的响应字节数*/
/* globals */
int http10=1; /*http协议版本,0:0.9版本,1:1.0版本,2:1.1版本 */
int method=METHOD_GET; /*http请求类型,默认GET请求,0:GET,1:HEAD,2:OPTIONS,3: TRACE*/
int clients=1; /*表示测试时请求的客户端数量,默认为1个*/
int force=0; /*是否等待服务器响应数据,0:等待服务器数据,1:不等待*/
int force_reload=0; /*是否缓存页面,1:缓存,0:不缓存*/
int proxyport=80; /*代理服务器端口或服务器端口,默认80端口,当有代理服务器时此端口是代理服务器端口,若无代理则是我们要访问的服务器端口*/
char *proxyhost=NULL; /*代理服务器主机地址*/
int benchtime=30; /*压测时间,默认30s*/
/* internal */
int mypipe[2]; /*用于父子进程通信的管道*/
char host[MAXHOSTNAMELEN]; /*服务器主机地址*/
char request[REQUEST_SIZE]; /*存放http请求数据包*/打包http请求包的build_request(const char *url)函数解析
在说源码之前,我们要基本了解一下http协议,不然后面打包过程我们就完全不知所云。所以,基本的http协议知识就要知道了。我这里就稍微整理一下我们看源码时需要用到的几个知识点。
1,http协议概念。
2,http协议版本及对应的支持的请求方式。
3,http中url的组成结构。
4,http请求包的基本内容组成结构。
5,http代理与非代理时请求区别。
1,http协议概念:
维基百科是这么说的:http协议即超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议[1]。HTTP是万维网的数据通信的基础。我个人觉得其实就是一个通用的全球的网络协议,只要我们按它这套协议制定的规则去打包数据,解析数据就行。现在基本都是基于TCP/IP协议,也就是说真正的数据传输还是tcp/ip协议,只是传的数据是经过协议制定的而已。当我们用socket编程时,自己定一套传输协议然后发送解析,本质上我们的自己定的协议和http协议并没有区别,唯一区别的是你自己定的只能在你的某个范围使用,而http协议全球通用罢了。
2,http协议版本及对应的支持的请求方式。
这里我就直接贴两张图了,第一张是http协议版本的一个简介,来源于维基百科。
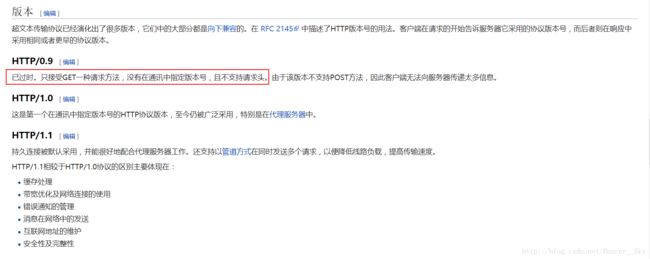
第二张就是协议请求的方式解释及版本支持。

3,http中url的组成结构。
这里偷懒,我也直接截图一张维基百科的解释了。说的也是简单明了的。

4,http请求包的基本内容组成结构。
因为我们主要还是用GET请求,那我们就主要了解一下GET请求吧,我们首先用webbench以GET方式访问百度,我们看一下打印出来的GET请求内容。
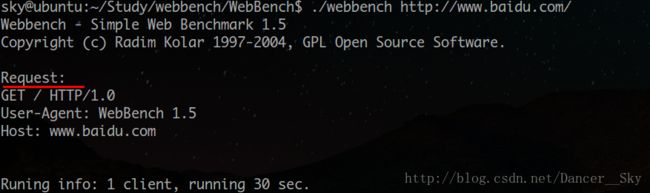
我们看图片
第一行:首先是GET 代表我们的请求方式,后面/表示我们的请求路径 后面HTTP/1.0表示我们的协议版本。
第二行:User-Agent: Webbench 1.5 其实就是表示用户身份。
第三行:Host: www.baidu.com 表示服务器主机地址。
我这也只是粗略的解释了一下意思,具体的协议还是需要详细去看一下的,我这里也是看了这篇博客,说的简单易懂。链接地址:关于HTTP协议,一篇就够了
5,http代理与非代理时请求区别。
我们使用代理时,看一下webbench的GET请求包是怎样的。
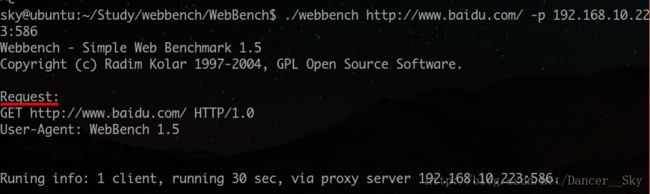
看图片我们发现第一行GET后面原来正常是跟的是我们要访问的服务器路径,现在直接变成了整个url地址,Host 那一行也没有了。
其实代理服务器就是一个中间人的作用,我们把要访问的服务器地址给代理服务器,代理服务器去访问这个地址,然后把得到的内容再返回给我们,其实就是一个中介的作用。就好比我现在想去联华买一个冰棒,然后我让同桌帮我买,那同桌就相当于代理服务器,联华超市冰棒是我们要访问的服务器地址,同桌帮你买了冰棒再拿给你,这样就完成了一个代理的流程。
详细了解可以再看看这篇博客。
基本的知识点也都说了,下面源码的解析我就直接在源码上注释了。
/*源码build_request函数源码*/
void build_request(const char *url)
{
char tmp[10];
int i;
memset(host,0,MAXHOSTNAMELEN);
memset(request,0,REQUEST_SIZE);
/*页面缓存,代理模式1.0及以上版本支持----若服务器设置了这些功能但设置的http版本协议0.9不支持,故设置为1.0版本*/
if(force_reload && proxyhost!=NULL && http10<1) http10=1;
/*支持head请求协议的是1.0及以上版本,如果配置了head但设置的又是0.9版本,让其为1.0版本*/
if(method==METHOD_HEAD && http10<1) http10=1;
/*options,trace请求1.1版本支持,故设置了此种请求而协议版本设置的为1.1版本以下就设置为1.1版本*/
if(method==METHOD_OPTIONS && http10<2) http10=2;
if(method==METHOD_TRACE && http10<2) http10=2;
/*根据method值选择请求方式*/
switch(method)
{
default:
case METHOD_GET: strcpy(request,"GET");break;
case METHOD_HEAD: strcpy(request,"HEAD");break;
case METHOD_OPTIONS: strcpy(request,"OPTIONS");break;
case METHOD_TRACE: strcpy(request,"TRACE");break;
}
strcat(request," ");
/*判断输入的url中是否含有"://"字符串*/
if(NULL==strstr(url,"://"))
{
fprintf(stderr, "\n%s: is not a valid URL.\n",url);
exit(2);
}
/*判断输入的url字节数是否大于1500bytes*/
if(strlen(url)>1500)
{
fprintf(stderr,"URL is too long.\n");
exit(2);
}
/*判断输入的url前7个字节是否为"http://"字符串*/
if (0!=strncasecmp("http://",url,7))
{
fprintf(stderr,"\nOnly HTTP protocol is directly supported, set --proxy for others.\n");
exit(2);
}
/*判断从http://后开始是否含有终止符'/'*/
i=strstr(url,"://")-url+3;
if(strchr(url+i,'/')==NULL) {
fprintf(stderr,"\nInvalid URL syntax - hostname don't ends with '/'.\n");
exit(2);
}
/*使用代理与不使用代理协议请求有区别,使用代理协议GET 后面直接跟url地址即可*/
if(proxyhost==NULL)
{
/* 不经过代理服务器时,获取服务器主机地址及端口 */
if(index(url+i,':')!=NULL && index(url+i,':')'/'))
{
strncpy(host,url+i,strchr(url+i,':')-url-i);
//bzero(tmp,10);
memset(tmp,0,10);
strncpy(tmp,index(url+i,':')+1,strchr(url+i,'/')-index(url+i,':')-1);
/* printf("tmp=%s\n",tmp); */
proxyport=atoi(tmp);
if(proxyport==0) proxyport=80;
}
else
{
strncpy(host,url+i,strcspn(url+i,"/"));
}
// printf("Host=%s\n",host);
strcat(request+strlen(request),url+i+strcspn(url+i,"/"));
}
else
{
/*使用代理服务器,GET 后面直接跟url地址即可*/
// printf("ProxyHost=%s\nProxyPort=%d\n",proxyhost,proxyport);
strcat(request,url);
}
/*选择协议版本*/
if(http10==1)
strcat(request," HTTP/1.0");
else if (http10==2)
strcat(request," HTTP/1.1");
strcat(request,"\r\n");
/*0.9版本以上加上user-agent字段*/
if(http10>0)
strcat(request,"User-Agent: WebBench "PROGRAM_VERSION"\r\n");
/*未使用代理服务器时,加上host字段*/
if(proxyhost==NULL && http10>0)
{
strcat(request,"Host: ");
strcat(request,host);
strcat(request,"\r\n");
}
/*不缓存且使用代理服务器时加上Pragma字段*/
if(force_reload && proxyhost!=NULL)
{
strcat(request,"Pragma: no-cache\r\n");
}
/*1.1版本加上Connection字段,close表示不长连接*/
if(http10>1)
strcat(request,"Connection: close\r\n");
/* 加上空行结束请求包*/
if(http10>0) strcat(request,"\r\n");
printf("\nRequest:\n%s\n",request);
} socket.c源码的Socket()函数解析
总的概括,这个函数就是建立一个tcp客户端,用于连接服务器。都是socket编程中很基础的内容,在网上这样的实例也是一搜一大堆的。所以我这里也就不重复造轮子了,只把源码函数稍微注释一下了。
/*源码*/
int Socket(const char *host, int clientPort)
{
int sock;
unsigned long inaddr;
struct sockaddr_in ad;
struct hostent *hp;
memset(&ad, 0, sizeof(ad));
ad.sin_family = AF_INET;
/*输入的host地址是否为网络地址字符串,如果是将网络地址字符串转换成网络所使用的二进制数字,网络地址字符串如:192.168.10.232*/
inaddr = inet_addr(host);
if (inaddr != INADDR_NONE)
memcpy(&ad.sin_addr, &inaddr, sizeof(inaddr));
else
{
/*解析域名地址,如www.baidu.com*/
hp = gethostbyname(host);
if (hp == NULL)
return -1;
memcpy(&ad.sin_addr, hp->h_addr, hp->h_length);
}
ad.sin_port = htons(clientPort);
/*创建套接字*/
sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock < 0)
return sock;
/*连接服务器*/
if (connect(sock, (struct sockaddr *)&ad, sizeof(ad)) < 0)
return -1;
/*返回套接字描述符*/
return sock;
}
今天内容就这么多啦,看源码还是可以学习到很多的。这样更有方向,比自己瞎看书不实践要学的更深一些。未完待续………..Peace&Love!