正则表达式 re
本文参考http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html,觉得写得很好很全面。
-
- 正则表达式的语法
- 匹配模式
- 贪婪和非贪婪
- 4个反斜杠
- re模块
- recompile函数
- research和rematch函数
- resplit函数
- refindall函数
- refinditer函数
- resub函数
- resubn函数
- RegexObject类
- MatchObject类
- group函数
- groups函数
- groupdict函数
- startend函数
- span函数
正则表达式的语法
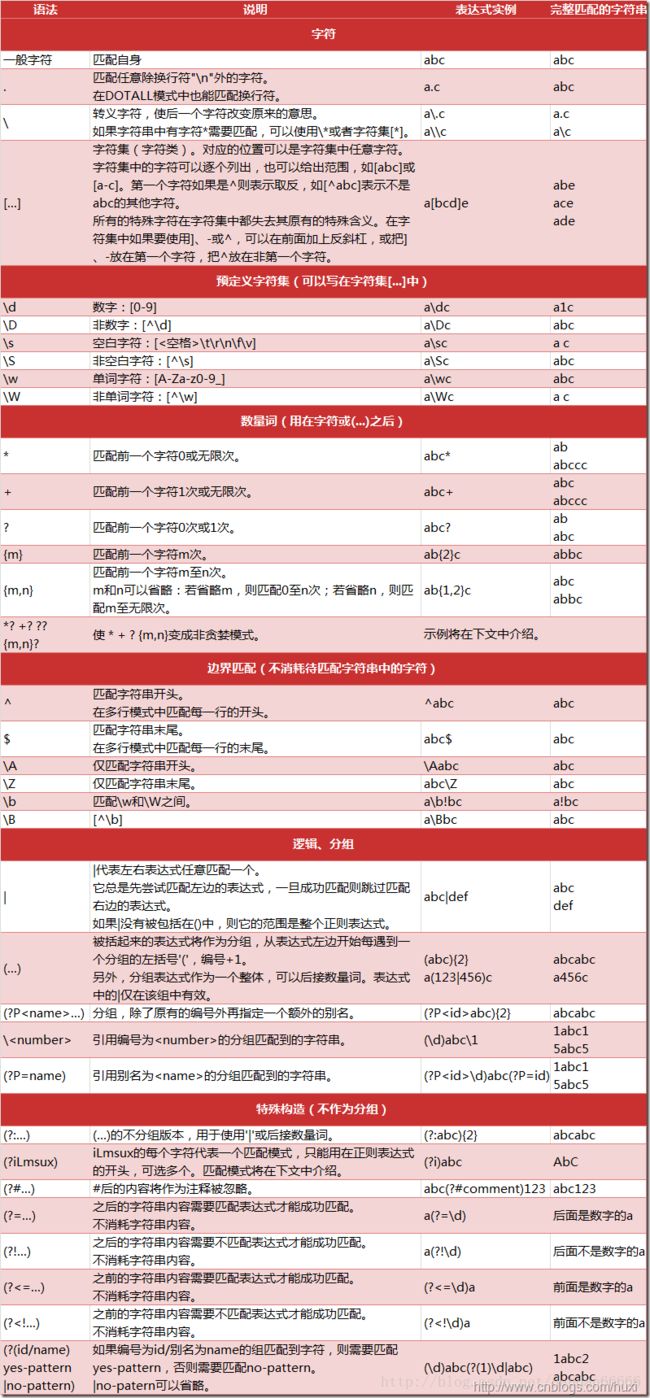
匹配模式
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变’^’和’$’的行为(参见上图)
- S(DOTALL): 点任意匹配模式,改变’.’的行为
- L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
贪婪和非贪婪
*、+、?都是贪婪的,会匹配尽可能多,如果在之后再加一个?变成*?、+?、??就会变成非贪婪的,即一旦匹配完成就终止。{m, n}也类似。
import re
s = 'b'
# <.*> 匹配 b4个反斜杠
反斜杠在python中作为转义符,所以在命令行输入’\’
其实会被变成’\\’
>>> s = raw_input()
\
>>> s
'\\'而在正则表达式中,反斜杠也是作为转义符,所以为了匹配1个字符意义上的反斜杠,需要4个反斜杠
re模块
re.compile函数
re.compile(pattern, flags=0)re.compile返回一个RegexObject对象。
re.search和re.match函数
re.search(pattern, string, flags = 0)
re.match(pattern, string, flags = 0)这两个都返回MatchObject对象(没有匹配到就返回None)。
- pattern就是一个正则表达式
- string是要看是否匹配的普通字符串
- flags可选上面所说的匹配模式,可用 |(or)隔开。
search和match不一样的地方在于match必须从头开始匹配,如果一开始不匹配就返回None,search可以从中间开始匹配。
re.split函数
语法:re.split(pattern, string, maxsplit = 0, flag = 0)
pattern匹配到用于分割的字符串
- 如果pattern没有括号,不返回用于分割的字符串
- 如果pattern有括号,同时返回用于分割的字符串
maxsplit为最多分割次数
>>> re.split('\W+', 'Words, words, words.')
['Words', 'words', 'words', '']
>>> re.split('(\W+)', 'Words, words, words.')
['Words', ', ', 'words', ', ', 'words', '.', '']
>>> re.split('\W+', 'Words, words, words.', 1)
['Words', 'words, words.']
>>> re.split('[a-f]+', '0a3B9', flags=re.IGNORECASE)
['0', '3', '9']如果捕获到的分组位于句首,会多返回一个空字符串
>>> re.split('(\W+)', '...words, words...')
['', '...', 'words', ', ', 'words', '...', '']re.findall函数
语法: re.findall(pattern, string, flag = 0)
返回一个list,为符合pattern匹配的分组的字符串(符合所有括号中表达式匹配的字符串),按顺序组成一个tuple
- 如果有多种匹配方式,返回含有多个tuple的list
- 如果没有子分组(),返回整个pattern匹配的字符串(贪婪匹配)
>>> re.findall(r"(\d+)\.(\d+)", "24.1632")
[('24', '1632')]re.finditer函数
语法:re.finditer(pattern, string, flags = 0)
与findall类似,但是返回MatchObject的迭代器
re.sub函数
语法:re.sub(pattern, repl, string, count = 0, flags = 0)
- pattern为要匹配的正则表达式
- repl为匹配到的字符串的替代字符串
- string为要被操作的字符串
- count为被替代的个数(默认全部替代)
- 返回结果字符串,而string保持不变
re.subn函数
语法:re.subn(pattern, repl, string, count = 0, flags = 0)
与re.sub类似,但是返回一个tuple(结果字符串,被替代的个数)
>>> re.subn('a', '1', 'abadbsdadfsa')
('1b1dbsd1dfs1', 4)
>>> re.subn('a', '1', 'abadbsdadfsa', 2)
('1b1dbsdadfsa', 2)RegexObject类
RegexObject对象支持的方法和属性
# 匹配前闭后开,返回从[pos, endpos)的匹配MatchObject对象
search(string[, pos [, endpos]])
# 与search类似,不同的是必须从pos开始匹配
match(string [, pos [, endpos]])prog = re.compile(pattern)
prog.match(string)
# 等价于
result = re.match(pattern, string)
split(string, maxsplit=0)
findall(string [, pos [, endpos]])
finditer(string [, pos [, endpos]])
sub(repl, string, count = 0)
subn(repl, string, count = 0)
flags
groups
groupindex
patternMatchObject类
group函数
语法:group([group1, …])
正则表达式pattern可能有多个子分组(),用group可以返回总的匹配结果和各个子分组。
>>> m = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
# m.group(0)等价于m.string
>>> m.group(0) # 总的匹配结果
'Isaac Newton'
>>> m.group(1) # 第一个括号子分组
'Isaac'
>>> m.group(2) # 第二个括号子分组
'Newton'
>>> m.group(1, 2)
('Isaac', 'Newton')
# 也可以用别名进行匹配
>>> m = re.match(r"(?P\w+) (?P\w+)" , "Malcolm Reynolds")))
>>> m.group('first_name')
'Malcolm'
>>> m.group('last_name')
'Reynolds'
# 如果一个分组匹配多次,返回最后一次匹配结果
>>> m = re.match(r'(..)+', 'a1b2c3')
>>> m.group(1)
'c3'groups函数
语法:groups([default])
一次返回所有子分组的匹配结果(tuple),default为没有匹配到设定的缺省值,如果没有设定且没有匹配到返回None
>>> m = re.match(r'(\d+)\.(\d+)', '24.1632')
>>> m.groups()
('24', '1632')
>>> m = re.match(r'(\d+)\.(\d+)?', '24')
>>> m.groups()
('24', None)
>>> m.groups('0')
('24', '0')groupdict函数
语法:groupdict([default])
与groups()类似,但是显然返回的是一个dict, key为别名,如果没有命名就不返回
>>> m = re.match(r"(?P\w+) (?P\w+)" , "Malcolm Reynolds")
>>> m.groupdict()
{'first_name': 'Malcolm', 'last_name': 'Reynolds'}
>>> m = re.match(r"(?P\w+) (\w+)" , "Malcolm Reynolds")
>>> m.groupdict()
{'first_name': 'Malcolm'}start、end函数
语法:start([group])、end([group])
group为match匹配到的分组的组号(0为整个匹配,1为第1个分组,2为第2个分组,…)缺省为0
start([group])和end([group])就为分组的开始index和结束的index(前闭后开)
与group不同的是(函数本身就不同),group函数可以接受多个参数,返回多个分组,start和end函数只能接受一个参数,返回一个index
>>> email = "tony@tiremove_thisger.net"
>>> m = re.search("remove_this", email)
>>> email[:m.start()] + email[m.end():]
'[email protected]'span函数
语法:span([group])
等价于(m.start(group), m.end(group))
如果不存在这个分组返回(-1, -1)
group缺省为0,即整个匹配结果
例子和说明都来自官方文档,但是还有一些比较少见的函数和属性没有写。不过应该是我写的最全面的了吧。像这种有官方文档的非理解性的知识都很不愿意写,毕竟一查就查到了。但是这么基础的东西不懂的话,写代码又要花很多时间查也是挺烦的,希望写完可以记住吧。