二.SQL语句优化
一.慢查询
1.作用
把运行时间较长的SQL语句记录下来.
2.开启
(1)查看是否开启慢查询
show variables like 'slow_query_log';(2)记录未使用索引的查询
set global log_queries_not_using_indexes=on;(3)慢查询时间
show variables like 'long_query_time';//查看慢查询时间
set global long_query_time=0;//设置慢查询时间(4)开启慢查询
set global slow_query_log=on;(5)慢查询日志的位置
show variables like 'slow_query_log_file';(6)慢查询日志的格式
#Time:140606 12:30:17
#User@Host:root[root]@localhost[]//执行SQL的主机信息
#Query_time:0.000000031 Lock_time:0.000000000 Rows_sent:0 Rows_examined:0//SQL的执行信息
SET timestamp=1402029017;//SQL执行时间
show tables;//SQL的内容二.慢查询分析工具
1.mysqldumpslow
mysqldumpslow -t 3 慢查询日志路径2.pt-query-digest
pt-query-digest 慢查询日志路径三.通过慢查询日志分析SQL语句
1.查询次数多且每次查询占用时间长的SQL
通常为pt-query-digest 分析的前几个查询
2.IO大的SQL
注意pt-query-digest 分析中的Rows examine项
3.未命中索引的SQL
注意pt-query-digest 分析中Rows examine 和 Rows Send 的对比
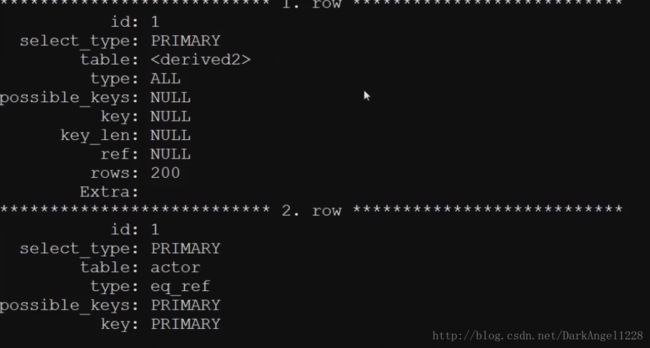
四.通过explain查询和分析SQL的执行计划
explain返回各列的含义
table:显示这一行的数据是关于哪张表
type:这是重要的列,显示连接使用了何种类型.从最好到最差的连接类型为:const、eq_reg、ref、range、index和All.
possible_keys:显示可能应用在这张表中的索引.如果为空,没有可能的索引.
key:实际使用的索引.如果为null,则没有使用索引.
key_len:使用的索引长度.在不损失精确性的情况下,长度越短越好.
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数.
rows:MySQL认为必须检查的用来返回请求数据的行数.
extra:
①Using filesort:看到这个的时候,查询就需要优化了.MySQL需要进行额外的步骤来发现如何对返回的行排序.它根据连接类型及存储排序键值和匹配条件的全部行的行指针来排序全部行.
②Using temporary:看到这个的时候,查询需要优化了.这里,MySQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上.
五.count()和max()的优化
1.max()通过添加索引来优化
//查询最后支付的时间
explain select max(payment_date) from payment
//建立索引
creat index idx_paydate on payment(payment_data);explain select max(payment_date) from payment
2.count()优化
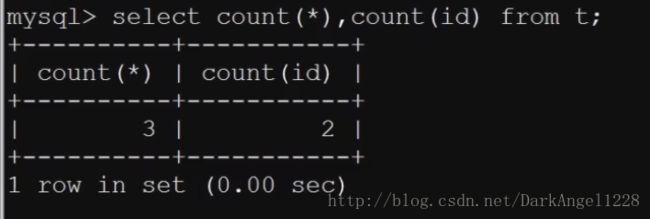
count(*)包含null值 而count(id)不包含null值.
六.join代替子查询
通常情况下,需要把子查询优化为join查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据.
#七.优化group by查询
explain select actor.first_name,actor.last_name,count(*) from sakila.fim_actor inner join sakila.actor using(actor_id) group by film_actor.actor_id;
优化后
explain select actor.first_name,actor.last_name,c.cnt from sakila.actor inner join(select actor_id,count(*) as cnt from sakila.film_actor group by actor_id) as c using(actor_id);优化后