【源码分析】HashMap的原理及常见面试题
参考文献:
- HashMap实现原理及源码分析
- CS-Notes Java容器
- HashMap 相关面试题及其解答
- Java 8系列之重新认识HashMap
- 美团面试题:Hashmap的结构,1.7和1.8有哪些区别,史上最深入的分析
- 既然红黑树那么好,为啥hashmap不直接采用红黑树,而是当大于8个的时候才转换红黑树?
- HashMap:为什么容量总是为2的次幂
- jdk1.7HashMap链表头插法导致的死循环
- jdk 1.7 HashMap源码
前言
HashMap在Java面试中考察频率很高,涉及了哈希表、链表、红黑树、多线程等知识点。
本文主要内容是HashMap的原理及常见面试题,主要是基于jdk 1.7的源码,并穿插总结说明了和jdk1.8的主要区别;原理篇幅较大请耐心细看,常见面试题来源于本人面试经历和网络,面试题总结了常见面试题、HasMap的要点、ConCurrentHashMap的要点。
本文内容来自于 个人对HashMap源码的理解、参考文献中相关网络博客的要点总结及个人理解,由于本人能力有限,可能会有理解错误之处,望不吝指教;如有侵权,通知则删!
1 HashMap数据结构
HashMap的主干是一个Entry数组;Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
//HashMap的主干数组,是一个Entry数组;初始值为空数组{};主干数组table的长度一定是2的次幂,至于为什么这么做,后面会有详细分析。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry是HashMap中的一个静态内部类,代码如下,jdk1.8就是改了个类名(改为Node):
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的指针(引用),单链表结构
int hash;//hash(key),不是hashcode(key);存储在Entry,避免重复计算;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
//...
}
HashMap的整体数据结构如下:
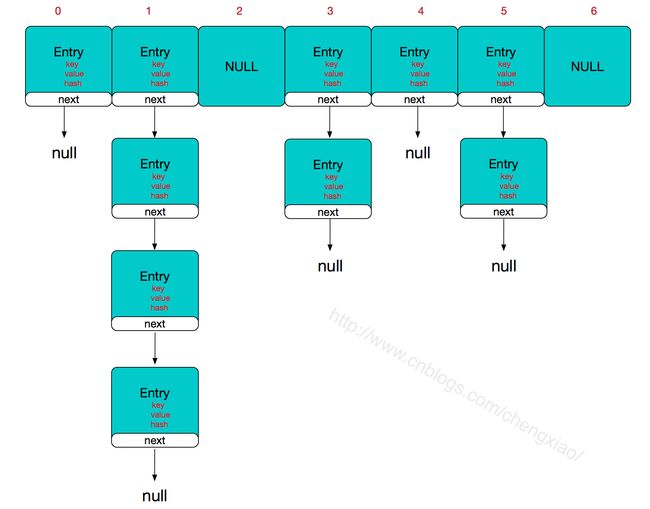
如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加操作的时间复杂度为O(1);如果定位到的数组包含链表,添加查找操作时间复杂度为O(n);从性能考虑,HashMap中的链表长度越短,性能才会越好。
2 主要参数
| 参数 | 含义 |
|---|---|
| capacity | table的容量大小,默认为 16; 可由用户在构造器设置,但调整后最终capacity 一定是2 的次幂;最大值是230 |
| size | Entry(键值对)个数; |
| threshold | size 的临界值,当 size >= threshold 就必须进行扩容; |
| loadFactor | 装载因子,默认值0.75,table 能够使用的比例;threshold = capacity * loadFactor; 可由用户在构造器设置; |
- loadFactor装载因子是个常量,所以loadFactor在HashMap实例化后固定不变,要么是0.75,要么是用户输入值;
//capacity默认值16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//capacity最大值2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//loadFactor默认值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//主干数组
transient Entry[] table;
//entry个数
transient int size;
//size 的临界值,当size >= threshold 就必须进行扩容;
int threshold;
//装载因子,table 能够使用的比例;threshold = capacity * loadFactor;可由用户在构造器设置;因为是个常量,所以loadFactor在HashMap实例化后固定不变;
final float loadFactor;
//HashMap结构变化(put或remove)数,保证HashMap在序列化或迭代时数据一致性;当一个线程在对HashMap进行序列化或迭代时,如果modCount变化了,说明其他线程修改了HashMap结构,会抛出一个ConcurrentModificationException异常;
transient int modCount;
3 源码分析
3.1 构造函数
HashMap有4个构造器,其他构造器如果用户没有传入initialCapacity 和loadFactor这两个参数,会使用默认值;initialCapacity默认为16,loadFactory默认为0.75;我们看下其中一个:
public HashMap(int initialCapacity, float loadFactor) {
//此处对用户设置容量initialCapacity进行校验
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//此处对loadFactor进行校验
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;//值为默认capcity或用户输入capcity,后面确定capcity为2的次幂会修改threshold值为threshold = capacity * loadFactor;
init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现
}
对传输参数进行校验,然后初始化loadFactor和threshold;从上面这段代码我们可以看出,在常规构造器中,没有为数组table分配内存空间(入参为指定Map的构造器例外),而是在执行put操作的时候才真正分配内存;
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
这个构造器应该是大家使用最多的构造器,它将默认capcity和loadFactor传入另外一个构造器;
3.2 put方法
put方法用于往HashMap中添加一个键值对;
public V put(K key, V value) {
//HashMap初始化后添加第一个元素,此时table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为用户输入capcity
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置index
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//对于位置为index的那条冲突链
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);//添加一个entry
return null;
}
3.3 保证capcity为2的次幂
private void inflateTable(int toSize) {
//此时toSize是threshold
int capacity = roundUpToPowerOf2(toSize);//保证capacity初值一定是2的次幂
//此处为threshold初始化,取capacity*loadFactor和MAXIMUM_CAPACITY+1的最小值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];//分配内存
initHashSeedAsNeeded(capacity);
}
此方法为table分配内存;并且初始化capacity为2的次幂,初始化threshold为capacity*loadFactor,值得一提的是loadFactor在构造器中以初始化为默认值或者用户输入值;
private static int roundUpToPowerOf2(int number) {
//此时number是threshold
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
假设之前使用的是key-value两个参数的构造器,执行到这个方法;此时number是threshold ,要么是默认capcity16,要么是用户输入capcity;roundUpToPowerOf2中的这段处理使得数组长度capcity一定为2的次幂;
Integer.highestOneBit是用来获取"最高位非0位保留,其他位全为0"所代表的数值;通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于number的第一个二的次幂;比如number=13,则capacity=16;number=16,capacity=16;number=17,capacity=32.
所以roundUpToPowerOf2(number)方法保证了capcity初值一定是2的次幂;capcity为大于或等于number的第一个二的次幂;
roundUpToPowerOf2(number)方法加上2倍扩容方式保证了capcity一定是2的次幂;
到现在为止三个关键参数threshold、capacity、loadFactor已初始化完成;table也完成了初始化;
3.4 确定桶下标bucketIndex
(1)当添加的元素key为空时
HashMap是允许null键和null值的;当key为null时,新添加的元素插入到table[0]或者table[0]的冲突链上;
(2)当添加的元素key不为空时
//这个方法对key的hashcode做了进一步行计算来保证返回的hash(key)尽量分布均匀
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
这个方法对key的hashcode做了进一步行计算来保证返回的hash(key)尽量分布均匀;这个hash(key)在后面会保存到entry.hash中去;
//返回table数组下标(桶下标)
static int indexFor(int h, int length) {
return h & (length-1);
}
因为h&(length-1)一定小于length,保证了获取的index一定在数组下标范围内;举个例子,默认容量16,length-1=15,h=18,转换成二进制计算为:
h 1 0 0 1 0
length-1 & 0 1 1 1 1
__________________
index 0 0 0 1 0 = 2
最终计算出index=2;有些版本在此处的计算下标会使用模%运算,也能保证index一定在数组下标范围内;不过对于计算机来说,位运算比模运算更快;
所以最终桶下标index(bucketIndex)是这么确定的:
e.hash = h = hash(key);//hash(key)是对key.hashcode()的进一步处理;保证均匀
index = h & (length-1) = h % length;//可证明,当n为2的次幂时,y&(n-1)=y%n;
所以我们在这知道了capcity为2的次幂的一个作用:计算桶下标index时,让模运算转为位运算,运算更快;
3.5 添加键值对过程
put方法用于往HashMap中添加一个键值对;
public V put(K key, V value) {
//HashMap初始化后添加第一个元素,此时table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为用户输入capcity
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置index
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//对于位置为index的那条冲突链
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
//验证e.hash == hash的目的是防止出现key equals为true但hashcode不等的情况(key的类复写了equals却没复写hashcode方法)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//哈希值和key都相等则覆盖,否则比较下一个结点
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);//插入结点
return null;
}
map.put(key,value)插入的过程:先查找后插入>(简化版)
- 先计算哈希值
hash(key),确定桶下标index;- 如果index处没有冲突链,说明没冲突,直接插入;
- 如果index处有冲突链,说明有冲突;接下来遍历这个冲突链,查找和待插入结点的key和哈希值都相等的结点;
- 查找成功,则用新value覆盖旧value,完成插入;
- 查找失败,插入到头部;
补充说明:
- 如果插入的是空键,插入到index为0的冲突链上,插入过程和上面一样;
- 插入结点过程中,如果遇到size >= threshold的情况,需要扩容;
- 一般情况(同时复写/不复写key类的equals,hashcode方法),key相等(equals),哈希值相等;
index = hash % length = hash & (length-1);- 查询或插入过程中,冲突指的是index冲突(即不同的key,相同的index);index冲突一般有两种情况:①不同的key,相同的hash,相同的index;(has(key)函数导致的冲突)②不同的key,不同的hash,相同的index;(
index = hash % length函数导致的冲突); - 哈希值计算公式和桶下标计算公式
哈希值计算:e.hash = h = hash(key);//hash(key)是对key.hashcode()的进一步处理,来保证均匀;
桶下标计算:index = h & (lenth-1) = h % length;//可证明,当n为2的次幂时,y&(n-1)=y%n;
- java 1.7 插入结点是头插法,java 1.8 是尾插法,java1.8还有往红黑树上插入结点的过程;
- put和remove都是先查找后操作的过程,查找键和哈希值都相等(key.equals(e.key)&&hash==e.hash)的结点;
//往HashMap里添加结点
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容
resize(2 * table.length);//扩容为原容量的两倍
hash = (null != key) ? hash(key) : 0;//我觉得这行代码可以不要,因为扩容前后hash(key)是不变的
bucketIndex = indexFor(hash, table.length);//table.length更新为原来2倍,重新计算index
}
createEntry(hash, key, value, bucketIndex);
}
//头插法往当前index冲突链插入元素
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];//当前冲突链的老头结点
table[bucketIndex] = new Entry<>(hash, key, value, e);//新头结点,next指向老头结点
size++;
}
3.6 扩容
3.6.1 扩容相关函数
//扩容
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {//如果达到最大容量就放弃扩容
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];//为新表分配内存,空间消耗
transfer(newTable, initHashSeedAsNeeded(newCapacity));//将旧表上的所有结点内容复制到新表上,时间消耗较大
table = newTable;//更新为新表
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);//更新threshold
}
这个方法进行了扩容(数组capcity为原来的2倍)操作,并且将旧表上的所有结点内容复制到新表上;有较大的(空间消耗和时间)消耗,所以要尽量减少扩容次数;
//复制表
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {//是否重新计算哈希值,为了提高效率,一般为fasle
e.hash = null == e.key ? 0 : hash(e.key);
}
//新桶下标index要么不变,要么加oldCapcity
int i = indexFor(e.hash, newCapacity);//扩容前后,第一个参数h没变,第二个参数分别是oldCapacity,newCapacity;
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这个方法完成了将旧表上的所有结点内容复制到新表上的过程,建立新表用的是头插法(java 1.8用的是尾插法);这个过程非常耗时,时间复杂度是O(size);
3.6.2 扩容后桶下标index计算
int i = indexFor(e.hash, newCapacity);
先看transfer方法中的这行代码,它是用来计算每个结点在新表上的桶下标index;不论是否重新计算哈希值,计算新旧index传入的第一个参数都是相同的,均为hash(key);第二个参数,扩容前后传入的分别是oldCapcity、newCpacity,newCpacity=2oldCapcity;计算桶下标的公式是index = h & (length-1);现设h=hash(key) = 21 (or 5) , oldLength=table.length=oldCapcity=16 , newLength=table.length=newCapcity=32;现在看看是如何计算的:
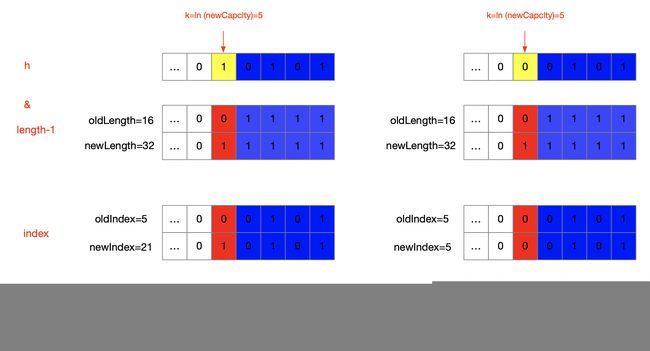
我们再观察,当table的容量是2的次幂时,计算index时,length-1的低位均为1,又因为哈希值hash(key)之前经过一些处理本来就比较均匀,所以就能保证index也比较均匀;这是capcity为2的次幂的第二个好处;
3.6.3 扩容后冲突链的变化
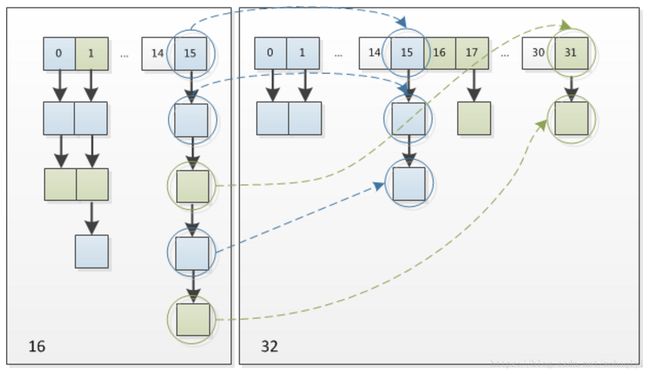
同一条冲突链上可能有的结点hash(key)的第k(5)位是0,有的是1。在扩容时,会把旧table上的所有节点复制到新table上,采用头插法生成新表的冲突链。k为0的结点扩容后index不变,在新表相同的index上插入;k为1的结点扩容后index加16,在新表新ndex上插入。这样一条冲突链就裂变成两条链了。如上图所示,一条链变成了两条链。(上图是java1.8尾插法)
同一条冲突链上也有可能所有的结点的第k位都是0,这样一条链在在扩容后只生成一条链并且index不变。
同一条冲突链上也有可能所有的结点的第k位都是1,这样一条链在在扩容后只生成一条链但index加16。
由于java1.7中HashMap冲突链插入结点使用的是头插法,新链结点顺序相对于旧链逆置。如果是java1.8 改为使用尾插法,所以新链结点顺序不变。
扩容后某条冲突链的变化有三种可能:
- 一条链,index不变;
- 一条链,index加16;
- 两条链,一条index不变,一条index加16;
从这儿也说明了:HashMap使用put输入多个元素然后遍历输出,元素输入输出次序可能会发生变化(包括jdk1.8);
3.7 capcity为2的次幂的好处
capcity为2的次幂的好处主要体现在计算桶下标index时,我们回顾一下是怎么计算key的哈希值hash(key)和桶下标index的:
哈希值计算:e.hash = h = hash(key);//hash(key)是对key.hashcode()的进一步处理,来保证均匀;
桶下标计算:index = h & (lenth-1) = h % length;//可证明,当n为2的次幂时,y&(n-1)=y%n;
我们都知道,计算机进行位运算比模运算要快得多;在计算index时,我们可以用位运算h & (len-1)替代模运算h % len以提高运算效率,但是这两个结果相等的前提是length(=capcity)为2的次幂;所以capcity为2的次幂来保证模运算转换为位运算,这样计算更快,这是第一个好处。
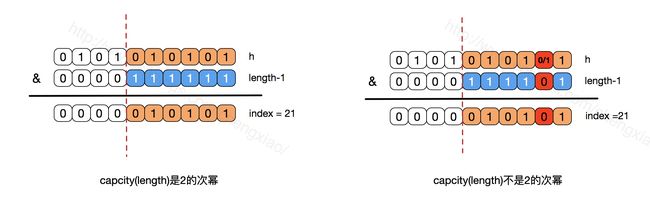
我们观察,当table的容量是2的次幂时,计算index时,length-1的低位均为1,又因为哈希值hash(key)之前经过一些处理本来就比较均匀,所以就能保证index也比较均匀;这是capcity为2的次幂的第二个好处;
我们看到,当table的容量是2的次幂时,length-1为0...01…1形式;上面的&运算,h的高位不会对结果产生影响,所以我们只关注低位;因为legth-1低位全部为1,所以计算结果index的高位部分为0,低位部分和h的低位部分一样。因此index为21对应的h低位只有一种组合,从而减少了index的冲突。当table的容量不是2的次幂时,length-1就不是0...01…1形式了,假设为0000111101;无论h的低位起第二位是0还是1,index的结果都是21.因此index为21对应的h低位有两种组合,产生了index冲突。虽然说h不同的高位相同的低位部分,会得到相同index值而产生冲突,但这种冲突出现的概率后者是前者的两倍。减少index冲突是capcity为2的次幂的第三个好处;
capcity为2的次幂的好处:计算桶下标index时,
- 模运算转位运算,更快;
- index分布均匀;
- 减少index冲突;
3.8 查询结点
3.8.1 get方法
map.ge(key)方法用于通过key查询value;
//用于通过key查询value;
public V get(Object key) {
//如果key为null,则直接去index为0的冲突链处去遍历即可
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
//用于通过key查询Entry对象
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//先计算key的哈希值
int hash = (key == null) ? 0 : hash(key);
//先确定index,再在指定冲突链遍历查询;遍历过程和put方法类似
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
3.8.2 get按键查询的过程
map.get(key)查找的过程:先确定index,后遍历冲突链,找键和哈希值都相等的结点(简化版)
- 先计算哈希值
hash(key),确定桶下标index; - 如果index处没有冲突链,查询失败,返回null;
- 如果index处有冲突链,接下来遍历这个冲突链,比较当前结点key和输入key以及它们的哈希值;
- 如果哈希值和key都相等,则查找成功,返回entry.value;
- 否则比较下一个结点,直到遍历找到了都相等的结点则查找成功;或直到当前结点e==null,则查找失败;
3.8.3 containsValue按值查询
public boolean containsValue(Object value) {
if (value == null)//如果是空值
return containsNullValue();
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)//遍历每一条链
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
map.containsValue(value)按值查询的过程很简单,从0号冲突链开始,遍历每一条冲突链;
3.9 remove删除结点
//删除指定key的结点并返回其value
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
//删除指定key的结点
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);//计算哈希值
int i = indexFor(hash, table.length);//计算桶下标index
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链
Entry<K,V> next = e.next;
Object k;
//查找key和hash都相等的结点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
//查找成功
modCount++;//hashmap结构发生变化
size--;
if (prev == e)//第一个结点就是要删除的结点
table[i] = next;
else
prev.next = next;//删除结点
e.recordRemoval(this);
return e;
}
prev = e;//先缓存前驱
e = next;
}
return e;
}
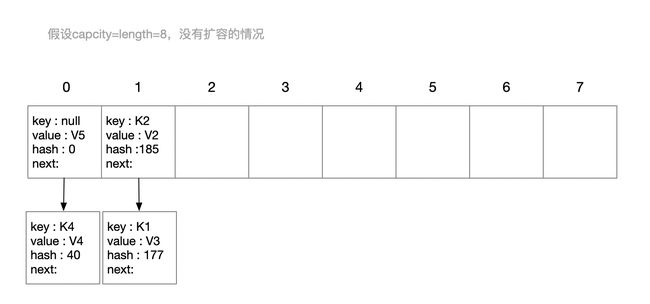
4 插入键值对和按键查询过程举例
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K1", "V3");
map.put("K4", "V4");
map.put("null", "V5");
System.out.println(map.get(K6));//null
System.out.println(map.get(K2));//V2
System.out.println(map.get(k7));//null
System.out.println(map.get(null));//V5
map.put(K,V)插入键值对:
- 新建一个 HashMap,默认大小为 8;
- 插入
- 插入
- 插入
- 插入
- 插入
get(key)按键查询value:
map.get(K6),先计算 K6 的 哈希值 为 36,桶下标为 36%8=4;index为4处是空链,查询失败;map.get(K2),先计算 K2 的 哈希值 为 185,桶下标为 185%8=1;遍历查询index为1的冲突链,第一个结点就查找成功;map.get(K7),先计算 K7 的 哈希值 为 25,桶下标为 25%8=1;遍历查询index为1的冲突链,直到e==null也没有找到key和哈希值都相等的结点;查询失败;map.get(null),键为空,直接去index为0的冲突链查询,第一个结点就查找成功;
这是map最后的结构图:
5 jdk 1.8的修改
| 变化 | jdk 1.7 | jdk 1.8 | why |
|---|---|---|---|
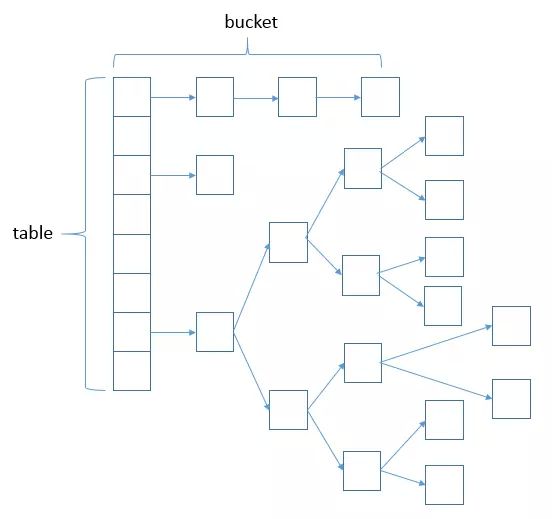
| 数据结构 | 数组+单链表 | 数组+单链表+红黑树 | 小于8,使用单链表,查询成本高,插入成本低;大于等于8,使用红黑树,查询成本低,插入成本高;(红黑树插入需要旋转,慢) |
| 单链表插入结点方式 | 头插法 | 尾插法 | 头插法缺点:在多线程情况下,扩容时,可能会产生循环链表,从而导致死循环;头插法优点:最近put可能一会就要get; |
| put时内部操作顺序 | 先扩容后插入 | 先插入后扩容 | ? |
| 扩容后新index的计算 | newIndex = hash & (newCapcity-1) |
newIndex = oldIndex + oldCapciyor newIndex = oldIndex |
1.8直接使用1.7的计算规律,更快 |
| 哈希运算次数 | 多 | 少 | 更快 |
- jdk 1.8 Hashmap结构:
6 HashMap常见面试题
(1) HashMap数据结构?
- 1.7 数组+单链表;
- 1.8 数组+单链表+红黑树(8);
(2) HashMap 的工作原理?
1.HashMap由数组+单链表构成,可以看成一个哈希表;HashMap主干是一个Entry数组,用于存储每个链表的头结点的引用;
2.map.put(key,value)插入的过程:先查找后插入(简化版)
- 先计算哈希值
hash(key),确定桶下标index;- 如果index处没有冲突链,说明没冲突,直接插入;
- 如果index处有冲突链,说明有冲突;接下来遍历这个冲突链,查找和待插入结点的key和哈希值都相等的结点;
- 查找成功,则用新value覆盖旧value,完成插入;
- 查找失败,插入到头部;
3.map.get(key)查找的过程:先确定index,后遍历冲突链,找键和哈希值都相等if(key.equals(e.key)&&hash==e.hash)的结点(简化版)
- 先计算哈希值
hash(key),确定桶下标index; - 如果index处没有冲突链,查询失败,返回null;
- 如果index处有冲突链,接下来遍历这个冲突链,比较当前结点key和输入key以及它们的哈希值;
- 如果哈希值和key都相等,则查找成功,返回entry.value;
- 否则比较下一个结点,直到遍历找到了都相等的结点则查找成功;或直到当前结点e==null,则查找失败;
(3) HashMap 是否允许null键或者null值,如何处理?
- HashMap允许空键和空值;
- 空键的key-value直接插入到0号链上;
(4) HashMap get(key)查询时比较的是什么?
- 表面上看,查询成功要求key相等;
- 本质上,查询成功要求哈希值相等且key equals 返true
if(key.equals(e.key)&&hash==e.hash);
(5) HashMap是否允许有重复数据?
- 一般情况,put时会覆盖同key元素,不存在同key结点;
- 允许存在多个同value结点;
(6) HashMap是有序的么?其对应的有序Map类是什么?
- HashMap是无序的:put输入顺序和遍历输出顺序可能不一致;
- LinkedHashMap有序:可以是插入顺序或者访问顺序(LRC顺序),由accessOrder属性控制
(7) 为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键?
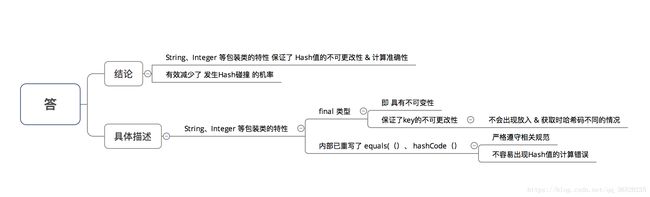
(8) HashMap 中的 key若 Object类型, 则需实现(复写)哪些方法?这些方法的作用是什么?
- hashcode方法:是定位的,存储位置;
- equals是定性的,比较两者是否相等;
(9) HashMap 中的哈希值hash(key)和桶下标index是如何计算的?
- 计算哈希值
h = hash(key):①key.hashcode(); ② 对key.hashcode()进行扰动处理:- jdk 1.7 :4次右移,5次异或;
- jdk 1.8 :1次右移,1次异或;
- 计算桶下标:
- jdk 1.7 :扩容前后一样
index = h & (length-1); - jdk 1.8 :扩容前和1.7一样,扩容后
newIndex = oldIndex + oldCapciyornewIndex = oldIndex;
- jdk 1.7 :扩容前后一样
(10) HashMap数组的容量为什么要求是2的次幂(作用、好处)?
计算桶下标index时,
- 模运算转位运算,更快;
- index分布均匀;
- 减少index冲突;
(11) 脱离HashMap说说哈希表的原理?
- 定义:根据Key直接访问的数据结构,建立了关键字和地址之间的一种映射关系;
- 哈希碰撞(冲突):不同的key,得到相同的哈希地址;哈希碰撞无法避免,只能减少碰撞;设计好的哈希函数减少碰撞,发生碰撞了要处理碰撞;
- 哈希函数:
Addr = Hash(key);常见的哈希函数:- 除留余数法:
Hash(key) = key % len; - 直接定址法:
Hash(key) = a*key+b; - 平方取中法:取关键字平方的中间几位作为哈希地址;
- 折叠法:将关键字分割成位数相同的几部分,然后取它们的叠加和;
- 数字分析法:选关键字数码分布较为均匀的若干位;
- 除留余数法:
- 处理冲突的方法:
- 开放定址法:Hi = (H(key)+di)%m ; H(key)表示发生冲突的哈希函数,m表长,Hi 表示冲突后第I次探测的地址,di表示增量序列,i(0,1,2,…,m-1);增量序列di的取法:
- 线性探测法:di = 0,1,2,…,m-1;
- 平方探测法:di = 02,12,-12,22,-22,…,k2,-k2; 其中k<=m/2;
- 再哈希法:di = H2(key);
- 伪随机序列法:di = 伪随机序列;
- 拉链法:数组+单链表,数组元素存储每个链表头结点的引用;
- HashMap使用的就是拉链法;ThradLocalMap使用的就是开放定址法;
- 开放定址法:Hi = (H(key)+di)%m ; H(key)表示发生冲突的哈希函数,m表长,Hi 表示冲突后第I次探测的地址,di表示增量序列,i(0,1,2,…,m-1);增量序列di的取法:
(12) HashTable的主要参数有哪些?它们的作用分别是什么
| 参数 | 含义 |
|---|---|
| capacity | table的容量大小,默认为 16; 可由用户在构造器设置,但调整后最终capacity 一定是2 的次幂;最大值是230 |
| size | Entry(键值对)个数; |
| threshold | size 的临界值,当 size >= threshold 就必须进行扩容; |
| loadFactor | 装载因子,默认值0.75,table 能够使用的比例;threshold = capacity * loadFactor; 可由用户在构造器设置; |
(13) 扩容过程 (jdk 1.7)?
- 在put过程中,如果size >= threshold,就需要扩容(2倍);
- 扩容调用resize方法,在resize中调用transfer方法将旧数组中的数据复制到新数组中去;
- 调用transfer方法复制数据时,对每个链表进行遍历,先计算当前结点新桶下标index,将当前结点按头插法插入到新表中;
- 最后更新 threshold;
(14) 扩容后冲突链的结构会有什么变化?
存在三种可能的变化:
- 一条链,index不变;
- 一条链,index加16;
- 两条链,一条index不变,一条index加16;
(15) 扩容过程有什么问题么?
从旧数组复制数据到新数组这个过程会遍历每个链表的每个结点,时间复杂度O(size)时间消耗较大;所以当HashMap数据量较大时,扩容会带来较大的性能损耗;在性能要求很高的地方,这种损失很可能很致命。
(16) jdk 1.8 对HashMap的修改有哪些?
见上文最后一节;
(17) HashMap的遍历方式有哪些?
//foreach map.keySet()方式
for (String key : map.keySet()){
System.out.println(key+" - "+map.get(key));
}
//foreach map.entrySet()方式
for (Map.Entry<String,Integer> entry : map.entrySet()){
System.out.println(entry.getKey()+" - "+entry.getValue());
}
//keySet的iterator方式
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key=iterator.next();
System.out.println(key+" - "+map.get(key));
}
//entrySet的iterator方式
Iterator<Map.Entry<String,Integer>> iterator2 = map.entrySet().iterator();
while (iterator2.hasNext()){
Map.Entry<String,Integer> entry = iterator2.next();
System.out.println(entry.getKey()+" - "+entry.getValue());
}
(18) HashMap & TreeMap & LinkedHashMap 使用场景?
一般情况下,使用最多的是 HashMap;
- HashMap:在 Map 中插入、删除和查询元素时;
- TreeMap:该类持有Compartor的引用,在需要排序的情景下使用;
- LinkedHashMap:在要求输出输入的顺序相同的情况下使用;
(19) ConcurrentHashMap JDK 1.7 VS JDK 1.8?
- JDK 1.7 :数据结构是数组+单链表;分段锁Segment 继承自ReentrantLock保证并发安全,每个Segment 维护若干个桶;锁粒度是Segment 对象;
- JDK 1.8 :数据结构是数组+单链表+红黑树;取消了Segment ,用Node + CAS + Synchronized(CAS失败后使用)来保证并发安全;锁粒度减小为Node对象;
(20) HashTable VS HashMap VS ConcurrentHashMap
| 指标 | HashTable | HashMap | ConcurrentHashMap |
|---|---|---|---|
| - | 遗弃类 | 常用类 | 并发工具类 |
| 数据结构 | 数组+单链表 | 数组+单链表(+1.8红黑树) | 1.7数组+Segment+单链表; 1.8数组+单链表+红黑树 |
| 线程安全 | 安全 | 不安全 | 安全 |
| 效率 | 低 | 高 | 最高 |
| 锁粒度 | 整个Map | - | 1.7是Segment; 1.8是Node |
| 线程安全实现 | synchronized同步方法,Map对象锁 | - | 1.7 Reentrant; 1.8 CAS+synchronized(前者失败) |
| 空键空值 | 都不允许 | 允许空键空值 | 都不允许 |
| 数组容量capcity | 默认数组容量为16 | 默认值为16,扩容为2capcity | 同HashMap |
| 哈希值 | 直接使用key.hashcode | hash(key)对key.hashcode进行了右移异或扰动处理 | 与HashMap类似 |
(21)HashMap为什么不是线程安全的?1.8后resize()不会出现循环链表为何仍然不是线程安全的?
HashMap不是线程安全本质原因是remove,put等方法压根没有使用同步手段;1.7resize()可能出现死循环只是线程不安全的最严重后果;