Hadoop2.8 安装心得
一、从下载badoop、安装jdk、配置ssl无密码登录等内容都是一步步的按照《细细品味hadoop》来进行
区别在于,细细品味是以1.x为标杆编写的。所以关于2.x的配置文件的写法,参考本文而非《细细品味》
二、2.x的最大进步在于,引入了yarn,在这个系统中,mapreduce成为了它的一个组件而存在,并且是可替换的组件。比如使用spark。所以配置的过程中,需要注意yarn的相关配置文件的使用
三、具体配置共有7个,包含以下内容
~/hadoop/etc/hadoop/hadoop-env.sh
~/hadoop/etc/hadoop/yarn-env.sh
~/hadoop/etc/hadoop/slaves
~/hadoop/etc/hadoop/core-site.xml
~/hadoop/etc/hadoop/hdfs-site.xml
~/hadoop/etc/hadoop/mapred-site.xml
~/hadoop/etc/hadoop/yarn-site.xml1:hadoop-env.sh
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
故在该文件中修改JAVA_HOME值为本机安装位置(如,export JAVA_HOME=/usr/local/java/jdk1.7.0_79)

2:yarn-env.sh
该文件是yarn框架运行环境的配置,同样需要修改java虚拟机的位置。
在该文件中修改JAVA_HOME值为本机安装位置(如,export JAVA_HOME=/usr/local/java/jdk1.7.0_79)

3:slaves
该文件里面保存所有slave节点的信息,我这里写的是ip

说明:slaves文件中可以写ip地址,也可以写成/etc/hosts里从机的主机名,任选一种即可
比如写主机名可以是这个形式:xxCentosTwo、xxCentosThree

4:core-site.xml
这个是hadoop的核心配置文件,这里需要配置的就这两个属性,fs.default.name配置了hadoop的HDFS系统的命名,位置为主机的9000端口;hadoop.tmp.dir配置了hadoop的tmp目录的根位置。需要新建一个tmp目录
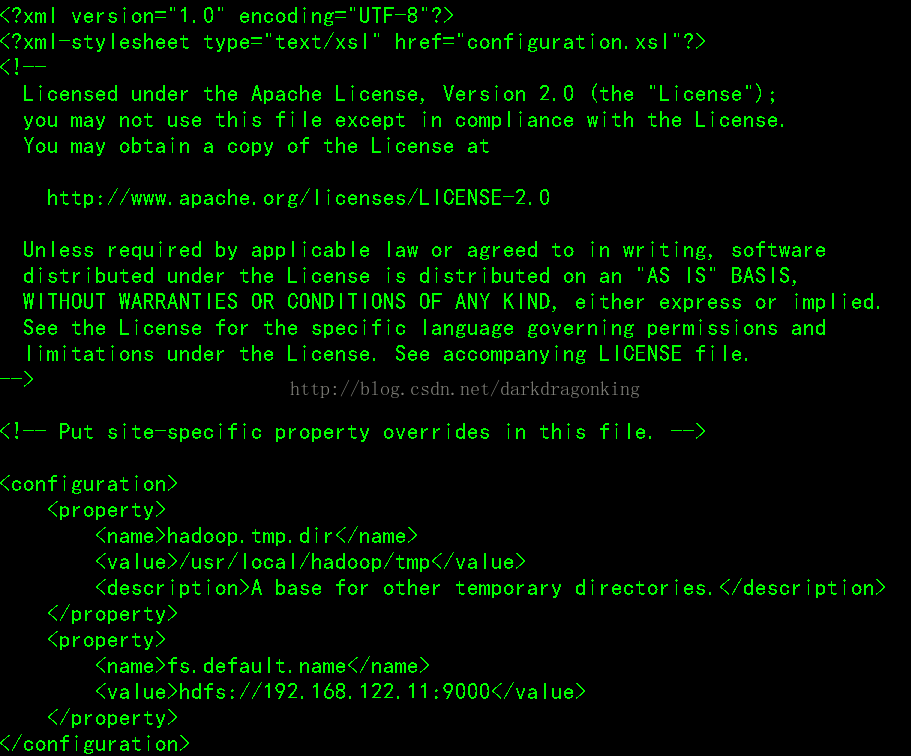
这里有个最大的问题,就是使用了ip地址。这样维护性比较差,当你的ip地址修改的话,如果这里每一个地方都写ip,那么每一个配置文件都要修改,工作量巨大。还是写主机名更方便。
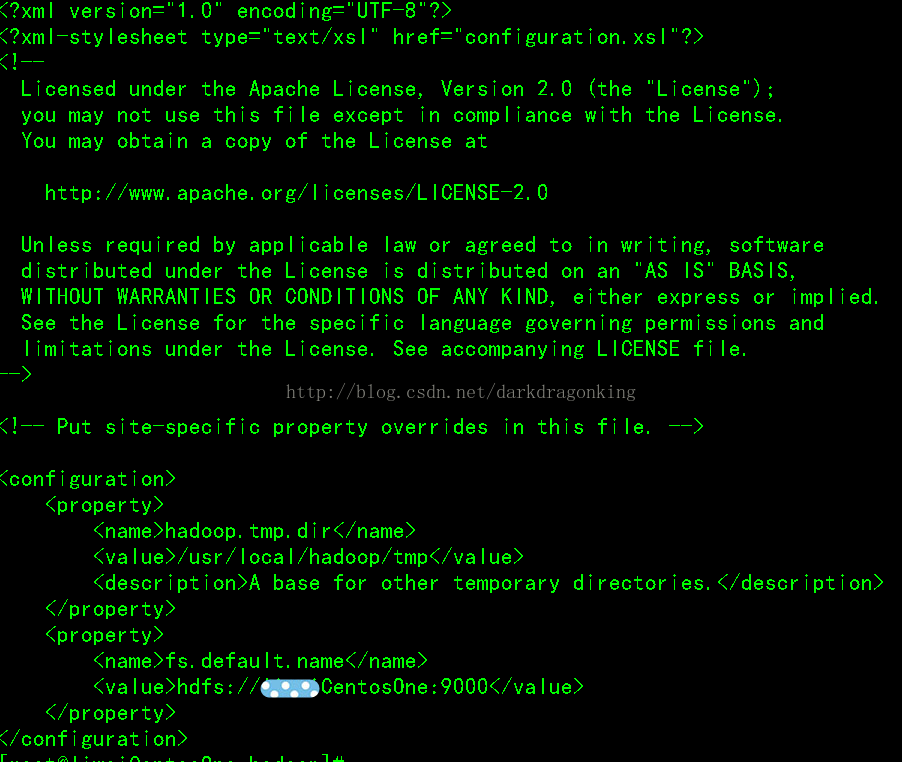
5:hdfs-site.xml
这个是hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置;dfs.replication配置了文件块的副本数,一般不大于从机的个数。这部分我不明白

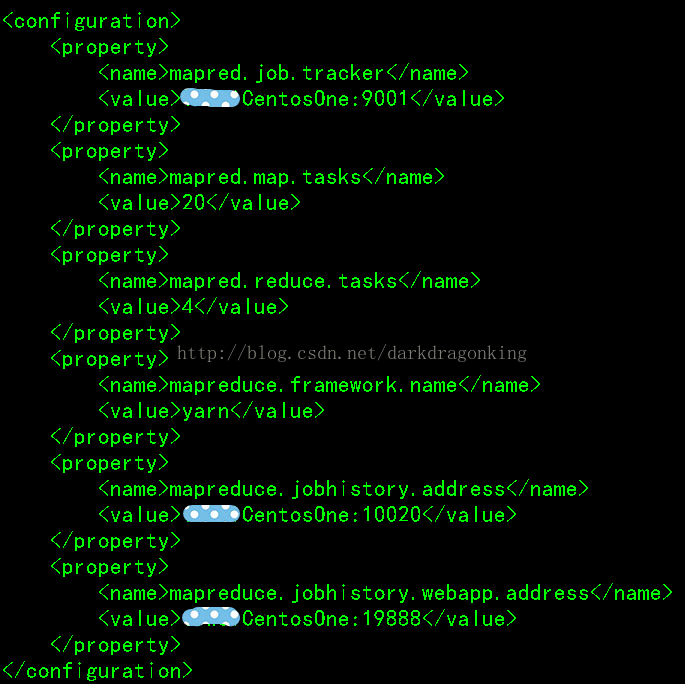
6:mapred-site.xml
这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数,至于什么是map和reduce,可参考其它资料进行了解。
其它属性为一些进程的端口配置,均配在主机下。

7:yarn-site.xml
该文件为yarn框架的配置,主要是一些任务的启动位置
四、至此,配置性内容都已完成。后面就是启动和验证
在任意位置执行dfs namenode -format(因为按照《细细品味》中的操作,已经把hdfs这些命令配置到环境变量中了,所以不需要在前面加上./bin/这些东西了。)这一步是格式化namenode
然后在 /usr/local/hadoop/sbin/下执行./start-all.sh。启动所有该启动的内容即可,如果过程中出现停止在那里不动的,可以考虑是否因为ssh的问题,可以先执行ssh 到其他的datanode去试一下之前配置的无密码ssh是否正确。如果正确并且也验证过这个无密码的ssh的话,这个./start-all.sh应该会正常执行完毕。
如果有其他异常的话,可以参考logs中的日志。
正常启动后,namenode上面运行的进程有:namenode secondarynamenode resourcemanager
而datanode上面运行的进程有:datanode nodemanager
检查启动结果:
1、查看集群状态:hdfs dfsadmin –report
2、查看文件块:hdfsfsck / -files -blocks
3、查看hdfs:http://192.168.122.11:50070(主机IP)
4、查看MapReduce:http://192.168.122.11:8088(主机IP)