- NV183NV185美光固态闪存NV196NV201
18922804861
服务器科技人工智能大数据
美光固态闪存技术深度解析:NV183、NV185、NV196与NV201系列一、技术架构与核心参数对比1.制程工艺与容量布局美光NV183/NV185/NV196/NV201系列采用176层3DNAND技术,通过垂直堆叠提升存储密度。其中:NV183:主打256GB容量段,适用于消费级SSDNV185:可扩展至1TB-2TB范围,面向主流PCIe4.0市场NV196:企业级规格,支持4TB-8TB
- React 核心原理与Fiber架构
旺代
react.js
目录一、虚拟DOM二、Diffing算法三、Fiber架构四、渲染流程1.Render阶段(可中断异步过程)2.Commit阶段(同步不可中断)五、时间切片(TimeSlicing)六、核心流程步骤总结1.状态更新触发2.Render阶段(异步可中断,构建Fiber树)3.Commit阶段(同步不可中断,更新真实DOM)4.双缓存机制切换5.调度系统核心支撑七、组件触发渲染的时机八、Hooks顶层
- Solidity 合约引入、调用、继承与重写详解
yoona1020
区块链Solidity继承重写
目录引言一、引入其他合约二、调用已部署合约三、代码讲解四、继承与重写(override)(一)基础继承与重写(二)多重继承与override(Base1,Base2)(三)super调用多层父方法(四)重写可见性与函数签名五、构造函数继承总结引言在Solidity开发中,模块化设计是构建高效、可维护智能合约的关键。通过引入其他合约、调用已部署合约以及合理使用继承与方法重写,开发者可以实现代码复用、
- Java 数据类型详解:从初学者到理解底层原理
超浪的晨
java合集开发语言java后端
作为一名Java开发工程师,你可能已经对数据类型有了一定的了解。但无论你是刚入门的新手,还是想系统回顾基础知识的老手,这篇文章都将帮助你全面、深入地掌握Java中的数据类型。一、什么是数据类型?在Java中,数据类型(DataType)决定了变量可以存储什么类型的数据,以及该变量占用多少内存空间。Java是一种静态类型语言,也就是说,在声明变量时必须指定其数据类型。Java的数据类型可以分为两大类
- STM32定时器详细教程
楠离啊
c语言stm32嵌入式硬件单片机
STM32定时器1.引言STM32微控制器以其丰富的外设和强大的性能,在嵌入式领域得到了广泛应用。其中,定时器作为其核心外设之一,在实现精确时间控制、波形生成、事件测量等方面发挥着不可替代的作用。本教程将深入探讨STM32定时器的分类、工作原理、主要寄存器配置以及常见应用,旨在帮助读者全面理解并熟练运用STM32定时器。2.STM32定时器分类STM32系列微控制器通常包含以下三类定时器:基本定时
- MySQL中查询JSON数组字段包含特定字符串的方法
一勺菠萝丶
mysqljson数据库
问题背景在MySQL数据库中,当某个字段存储的是JSON数组(如["喷绘","2.6m喷绘","M喷绘","直喷","双透","气模"]),需要查询数组中包含特定字符串(如’气模’)的记录时,传统的LIKE语句无法直接使用。本文介绍两种高效的解决方案。解决方案对比1.精确匹配方案(推荐)当需要完全匹配数组中的元素时(如精确查找"气模"):SELECT*FROMprocess_unit_prices
- 洛谷 P13016 [GESP202506 六级] 最大因数-普及/提高-
智趣代码实验室
洛谷算法数据结构洛谷c++
题目描述给定一棵有10910^9109个结点的有根树,这些结点依次以1,2,…,1091,2,\dots,10^91,2,…,109编号,根结点的编号为111。对于编号为kkk(2≤k≤1092\leqk\leq10^92≤k≤109)的结点,其父结点的编号为kkk的因数中除kkk以外最大的因数。现在有qqq组询问,第iii(1≤i≤q1\leqi\leqq1≤i≤q)组询问给定xi,yix_i,
- 洛谷 P11251 [GESP202409 八级] 美丽路径-普及/提高-
智趣代码实验室
洛谷算法深度优先图论洛谷
题目描述小杨有一棵包含nnn个节点的树,节点从111到nnn编号。每个节点要么是白色,要么是黑色。对于树上的一条简单路径(不经过重复节点的路径),小杨认为它是美丽的当且仅当路径上相邻节点的颜色均不相同。例如下图,其中节点111和节点444是黑色,其余节点是白色,路径2−1−3−42-1-3-42−1−3−4是美丽路径,而路径2−1−3−52-1-3-52−1−3−5不是美丽路径(相邻节点333和5
- 目前比较主流的内网穿透方式 你用过几个
weixin_34365417
嵌入式数据库c#
有时候,我们在外想要访问家里或公司主机的资料,要么由于主机处于内网下,要么就是是运营商随机分配的一个公网IP,都很难直接连上主机获取资料。那么,有什么办法可以解决这一难题?答案就是内网穿透。当内网中的主机没有静态IP地址要被外网稳定访问时可以使用内网穿透NATAPP基于ngrok的国内收费内网穿透工具,免费版本:提供http,https,tcp全隧道穿透,随机域名/TCP端口,不定时强制更换域名/
- 大图处理优化:低分加载、Lazy Decode 与缩放算法加速实践
观熵
影像技术全景图谱:架构调优与实战算法影像Camera
大图处理优化:低分加载、LazyDecode与缩放算法加速实践关键词:大图加载优化、LazyDecode、Region解码、缩放算法、Bitmap分块、滑动加载、内存控制、图像性能优化摘要:在相册、图片浏览器、拍摄预览和编辑器中,用户经常会处理分辨率高达上千万像素的照片(如48MP、64MP、RAW文件等),这类“大图”在加载、缩放、平移过程中容易造成内存抖动、页面卡顿甚至OOM崩溃。本篇文章将围
- 194、Django Channels实战:构建实时WebSocket应用
多多的编程笔记
djangowebsocketsqlite
DjangoChannels:实现WebSocket与实时通信本文将向您介绍Python开发框架Django中的一个重要组件——DjangoChannels,它使得在Django中实现WebSocket通信变得轻而易举。通过阅读本文,您将了解WebSocket的概念、DjangoChannels的工作原理以及如何在实际项目中使用它来实现实时通信。1.WebSocket:实现快速双向通信在介绍Dja
- springcloud feign调用get请求变成了post请求解决
只想要搞钱
springcloudjavaspring
1.feign调用get请求,feignService定义的get请求的参数是一个对象,如下图,调用另一个服务时,提示405,变成了post请求@GetMapping("/trainContact/queryContactForCurrentUser")Result>queryContactForCurrentUser(TrainContactPageDTOpageDTO);2.解决,对象前加一个
- QML Property属性语法
Little-Hu
QML数据库开发语言QML
QML作为Qt框架中的声明式UI语言,其property属性是构建动态用户界面的核心要素。property不仅是存储数据的容器,更是实现数据绑定、组件通信和状态管理的基石。本文将全面剖析QML中property属性的语法特性、使用场景和最佳实践,帮助开发者深入理解并高效运用这一重要机制。一、Property属性基础1.属性定义与声明在QML中,property属性用于存储对象的状态信息,其基本声明
- Osip源代码框架13--Call创建流程
八月的雨季997
osip源代码框架分析网络linux服务器网络协议c++
文章目录Call创建流程eXosip_call_build_initial_invite的流程参数合法性校验(阶段A)基础请求初始化(阶段B)Dialog外请求构造(阶段C)INVITE专属字段填充(阶段D)协议合规性检查(阶段E)Dialog内外请求的核心差异eXosip_call_send_initial_invite流程初始化呼叫流程创建客户端事务构建SIP请求事件驱动处理线程协同机制SIP
- feign调用get请求的接口时,出现“Request method ‘POST‘ not supported“
皮皮小澜孩
java开发语言feign
上面是错误的写法下面是正确的写法其实就是在feign接口的参数中加了个@SpringQueryMap注解@SpringQueryMap是微服务之间调用,使用openfeign通过GET请求方式来处理通过实体类来传参情况的注解。注意:被@SpringQueryMap注解的对象只能有一个如果需要传递多个对象,可以使用map传参,并且多个对象中不能出现相同的属性名,否则会覆盖
- 给无公网访问的NAS设备带来的福音(内网穿透,异地组网)
会飞的鱼儿~
NASdocker网络
目录一、节点小宝简介二、接入步骤及图解1.下载与安装2.配置节点小宝3.绑定设备4.远程访问与管理三、节点小宝的优势四、总结飞牛NAS安装节点小宝的详细指南飞牛NAS中,我们不断追求更高效、更便捷的数据管理和远程访问方式。今天,我将为大家详细介绍一款功能强大的网络工具——节点小宝,它不仅能够极大地提升我们对飞牛NAS的远程访问和管理能力,还能带来前所未有的灵活性和安全性。以下是详细的安装步骤。一、
- Feign解决Get请求自动转化成POST的问题
Java程序源
JavaGet请求自动转化成POSTFeign不支持请求方法“POST”get请求报错不支持post微信事件推送
记一次无厘头报错:Requestmethod‘POST’notsupported看起来很简单呐,就是不支持post请求嘛!!场景:对接研究三方接口(微信推送),三方接口请求方式是GET方式,之前参数接收也是顺利完美的,但是研究个性消息推送的时候出现了问题,设置了推广二维码,用户扫码的关注后,收不到推送消息,系统直接报“Requestmethod‘POST’notsupported”错误,所以问题点
- 触屏输入归一化:跨设备手感统一方案
你一身傲骨怎能输
FPS射击游戏高级技术专栏触屏输入归一化
文章摘要触屏输入归一化是为了解决不同设备屏幕尺寸、分辨率差异导致的操作不一致问题。核心流程包括:获取原始触点坐标和移动距离,结合设备DPI计算物理滑动距离,再通过归一化映射到统一标准(如固定参数或[0,1]区间)。实现时需注意DPI默认值、灵敏度调节和分辨率适配。其本质是将物理滑动距离转换为一致的游戏操作参数,确保跨设备操作公平性和手感统一。一、为什么要归一化?不同设备的屏幕尺寸、分辨率、DPI(
- MMORPG无loading条大世界技术揭秘
你一身傲骨怎能输
游戏开发技术专栏mmorpg
文章摘要现代MMORPG游戏实现无loading条大世界的核心技术包括:分区流式加载、异步多线程处理、LOD渐进式资源加载、智能内存管理等。主流方案将地图划分为可独立加载的区块,通过异步IO和优先级队列动态管理资源,结合预取机制和资源降级确保流畅体验。典型案例如《原神》《魔兽世界》等采用混合加载模式,核心场景预加载,外围区域动态加载。这些技术虽提升了游戏体验,但也对资源组织和内存管理提出了更高要求
- 微服务: Feign调用GET请求找不到请求体实体类
pingzhuyan
#SpringCloud微服务#异常总结分类javaSpringCloudfeignGet实体类
目录彩蛋:里面传递了token使用过滤器可以实现自动传递token无需传递,下一篇介绍1.方法一:尽可能使用post请求把GET改成POST,把方法上参数实体类加上@RequstBodY,这是最快速得方案2.方式二:依然使用get请求需要使用feign新加的请求参数->@SpringQueryMap注解2.1添加的位置:2.2写一个配置类注入feignBuilder方法(重点)2.3源码剖析Bea
- 为什么Linux系统安全没有病毒?原因是“它”
老男孩IT教育
linux系统安全网络
提到Linux系统,我们都会想到安全、自由度高、开源等特点,在Linux中病毒是很少甚至没有的,那么为什么Linux系统下病毒这么少呢?下面看老男孩教育小编给大家详细说明下,以下是详细的内容:Linux账号限制对一个二进制的Linux病毒,要感染可执行文件,这些可执行文件对启动这个病毒的用户一定要是可写的。而实际情况通常并不是这样的。实际情况通常是,程序被root拥有,用户通过无特权的帐号运行。而
- Open3D 点到面的ICP配准算法
AtlasCloud
python点云数据处理算法人工智能python矩阵numpy
目录一、算法原理1、算法概述2、点到平面ICP精配准3、参考文献二、主要函数三、代码实现四、结果展示1、初始位置2、配准结果一、算法原理1、算法概述 点到平面度量通常使用标准非线性最小二乘法来求解,例如Levenberg-Marquardt。点到平面ICP算法的每次迭代通常比点到点算法慢,但收敛速度明显更快。两个点云之间的相对旋转小于30°,在旋转矩阵中用θ替换sinθ,用1替换cosθ实现用线
- 学生选课系统(11457)
codercode2022
visualstudiocodespringboot开发语言matlabjavalaravelobjective-c
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦一、项目演示项目演示视频二、资料介绍完整源代码(前后端源代码+SQL脚本)配套文档(LW+PPT+开题报告)远程调试控屏包运行三、技术介绍Java语言SSM框架SpringBoot框架Vue框架JSP页面Mysql数据库IDEA/Eclipse开发有需要的同学,源代码和配套文档领取,加文章最下方的名片哦!
- 测试高频常见面试场景题汇总【持续更新版】
潮_
我的学习记录测试场景题测试场景题测试思维功能测试
测试场景题剪映贴纸功能1.功能测试2.性能测试3.安全测试4.兼容性测试5.用户体验测试6.异常处理测试登陆功能1.功能测试2.性能测试3.安全测试4.兼容性测试5.用户体验测试6.异常处理测试好的!针对登录功能的测试用例,我们需要覆盖以下方面:功能测试:验证登录功能是否正常工作。性能测试:测试登录功能的响应时间和负载能力。安全测试:验证登录功能的安全性,防止常见的安全漏洞。兼容性测试:测试登录功
- CSS像素:从物理屏幕到网页设计的“像素哲学”
CSS像素:从物理屏幕到网页设计的“像素哲学”在网页开发中,“像素”这个词似乎无处不在。我们写代码时设置width:100px;,设计师交来UI稿标注“750px宽度”,但你是否想过:这个“像素”到底是什么?为什么同一段CSS代码在不同设备上显示的效果却千差万别?今天,我们就来聊聊CSS像素背后的“像素哲学”。一、像素的三重身份:物理、逻辑与抽象1.物理像素(PhysicalPixel)物理像素是
- 为什么设计师的UI稿通常是2倍或3倍尺寸?
为什么设计师的UI稿通常是2倍或3倍尺寸?在网页和移动端开发中,设计师常常会交付2倍(@2x)或3倍(@3x)尺寸的设计稿。这种做法看似简单,背后却蕴含着设备显示原理与用户体验的深刻逻辑。今天,我们就来拆解这一“倍数设计”的奥秘。一、物理像素与逻辑像素:从“看得到”到“看得清”1.物理像素:屏幕的“最小颗粒”物理像素是屏幕硬件的最小显示单元。例如,iPhone6的分辨率是375×667像素,意味着
- 解析大数据领域结构化数据的管理模式
大数据洞察
大数据ai
解码结构化数据:大数据时代的高效管理模式与实践指南关键词结构化数据、大数据管理、数据建模、分布式数据库、数据仓库、数据治理、性能优化摘要在大数据的洪流中,结构化数据犹如隐藏在波涛之下的磐石,虽然不如非结构化数据那般引人注目,却是企业决策的基石。本文深入剖析了大数据环境下结构化数据的管理模式,从传统关系型数据库到现代分布式系统,从数据建模到存储架构,全面解读了结构化数据管理的核心技术与实践方法。通过
- Django Channels WebSocket实时通信实战:从聊天功能到消息推送
引言在Web开发中,实时通信功能(如在线聊天、实时通知、数据推送)已成为许多应用的核心需求。传统的HTTP协议由于其请求-响应模式的限制,无法高效实现实时通信。WebSocket作为一种全双工通信协议,为实时Web应用提供了理想的解决方案。本文将详细介绍如何使用DjangoChannels构建WebSocket应用,实现实时聊天和后端主动消息推送功能。一、技术背景1.1DjangoChannels
- C++基础复习笔记
xuwzen
C++c++笔记
一、数组定义在C++中,数组初始化有多种方式,以下是常见的几种方法:默认初始化数组元素未显式初始化时,内置类型(如int、float)的元素值未定义(垃圾值),类类型调用默认构造函数。intarr1[5];//元素值未定义聚合初始化(列表初始化)使用花括号{}直接初始化所有元素。若列表元素少于数组长度,剩余元素默认初始化(内置类型为0)。intarr2[3]={1,2,3};//完全初始化inta
- 【大厂机试题+多种解法+算法可视化笔记】欢乐的周末
xuwzen
编码训练算法
题目小华和小为是很要好的朋友,他们约定周末一起吃饭。通过手机交流,他们在地图上选择了多个聚餐地点(由于自然地形等原因,部分聚餐地点不可达),求小华和小为都能到达的聚餐地点有多少个?输入描述第一行输入m和n,m代表地图的长度,n代表地图的宽度。第二行开始具体输入地图信息,地图信息包含:0为通畅的道路1为障碍物(且仅1为障碍物)2为小华或者小为,地图中必定有且仅有2个(非障碍物)3为被选中的聚餐地点(
- Hadoop(一)
朱辉辉33
hadooplinux
今天在诺基亚第一天开始培训大数据,因为之前没接触过Linux,所以这次一起学了,任务量还是蛮大的。
首先下载安装了Xshell软件,然后公司给了账号密码连接上了河南郑州那边的服务器,接下来开始按照给的资料学习,全英文的,头也不讲解,说锻炼我们的学习能力,然后就开始跌跌撞撞的自学。这里写部分已经运行成功的代码吧.
在hdfs下,运行hadoop fs -mkdir /u
- maven An error occurred while filtering resources
blackproof
maven报错
转:http://stackoverflow.com/questions/18145774/eclipse-an-error-occurred-while-filtering-resources
maven报错:
maven An error occurred while filtering resources
Maven -> Update Proje
- jdk常用故障排查命令
daysinsun
jvm
linux下常见定位命令:
1、jps 输出Java进程
-q 只输出进程ID的名称,省略主类的名称;
-m 输出进程启动时传递给main函数的参数;
&nb
- java 位移运算与乘法运算
周凡杨
java位移运算乘法
对于 JAVA 编程中,适当的采用位移运算,会减少代码的运行时间,提高项目的运行效率。这个可以从一道面试题说起:
问题:
用最有效率的方法算出2 乘以8 等於几?”
答案:2 << 3
由此就引发了我的思考,为什么位移运算会比乘法运算更快呢?其实简单的想想,计算机的内存是用由 0 和 1 组成的二
- java中的枚举(enmu)
g21121
java
从jdk1.5开始,java增加了enum(枚举)这个类型,但是大家在平时运用中还是比较少用到枚举的,而且很多人和我一样对枚举一知半解,下面就跟大家一起学习下enmu枚举。先看一个最简单的枚举类型,一个返回类型的枚举:
public enum ResultType {
/**
* 成功
*/
SUCCESS,
/**
* 失败
*/
FAIL,
- MQ初级学习
510888780
activemq
1.下载ActiveMQ
去官方网站下载:http://activemq.apache.org/
2.运行ActiveMQ
解压缩apache-activemq-5.9.0-bin.zip到C盘,然后双击apache-activemq-5.9.0-\bin\activemq-admin.bat运行ActiveMQ程序。
启动ActiveMQ以后,登陆:http://localhos
- Spring_Transactional_Propagation
布衣凌宇
springtransactional
//事务传播属性
@Transactional(propagation=Propagation.REQUIRED)//如果有事务,那么加入事务,没有的话新创建一个
@Transactional(propagation=Propagation.NOT_SUPPORTED)//这个方法不开启事务
@Transactional(propagation=Propagation.REQUIREDS_N
- 我的spring学习笔记12-idref与ref的区别
aijuans
spring
idref用来将容器内其他bean的id传给<constructor-arg>/<property>元素,同时提供错误验证功能。例如:
<bean id ="theTargetBean" class="..." />
<bean id ="theClientBean" class=&quo
- Jqplot之折线图
antlove
jsjqueryWebtimeseriesjqplot
timeseriesChart.html
<script type="text/javascript" src="jslib/jquery.min.js"></script>
<script type="text/javascript" src="jslib/excanvas.min.js&
- JDBC中事务处理应用
百合不是茶
javaJDBC编程事务控制语句
解释事务的概念; 事务控制是sql语句中的核心之一;事务控制的作用就是保证数据的正常执行与异常之后可以恢复
事务常用命令:
Commit提交
- [转]ConcurrentHashMap Collections.synchronizedMap和Hashtable讨论
bijian1013
java多线程线程安全HashMap
在Java类库中出现的第一个关联的集合类是Hashtable,它是JDK1.0的一部分。 Hashtable提供了一种易于使用的、线程安全的、关联的map功能,这当然也是方便的。然而,线程安全性是凭代价换来的――Hashtable的所有方法都是同步的。此时,无竞争的同步会导致可观的性能代价。Hashtable的后继者HashMap是作为JDK1.2中的集合框架的一部分出现的,它通过提供一个不同步的
- ng-if与ng-show、ng-hide指令的区别和注意事项
bijian1013
JavaScriptAngularJS
angularJS中的ng-show、ng-hide、ng-if指令都可以用来控制dom元素的显示或隐藏。ng-show和ng-hide根据所给表达式的值来显示或隐藏HTML元素。当赋值给ng-show指令的值为false时元素会被隐藏,值为true时元素会显示。ng-hide功能类似,使用方式相反。元素的显示或
- 【持久化框架MyBatis3七】MyBatis3定义typeHandler
bit1129
TypeHandler
什么是typeHandler?
typeHandler用于将某个类型的数据映射到表的某一列上,以完成MyBatis列跟某个属性的映射
内置typeHandler
MyBatis内置了很多typeHandler,这写typeHandler通过org.apache.ibatis.type.TypeHandlerRegistry进行注册,比如对于日期型数据的typeHandler,
- 上传下载文件rz,sz命令
bitcarter
linux命令rz
刚开始使用rz上传和sz下载命令:
因为我们是通过secureCRT终端工具进行使用的所以会有上传下载这样的需求:
我遇到的问题:
sz下载A文件10M左右,没有问题
但是将这个文件A再传到另一天服务器上时就出现传不上去,甚至出现乱码,死掉现象,具体问题
解决方法:
上传命令改为;rz -ybe
下载命令改为:sz -be filename
如果还是有问题:
那就是文
- 通过ngx-lua来统计nginx上的虚拟主机性能数据
ronin47
ngx-lua 统计 解禁ip
介绍
以前我们为nginx做统计,都是通过对日志的分析来完成.比较麻烦,现在基于ngx_lua插件,开发了实时统计站点状态的脚本,解放生产力.项目主页: https://github.com/skyeydemon/ngx-lua-stats 功能
支持分不同虚拟主机统计, 同一个虚拟主机下可以分不同的location统计.
可以统计与query-times request-time
- java-68-把数组排成最小的数。一个正整数数组,将它们连接起来排成一个数,输出能排出的所有数字中最小的。例如输入数组{32, 321},则输出32132
bylijinnan
java
import java.util.Arrays;
import java.util.Comparator;
public class MinNumFromIntArray {
/**
* Q68输入一个正整数数组,将它们连接起来排成一个数,输出能排出的所有数字中最小的一个。
* 例如输入数组{32, 321},则输出这两个能排成的最小数字32132。请给出解决问题
- Oracle基本操作
ccii
Oracle SQL总结Oracle SQL语法Oracle基本操作Oracle SQL
一、表操作
1. 常用数据类型
NUMBER(p,s):可变长度的数字。p表示整数加小数的最大位数,s为最大小数位数。支持最大精度为38位
NVARCHAR2(size):变长字符串,最大长度为4000字节(以字符数为单位)
VARCHAR2(size):变长字符串,最大长度为4000字节(以字节数为单位)
CHAR(size):定长字符串,最大长度为2000字节,最小为1字节,默认
- [强人工智能]实现强人工智能的路线图
comsci
人工智能
1:创建一个用于记录拓扑网络连接的矩阵数据表
2:自动构造或者人工复制一个包含10万个连接(1000*1000)的流程图
3:将这个流程图导入到矩阵数据表中
4:在矩阵的每个有意义的节点中嵌入一段简单的
- 给Tomcat,Apache配置gzip压缩(HTTP压缩)功能
cwqcwqmax9
apache
背景:
HTTP 压缩可以大大提高浏览网站的速度,它的原理是,在客户端请求网页后,从服务器端将网页文件压缩,再下载到客户端,由客户端的浏览器负责解压缩并浏览。相对于普通的浏览过程HTML ,CSS,Javascript , Text ,它可以节省40%左右的流量。更为重要的是,它可以对动态生成的,包括CGI、PHP , JSP , ASP , Servlet,SHTML等输出的网页也能进行压缩,
- SpringMVC and Struts2
dashuaifu
struts2springMVC
SpringMVC VS Struts2
1:
spring3开发效率高于struts
2:
spring3 mvc可以认为已经100%零配置
3:
struts2是类级别的拦截, 一个类对应一个request上下文,
springmvc是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应
所以说从架构本身上 spring3 mvc就容易实现r
- windows常用命令行命令
dcj3sjt126com
windowscmdcommand
在windows系统中,点击开始-运行,可以直接输入命令行,快速打开一些原本需要多次点击图标才能打开的界面,如常用的输入cmd打开dos命令行,输入taskmgr打开任务管理器。此处列出了网上搜集到的一些常用命令。winver 检查windows版本 wmimgmt.msc 打开windows管理体系结构(wmi) wupdmgr windows更新程序 wscrip
- 再看知名应用背后的第三方开源项目
dcj3sjt126com
ios
知名应用程序的设计和技术一直都是开发者需要学习的,同样这些应用所使用的开源框架也是不可忽视的一部分。此前《
iOS第三方开源库的吐槽和备忘》中作者ibireme列举了国内多款知名应用所使用的开源框架,并对其中一些框架进行了分析,同样国外开发者
@iOSCowboy也在博客中给我们列出了国外多款知名应用使用的开源框架。另外txx's blog中详细介绍了
Facebook Paper使用的第三
- Objective-c单例模式的正确写法
jsntghf
单例iosiPhone
一般情况下,可能我们写的单例模式是这样的:
#import <Foundation/Foundation.h>
@interface Downloader : NSObject
+ (instancetype)sharedDownloader;
@end
#import "Downloader.h"
@implementation
- jquery easyui datagrid 加载成功,选中某一行
hae
jqueryeasyuidatagrid数据加载
1.首先你需要设置datagrid的onLoadSuccess
$(
'#dg'
).datagrid({onLoadSuccess :
function
(data){
$(
'#dg'
).datagrid(
'selectRow'
,3);
}});
2.onL
- jQuery用户数字打分评价效果
ini
JavaScripthtmljqueryWebcss
效果体验:http://hovertree.com/texiao/jquery/5.htmHTML文件代码:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>jQuery用户数字打分评分代码 - HoverTree</
- mybatis的paramType
kerryg
DAOsql
MyBatis传多个参数:
1、采用#{0},#{1}获得参数:
Dao层函数方法:
public User selectUser(String name,String area);
对应的Mapper.xml
<select id="selectUser" result
- centos 7安装mysql5.5
MrLee23
centos
首先centos7 已经不支持mysql,因为收费了你懂得,所以内部集成了mariadb,而安装mysql的话会和mariadb的文件冲突,所以需要先卸载掉mariadb,以下为卸载mariadb,安装mysql的步骤。
#列出所有被安装的rpm package rpm -qa | grep mariadb
#卸载
rpm -e mariadb-libs-5.
- 利用thrift来实现消息群发
qifeifei
thrift
Thrift项目一般用来做内部项目接偶用的,还有能跨不同语言的功能,非常方便,一般前端系统和后台server线上都是3个节点,然后前端通过获取client来访问后台server,那么如果是多太server,就是有一个负载均衡的方法,然后最后访问其中一个节点。那么换个思路,能不能发送给所有节点的server呢,如果能就
- 实现一个sizeof获取Java对象大小
teasp
javaHotSpot内存对象大小sizeof
由于Java的设计者不想让程序员管理和了解内存的使用,我们想要知道一个对象在内存中的大小变得比较困难了。本文提供了可以获取对象的大小的方法,但是由于各个虚拟机在内存使用上可能存在不同,因此该方法不能在各虚拟机上都适用,而是仅在hotspot 32位虚拟机上,或者其它内存管理方式与hotspot 32位虚拟机相同的虚拟机上 适用。
- SVN错误及处理
xiangqian0505
SVN提交文件时服务器强行关闭
在SVN服务控制台打开资源库“SVN无法读取current” ---摘自网络 写道 SVN无法读取current修复方法 Can't read file : End of file found
文件:repository/db/txn_current、repository/db/current
其中current记录当前最新版本号,txn_current记录版本库中版本
 图:Vertica用于构建全局唯一文件名的存储标识符格式
图:Vertica用于构建全局唯一文件名的存储标识符格式
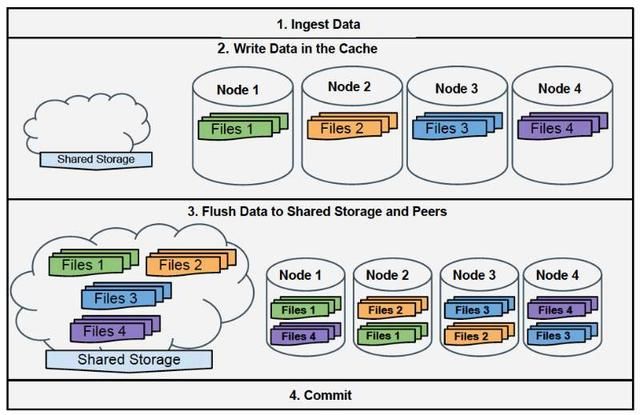 图:数据加载工作流程。 提交之前文件被对等节点缓存并已保存到共享存储标题
图:数据加载工作流程。 提交之前文件被对等节点缓存并已保存到共享存储标题
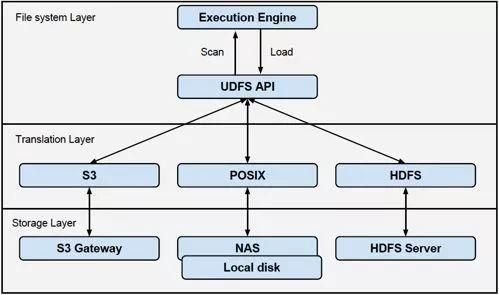 图:UDFS API示意图标题
图:UDFS API示意图标题