数据流分析(二)
想学数据流分析的人还是找一个国外大学的讲义学吧,以下内容都是自己多年前按照自己的理解写的,很多内容可能会误人子弟,sorry
#引子
我们在数据流分析(一)中简要介绍了数据流分析的基本概念,下面我们集中分析一些数据流分析的实例来阐述数据流分析的核心思想。
- 到达定值
- 活变量
- 可用表达式
##到达定值
###什么是到达定值
“到达定值”是最常见的和有用的数据流模式之一。编译器能够根据到达定值信息知道 x 在点 p 上的值是否为常量,而如果 x 在点 p 上被使用,则调试器可以指出x是否未经定值就被使用。
如果存在一条从紧随在定值 d 后面的程序点到达某一个程序点 p 的路径,并且在这条路径上 d 没有被“杀死”,我们就说定值 d 到达程序点 p 。如果在这条路径上有对变量x的其他定值,我们就说变量 x 的这个定值(定值 d )被"杀死"了。 《编译原理》
到达定值的示意图如下所示。
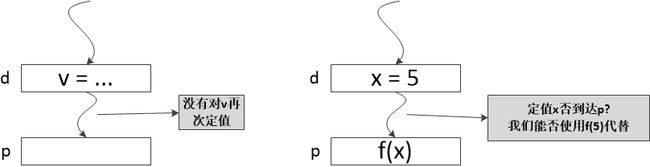
注:上面这个图不严谨,p是程序点,应该紧挨着下面的矩形而不是表示矩形。图中的矩形表示的是一条语句。
到达定值有以下用法:
- 创建use/def链
- 常量传播
- 循环不变量外提
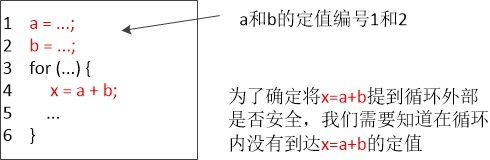
变量x的一个定值是(可能)将一个值赋给x的语句。过程参数、数组访问和间接引用都可以有别名,因此指出一个语句是否向特定程序变量x赋值并不是件很容易的事情。 《编译原理》
存在别名的情况下的需要作别名分析,如果为了提高分析效率而不介意损失一些分析精度的话,可以做保守估计,例如我们不知道当前语句对哪个变量赋值,我们就在此处针对每个变量产生一个定值。这是一种无奈的折中。此处我们不考虑别名情况。
###到达定值的传递函数
首先我们做一些假设:
- 一个语句节点至多能够对一个变量定值
- 我们可以通过节点编号索引到该赋值语句
当然,在实际情况中一个语句节点有可能会对不止一个变量定值。下面我们定义一下 gen [n]函数和 kill [n]函数。
gen[n] :节点 n 产生的定值(假设一个语句节点至多一个定值)
kill[n] :节点 n“杀死”的定值
| 程序语句 | gen[s] | kill[s] |
|---|---|---|
| s: t = b op c | {s} | def[t] - {s} |
| s: t = M[b] | {s} | def[t] - {s} |
| s: M[a] = b | {s} | {*} - {s} |
| s: if a op b goto L | {} | {} |
| s:goto L | {} | {} |
| s: L: | {} | {} |
| s: f(a, …) | {} | {} |
| s: t = f(a, …) | {s} | def[t] - {s} |
上面的表格列举了一些程序语句的 gen 和 kill 传递函数形式。第一行的列举的**“s: t = b op c”**,产生了定值s并"杀死"了除定值s以外所有对变量t的定值。
注意:定值是一个程序语句,对同一个变量可以存在多个不同的定值
我们也可以先计算出各个程序语句的 gen 和 kill 结果,然后综合基本块中的各个语句生成整个基本块的 gen 和 kill 集合。如下图所示,其中我们先默认各个基本块的起始和结束处所有定值都可以到达,下图程序中总共有7个定值,分别为***d1***, d2, d3, d4, d5, d6, d7。
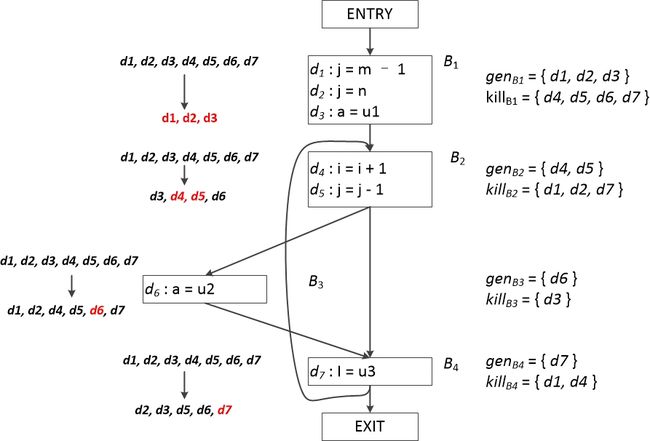
经过第一次的传递函数作用,各个基本块到达定值集合的变化情况如图左所示。
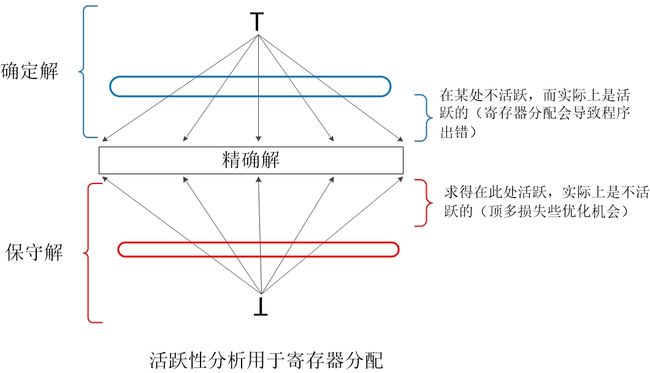
###到达定值的保守性
在前面介绍数据流分析时,曾经提到过数据流分析允许一定的不精确性。但是它们都是在“安全”或者说“保守”的方向上不精确。如下图所示:
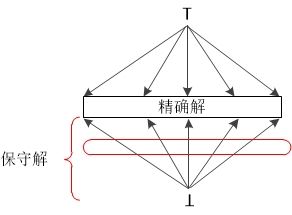
只要我们得到的解偏于保守的一方即可,然后再尽力的向精确的方向靠近,不同的应用“保守”的定义也不同。在 大部分到达定值的应用 中,在一个定值不可能到达某点的情况下假设其能够到达是保守的。如下图所示:
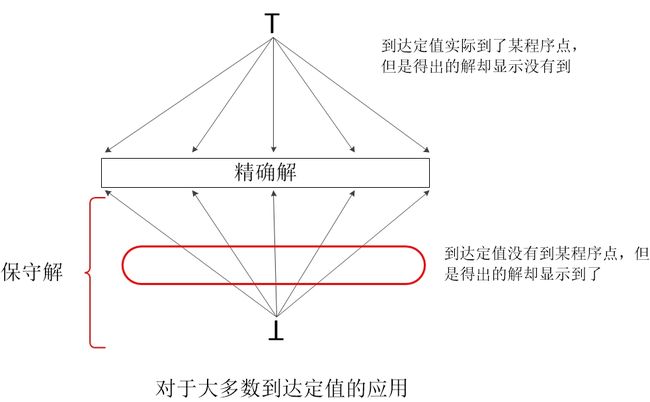
因此在设计一个数据流模式的时候,我们必须知道这些信息将如何被使用,并保证我们做出的任何估算都是在“保守”或者说“安全”的方向上。每个模式和应用都要单独考虑。 《编译原理》
也就是说,不能套用同一个模式来判断“保守”或者“安全”的方向,在可用表达式中,“安全”的定义就和到达定值不同。如果可用表达式没有到达某个程序点,而得出的解表明到达了,则这是不安全的。
###到达定值的传递方程以及控制流方程
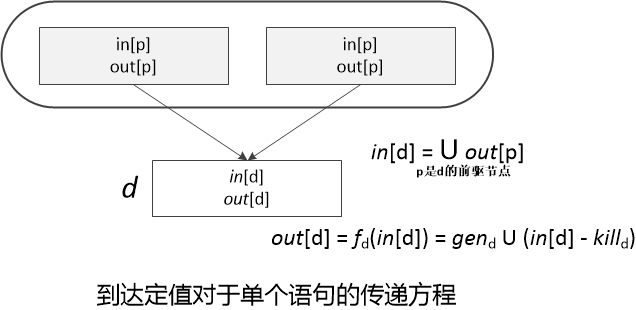
到达定值对于单个语句的传递方程如下图所示,一个基本块内的依据就是按照这组方程建立起联系的。和单个语句一样,一个基本块也会生成一个定值集合,并杀死一个定值集合。
根据基本块之间的控制流得到的约束集合,我们可以生成一个控制流方程。其实控制流方程的含义就是在路径交叉点进行数据流值的交汇,在到达定值中,交汇运算就是并集运算(∪)。
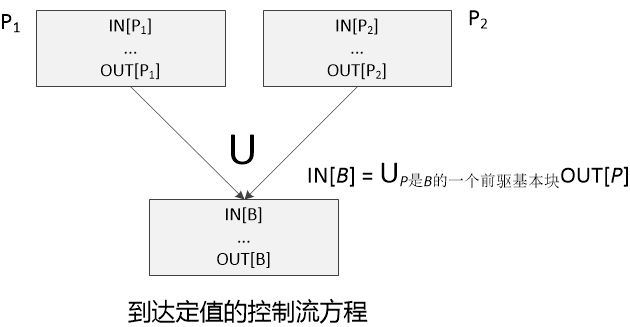
对于到达定值来说,只要一个定值能够沿着至少一条路径到达某个程序点,就说这个定值到达该程序点。所以控制流方程的交汇运算时并集,但是对于其他一些数据流问题交汇运算时交集,例如可用表达式。
###到达定值的迭代分析算法
假设每个控制流图都有两个空的基本块,代表了控制流图的ENTRY节点和EXIT节点。由于没有定值到达这个图的开始,所以基本块ENTRY的传递函数是一个简单的返回空集Ø的常函数,即OUT[ENTRY] = Ø.
到达定值问题使用下面方程的定义:
OUT[ENTRY] = Ø
且对于所有的不等于ENTRY的基本块B,有
OUT[B] = gen(B) U ( IN[B] - kill(B) )
IN[B] = U OUT[P] ,其中P是B的一个前驱基本块
我们可以使用下面的算法来求这个方程组的解。这个算法来自《编译原理》中到达定值部分。
到达定值算法:
输入:一个流图,其中每个基本块 B 的 kill(B) 集和 gen(B) 集都已经计算出来了。
输出:到达流图中各个基本块 B 的入口点和出口点的定值的集合,即 IN[B] 和 OUT[B] 。
方法:我们使用迭代的方法来求解。一开始,我们“估计”对于所有基本块 B 都有 OUT[B] = Ø,并逐步逼近想要的 IN 和 OUT 值。因为我们必须不停地迭代直到各个 IN 值(因此各个 OUT 值也)收敛,所以我们使用一个 bool 变量 change 来记录每次扫描各基本块时是否有 OUT 值发生改变。

从算法中我们可以明确看到,数据流值是从前驱 P 到 IN[B] 然后再流向 OUT[B] 这样一个从前向后不断传播的。然后从Ø 不断扩大直到越过精确解到达“保守解”。
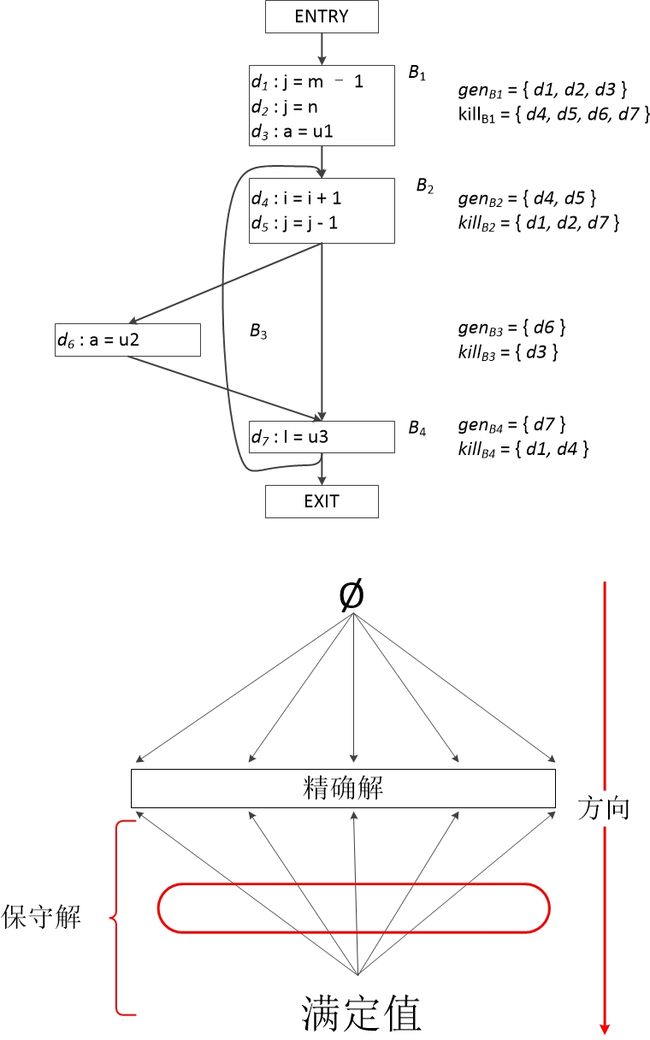
迭代算法不断从空向到达定值结果越来越多的方向靠近,最终会跨越精确解到达保守解的部分,主要因为两个原因导致一定会越过精确解:
(1)不考虑路径条件,假设所有路径都可达;这样某些定值最终会到达他们本来到达不了的地方
(2)存在别名时,给无法确认的“别名”赋值时,给所有变量添加一个定值(注意此处并没有kill掉所有的定值,因为添加所有可能的定值,删除肯定被kill掉的定值,这样才能保证“保守”)
这个算法还有可以改进的地方,其中一个就是精心安排迭代分析时基本块的顺序,基本按照CFG从入口ENTRY到EXIT的顺序。在《迭代数据流分析中的逆后序(Reverse Postorder)》中我们会提到,对于前向数据流问题来说,逆后序是最高效的方式。如果当前基本块的到达定值结果发生了改变,那么就把其所有后继基本块加入待迭代的工作列表 WorkList 。
另外到达定值使用了一种位向量的结构,来表示到达定值集合。即每个程序点的到达定值使用一个位向量表示,例如该程序有7个定值,那么位向量为7位,初始向量“0000 000”表示此时定值为空,如果第3号定值到达了当前程序点,那么位向量为“0010 000”。
##活跃变量分析
活跃变量分析是一个后向数据流分析问题,因为当前变量x是否在未来的某个地方被用到,只能通过从后面节点的信息中获知。
A variable is live at a particular point in the program if its value at that point will be used in the future(dead, otherwise)
To compute liveness at a given point, we need to look into the future
活跃变量的重要用途之一是为基本块进行寄存器分配。计算机技术中有很多类似于寄存器分配的场景,也就是有限的资源去满足无限的需求,例如cache有限,但是欲放入cache的数据却又很多;另或者主存空间有限,而磁盘中欲放如主存的数据有很多等。所以这时候就需要某种资源共享,保证不冲突,并且采用某种算法来求得把资源分配给哪些数据更合理。例如LRU换页算法,或者cache的空间局部性原理等。当然这些问题都不是程序员需要深入考虑的,底层软件或工具软件会在背地里完成。
Register Allocation
- A program contains an unbounded number of variables
- Must execute on a machine with a bound number of registers
- Two variables can use the same register if they are never in use at the same time(i.e, never simultaneously live).
所以寄存器分配需要活变量的信息来决定两个变量能否使用同一个寄存器,另外在所有寄存器都被占用时,如果我们还需要申请一个寄存器的话,那么应该考虑使用一个存放了已死亡的值的寄存器,因为这个值我们不需要保存到内存,无需register spill。
###活跃变量的数据流方程
我们给出两个定义:
- def(or definition)
- use
def[v] = 定义变量v的所有CFG节点集合
def[n] = 节点n定义的变量集合
use[v] = 使用变量v的CFG节点集合
use[n] = 在节点n使用的变量集合
计算活跃性的规则:
(1)产生活跃性

(2)活跃性如何越过程序语句节点之间的边
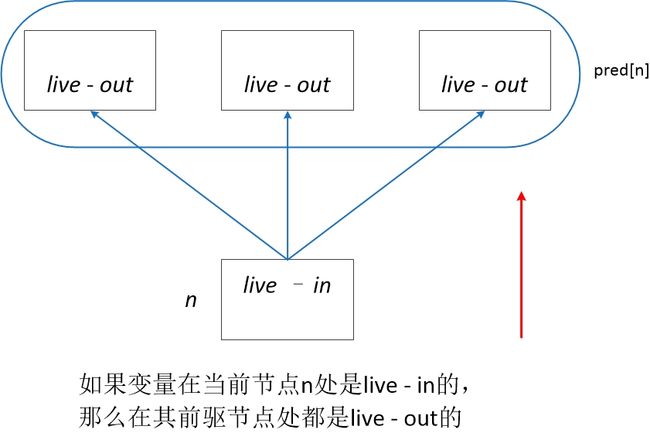
(3)活跃性如何越过程序语句节点
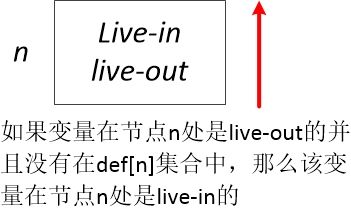
我们列出活跃变量的数据流方程如下所示,注意此处我们将语义约束和控制约束同时写出来了(因为我们现在是以单个程序语句为图节点,而不是单个基本块)
- in [n] = use [n] U ( out [n] - def [n] )
- out [n] = U in [s] , 其中s是节点n的后继节点
从这两个方程我们可以看出,对于活跃变量分析来说数据流是从后向前传播的。我们这里解释一下为什么要从out[n]中删除def[n],
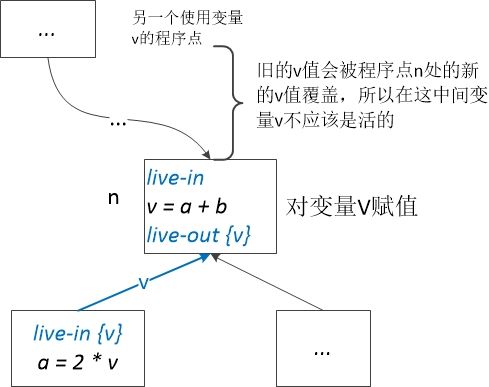
下面给出活跃变量分析的算法:

注:此处CFG是以程序语句为单个节点构建的
当然这个算法没有考虑到CFG图中节点的顺序,效率比较低,我们将CFG图中的节点反序,用来求解。改进算法如下:

我们也可以基本块为单位来就行活跃变量的分析,但是我们得首先根据基本块中程序语句的传递函数合并成为基本块的传递函数。定义如下:
- def [B] 是指如下变量的集合,这个变量在B中的定值(即被明确地)先于任何对它们的使用
- use [B]是指如下变量的集合,它们的值可能在B中先于任何对它们的定值被使用
注意:上述我们标注的黑色部分,在def[B]中需要被明确定值,而在use中条件弱化,只需要可能就行了。类似于到达定值,这样做是为了保守性。在活跃变量中,假设变量活跃到程序结束是没有问题的,只是会损失些可以优化的点(例如寄存器分配时两个变量的活跃区间相互重叠的概率就会变得很大),但是如果将变量的活跃期缩短的话,有可能就将该寄存器挪做他用,这样就会导致程序错误。所以在活跃变量分析中,将活跃变量尽可能的向前传播是有利于偏向保守的。但是不能一味的偏于保守,否则得到的信息就没有任何价值,在保证保守的同时,尽可能的向精确解靠拢(所以杀死被明确赋值的变量)
所以我们在杀死变量时(即在基本块内明确定义,在 def[B] 中)必须明确规定,但是尽可能地向前传播(也就是如果可能在use[B] 中,直接加入就好)。如下图所示,我们所求得的结果必须能够保证在保守解部分,并尽力向精确解靠近。为了保证保守性,需要做到如下两点:
- 忽略路径分支条件,保证所有路径都可达
- 只要有可能是活的,就向其中加入该变量。只有在该活跃变量被明确杀死时(例如被明确赋值),才删除
如果以基本块为单位,那么得到的数据流方程如下图所示:

第一个方程描述了边界条件,即在程序出口处没有变量是活跃的。
第二个方程说明一个变量要在进入一个基本块时活跃,必须满足两个条件中的一个:要么它在基本块内被重新定值之前就被使用;要么它在基本块的出口处活跃且在基本块内没有对它进行重新定值。
第三个方程说明一个变量在一个基本块的出口处活跃当前仅当它在该基本块的某个后继入口处活跃。
和到达定值相同,活跃变量不需要在后继基本块入口都活跃,只要在其中一个基本块入口活跃即可。但是活跃变量是后向数据流模式。在各个数据流模式中,我们都沿着路径传播信息,有的数据流问题,要求对应性质需要在所有路径上都成立,而有的数据流只需要存在一个满足该性质的路径即可。
基于基本块的活跃变量分析算法:
输入:一个流图,其中每个基本块的use和def已经计算出来了。
输出:该流图中的各个基本块B的入口和出口处的活跃变量集合,即 IN[ B ] 和 OUT[ B ]。

该算法得到的具有最小活跃变量(亦即尽量向精确解靠近)的集合。