使用 declarative-crawler 爬取知乎美图 是笔者对 declarative-crawler 的具体实例讲解,从属于笔者的 程序猿的数据科学与机器学习实战手册。
本部分源代码参考这里,对于 declarative-crawler 的分层架构与设计理念可以参考笔者的前文 基于 Node.js 的声明式可监控爬虫网络初探。这里我们还是想以知乎简单的列表-详情页为例,讲解 declarative-crawler 的基本用法。首先我们来看下爬取的目标,譬如我们搜索美女或者其他主题,可以得到如下回答的列表页:
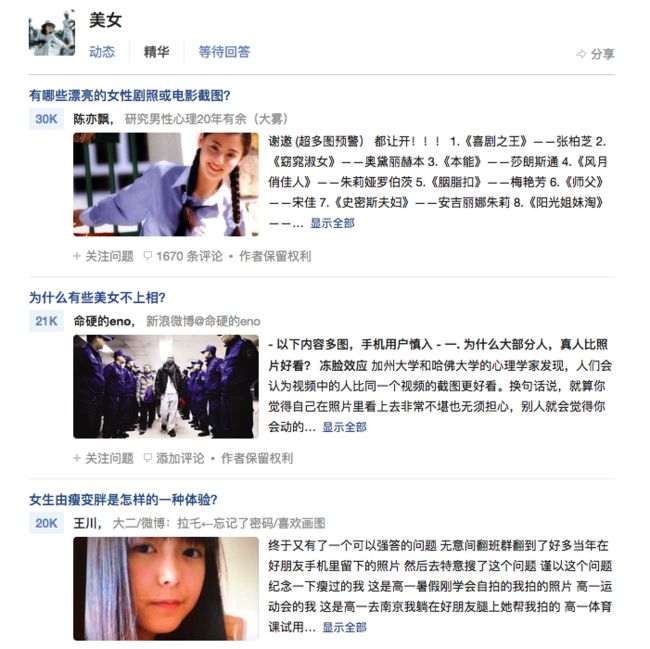
点击某个回答之后我们可以进入如下的回答详情页,而我们的目标就是将所有的图片保存到本地。

处理动态页面的蜘蛛设计
目前知乎是基于 React 构建的动态网络,换言之,我们不可以直接使用 fetch 这样的静态抓取器。实际上 declarative-crawler 提供了多种类型的蜘蛛,譬如专门爬取静态网页的 HTMLSpider、爬取动态网页的 HeadlessChromeSpider、爬取接口的 JSONSpider.js 以及爬取数据库的 MySQLSpider 等等。而这里我们是需要以无界面浏览器将抓取到的静态页面、脚本、CSS 等协同渲染,然后得到真实的网页。这里我们使用 Headless Chrome 作为渲染载体,笔者会在未来的文章中介绍如何使用 Headless Chrome,这里我们只需要利用预设好的 Docker 镜像以服务的方式运行 Chrome 即可。实际上 HeadlessChromeSpider 就是对于 Chrome 远程调试协议的封装,如下代码中我们进行了简单的导航到 URL,然后等待页面加载完毕之后再抓取 HTML 值:
CDP(
{
host: this.host,
port: this.port
},
client => {
// 设置网络与页面处理句柄
const { Network, Page, Runtime } = client;
Promise.all([Network.enable(), Page.enable(), Runtime.enable()])
.then(() => {
return Page.navigate({
url
});
})
.catch(err => {
console.error(err);
client.close();
});
Network.requestWillBeSent(params => {
// console.log(params.request.url);
});
Page.loadEventFired(() => {
setTimeout(() => {
Runtime.evaluate({
expression: "document.body.outerHTML"
}).then(result => {
resolve(result.result.value);
client.close();
});
}, this.delay);
});
}
).on("error", err => {
console.error(err);
});不过这种方式并不能获取到我们想要的图片信息,我们可以利用 Network 模块监控所有的网络请求,可以发现因为知乎是根据滚动懒加载的方式加载图片,在页面加载完毕的事件触发时,实际上只会在 img 标签中加载好如下的一些小头像:
https://pic4.zhimg.com/a99b7a9933526403f0b012bd9c11dbbf_60w.jpg
https://pic1.zhimg.com/151ee0138f8432d61977504615d0614c_60w.jpg
https://pic2.zhimg.com/c2847b95e204cd6e23fca03d18610a65_60w.jpg
https://pic2.zhimg.com/5f026494c8bcc7283770e84c37c1aa49_60w.jpg
https://pic1.zhimg.com/4bd564be18599d169a6fab3b83f3c418_60w.jpg
https://pic1.zhimg.com/16eb0d6650f962d8ff1b0b339a4563cc_60w.jpg
https://pic1.zhimg.com/b6f5310d9fac7c173ce8e310f6196f38_60w.jpg
https://pic3.zhimg.com/0aac046c829d37edcf0b9ba780dc2f92_60w.jpg
https://pic3.zhimg.com/c4cdff37d72774768c202478c1adc1b6_60w.jpg
https://pic1.zhimg.com/aa1dc6506f009530c701ae9ae283c424_60w.jpg
https://pic4.zhimg.com/200c20e15a427b5a740bc7577c931133_60w.jpg
https://pic4.zhimg.com/7be083ae4531db70b9bd9149dc30dd1b_60w.jpg
https://pic2.zhimg.com/5261bc283c6c2ed2900a504e2677d365_60w.jpg
https://pic1.zhimg.com/9a6762c751175966686bf93bf009ab30_60w.jpg
https://pic4.zhimg.com/b1b92239d6718aa146b0669dc423e693_60w.jpg针对这种情况,我们的第一个思路就是模拟用户滚动,Chrome 为我们提供了 Input 模块来远程执行一些点击、触碰等模拟动作:
await Input.synthesizeScrollGesture({
x: 0,
y: 0,
yDistance: -10000,
repeatCount: 10
});不过这种方式性能较差,并且等待时间较长。另一个思路就是借鉴 Web 测试中的 MonkeyTest,在界面中插入额外的脚本,不过因为知乎的 Content Security Policy 禁止插入未知源的脚本,因此这种方式也是不行。

最后我们还是把视角放到界面中,发现知乎是将所有懒加载的图片放置到 noscript 标签中,因此我们可以直接从 noscript 标签中提取出懒加载的图片地址然后保存。
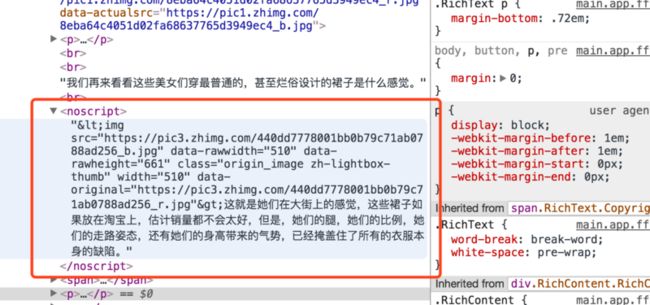
声明处理单页面的蜘蛛
主题列表页
我们首先需要声明抓取某个主题下所有答案列表的蜘蛛,其基本使用如下:
/**
* @function 知乎某个话题答案的爬虫
*/
export default class TopicSpider extends HeadlessChromeSpider {
// 定义模型
model = {
".feed-item": {
$summary: ".summary",
$question: ".question_link"
}
};
/**
* @function 默认解析函数
* @param pageObject
* @param $
* @returns {Array}
*/
parse(pageObject: any, $: Element) {
// 存放全部的抓取到的对象
let feedItems = [];
for (let {$question, $summary} of pageObject[".feed-item"]) {
feedItems.push({
questionTitle: $question.text(),
questionHref: $question.attr("href"),
answerHref: $($summary.find("a")).attr("href"),
summary: $summary.text()
});
}
return feedItems;
}
}声明蜘蛛我们最核心的是需要声明模型,即页面的 DOM 提取规则,这里我们底层使用的是 cherrio;然后声明解析方法,即从 DOM 元素对象中提取出具体的数据。然后我们可以使用 Jest 编写简单的单元测试:
// @flow
import TopicSpider from "../../spider/TopicSpider";
const expect = require("chai").expect;
let topicSpider: TopicSpider = new TopicSpider()
.setRequest("https://www.zhihu.com/topic/19552207/top-answers")
.setChromeOption("120.55.83.19");
test("抓取知乎某个话题下答案列表", async done => {
let answers = await topicSpider.run(false);
expect(answers, "返回数据为列表并且长度大于10").to.have.length.above(2);
done();
});答案页图片提取
对于答案页的提取则稍微复杂了一点,因为我们还需要声明图片下载器。在这里的 parse 函数中我们是对于所有的 img 标签与 noscript 下包含的图片链接进行了提取,最后调用内置的 downloadPersistor 来保存图片:
/**
* @function 专门用于爬取答案以及缓存的爬虫
*/
export default class AnswerAndPersistImageSpider extends HeadlessChromeSpider {
// 定义模型
model = {
// 抓取所有的默认
$imgs: "img",
// 抓取所有的延迟加载的大图
$noscript: "noscript"
};
/**
* @function 对提取出的页面对象进行解析
* @param pageElement 存放页面对象
* @param $ 整个页面的 DOM 表示
* @returns {Promise.}
*/
async parse(pageElement: any, $: Element): any {
// 存放所有图片
let imgs = [];
// 抓取所有默认图片
for (let i = 0; i < pageElement["$imgs"].length; i++) {
let $img = $(pageElement["$imgs"][i]);
imgs.push($img.attr("src"));
}
// 抓取所有 noscript 中包含的图片
for (let i = 0; i < pageElement["$noscript"].length; i++) {
// 执行地址提取
let regexResult = imageRegex.exec($(pageElement["$noscript"][i]).text());
if (regexResult) {
imgs.push(regexResult[0]);
}
}
return imgs;
}
/**
* @function 执行持久化操作
* @param imgs
* @returns {Promise.}
*/
async persist(imgs) {
await downloadPersistor.saveImage(imgs);
}
}
同样我们可以编写相关的单元测试:
// @flow
import AnswerAndPersistImageSpider
from "../../spider/AnswerAndPersistImageSpider";
const expect = require("chai").expect;
global.jasmine.DEFAULT_TIMEOUT_INTERVAL = 1000000;
// 初始化
let answerAndPersistImageSpider: AnswerAndPersistImageSpider = new AnswerAndPersistImageSpider()
.setRequest("https://www.zhihu.com/question/29134042")
.setChromeOption("120.55.83.19", null, 10 * 1000);
test("抓取知乎某个问题中所有的图片", async done => {
let images = await answerAndPersistImageSpider.run(false);
expect(images, "返回数据为列表并且长度大于10").to.have.length.above(2);
done();
});
test("抓取知乎某个问题中所有的图片并且保存", async done => {
let images = await answerAndPersistImageSpider.run(true);
done();
});声明串联多个蜘蛛的爬虫
负责采集和处理单页面的蜘蛛编写完毕之后,我们需要编写串联多个蜘蛛的爬虫:
export default class BeautyTopicCrawler extends Crawler {
// 初始化爬虫
initialize() {
// 构建所有的爬虫
let requests = [
{ url: "https://www.zhihu.com/topic/19552207/top-answers" },
{ url: "https://www.zhihu.com/topic/19606792/top-answers" }
];
this.setRequests(requests)
.setSpider(
new TopicSpider().setChromeOption("120.55.83.19", null, 10 * 1000)
)
.transform(feedItems => {
if (!Array.isArray(feedItems)) {
throw new Error("爬虫连接失败!");
}
return feedItems.map(feedItem => {
// 判断 URL 中是否存在 zhihu.com,若存在则直接返回
const href = feedItem.answerHref;
if (!!href) {
// 存在有效二级链接
return href.indexOf("zhihu.com") > -1
? href
: `https://www.zhihu.com${href}`;
}
});
})
.setSpider(
new AnswerAndPersistImageSpider().setChromeOption(
"120.55.83.19",
null,
10 * 1000
)
);
}
}爬虫最核心的即为其 initialize 函数,这里我们需要输入种子地址以及蜘蛛的串联配置,然后交由爬虫去自动执行。
服务端运行与监控
爬虫声明完毕后,我们即可以以服务端的方式运行整个爬虫:
// @flow
import CrawlerScheduler from "../../crawler/CrawlerScheduler";
import CrawlerServer from "../../server/CrawlerServer";
import BeautyTopicCrawler from "./crawler/BeautyTopicCrawler";
const crawlerScheduler: CrawlerScheduler = new CrawlerScheduler();
let beautyTopicCrawler = new BeautyTopicCrawler();
crawlerScheduler.register(beautyTopicCrawler);
new CrawlerServer(crawlerScheduler).run().then(
() => {},
error => {
console.log(error);
}
);服务启动之后,我们可以访问 3001 端口来获取当前系统的状态:
http://localhost:3001/
[
{
name: "BeautyTopicCrawler",
displayName: "Crawler",
isRunning: false,
lastStartTime: "2017-05-03T05:03:58.217Z"
}
]然后访问 start 地址来启动爬虫:
http://localhost:3001/start爬虫启动之后,我们可以查看具体的某个爬虫对应的运行情况:
http://localhost:3001/BeautyTopicCrawler
{
"leftRequest": 37,
"spiders": [
{
"name": "TopicSpider",
"displayName": "Spider",
"count": 2,
"countByTime": {
"0": 0,
"59": 0
},
"lastActiveTime": "2017-05-03T04:56:31.650Z",
"executeDuration": 13147.5,
"errorCount": 0
},
{
"name": "AnswerAndPersistImageSpider",
"displayName": "Spider",
"count": 1,
"countByTime": {
"0": 0,
"59": 0
},
"lastActiveTime": "2017-05-03T04:56:44.513Z",
"executeDuration": 159120,
"errorCount": 0
}
]
}我们也可以通过预定义的监控界面来实时查看爬虫运行状况(正在重制中,尚未接入真实数据),可以到根目录的 ui 文件夹中运行:
yarn install
npm start即可以看到如下界面:

最后我们也能够在本地的文件夹中查看到所有的抓取下来的图片列表(默认为 /tmp/images):