Postgresql 行列转换函数
PG自带了行列转换的函数
hank=> \c hank postgres
hank=# create extension tablefunc;
hank=>\dx
tablefunc | 1.0 | public| functions that manipulate whole tables, including crosstab
举例:
创建一个员工的工资表并初始化数据
create table tbl_rowtocol(name text,salary int,t_year int,t_month int);
insert into tbl_rowtocol values('bell',5000,2008,12);
insert into tbl_rowtocol values('bell',4000,2008,11);
insert into tbl_rowtocol values('bell',4000,2008,10);
insert into tbl_rowtocol values('bell',3000,2008,09);
insert into tbl_rowtocol values('bell',3000,2008,08);
insert into tbl_rowtocol values('bell',5000,2008,07);
insert into tbl_rowtocol values('bell',5000,2008,06);
insert into tbl_rowtocol values('bell',5000,2008,05);
insert into tbl_rowtocol values('bell',5000,2008,04);
insert into tbl_rowtocol values('bell',5000,2008,03);
insert into tbl_rowtocol values('bell',1000,2008,02);
insert into tbl_rowtocol values('bell',2000,2008,01);
insert into tbl_rowtocol values('bell',2000,2010,01);
insert into tbl_rowtocol values('bell',1000,2010,05);
insert into tbl_rowtocol values('reson',2000,2008,01);
insert into tbl_rowtocol values('reson',2000,2008,04);
insert into tbl_rowtocol values('reson',2000,2008,07);
insert into tbl_rowtocol values('reson',2000,2008,09);
下面就利用自带的函数进行行列转换
先看语法
| Function | Returns | Description |
|---|---|---|
| de>normal_rand(int numvals, float8 mean, float8 stddev)de> | setof float8 | Produces a set of normally distributed random values --返回numvals个正态分布随机值 |
| de>crosstab(text sql)de> | setof record | Produces a "pivot table" containing row names plus N value columns, where N is determined by the row type specified in the calling query --返回一个行名称加上N列数值二维表,N由查询的结果而定 |
| de>crosstabN(text sql)de> | setof table_crosstab_N | Produces a "pivot table" containing row names plus N value columns. de>crosstab2de>,de>crosstab3de>, and de>crosstab4de> are predefined, but you can create additionalde>crosstabNde> functions as described below |
| de>crosstab(text source_sql, text category_sql)de> | setof record | Produces a "pivot table" with the value columns specified by a second query --列由category_sql而定 |
| de>crosstab(text sql, int N)de> | setof record | Obsolete version of de>crosstab(text)de>. The parameter N is now ignored, since the number of value columns is always determined by the calling query --已废弃 |
| de>connectby(text relname, text keyid_fld, text parent_keyid_fld [, text orderby_fld ], text start_with, int max_depth [, text branch_delim ])de> | setof record | Produces a representation of a hierarchical tree structure --返回一个树状结构 |
select substr(name,1,char_length(name)-4) as name,substr(name,char_length(name)-3) as year,
"Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"
from crosstab('select name||t_year,t_month,salary from tbl_rowtocol order by 1','select * from generate_series(1,12) order by 1')
as (name text,"Jan" int,"Feb" int,"Mar" int,"Apr" int,"May" int,"Jun" int,"Jul" int,"Aug" int,"Sep" int,"Oct" int,
"Nov" int,"Dec" int) order by 1,2;
这里用到crosstab(text source_sql, text category_sql)
source_sql = select name||t_year,t_month,salary from tbl_rowtocol order by 1 --数据源SQL
category_sql = select * from generate_series(1,12) order by 1 --需要分为列的SQL,这里有12个值,
所以分别代表1~12月
这里解释下
select substr(name,1,char_length(name)-4) --截取名称
select substr(name,char_length(name)-3) --截取年
这里要按name||t_year列分组,只不过通过substr分成2个比较容易好看的字段
name||t_year是分组列
t_month 是需要成为每一列的
salary是对应值
(name text,"Jan" int,"Feb" int,"Mar" int,"Apr" int,"May" int,"Jun" int,"Jul" int,"Aug" int,"Sep" int,"Oct" int,
"Nov" int,"Dec" int) --这里定义列类型,注意这里要定义name text 是source_sql中"name||t_year"列
语句得到一个这样的二维表

normal_rand实例:
取10个值,平均数为8 ,方差为5
hank=> SELECT * FROM normal_rand(10, 8, 5);
normal_rand
-------------------
14.1461903681259
6.71858432804888
1.7629468082413
9.95435832036283
5.22620689349945
8.90771881275266
-1.28601983743638
10.8009828959392
3.29085668056401
11.0749340357927
crosstab(text sql)实例
引用官方文档的实例
CREATE TABLE ct(id SERIAL, rowid TEXT, attribute TEXT, value TEXT);
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att1','val1');
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att2','val2');
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att3','val3');
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att4','val4');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att1','val5');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att2','val6');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att3','val7');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att4','val8');
SELECT *
FROM crosstab(
'select rowid, attribute, value
from ct
where attribute = ''att2'' or attribute = ''att3''
order by 1,2')
AS ct(row_name text, category_1 text, category_2 text, category_3 text);
row_name | category_1 | category_2 | category_3
----------+------------+------------+------------
test1 | val2 | val3 |
test2 | val6 | val7 | 当然这里category_3 text可以去掉,因为这里需要分为列的attribute值只有2个值att2和att3.hank=> select * from ct;
id | rowid | attribute | value
----+-------+-----------+-------
1 | test1 | att1 | val1
2 | test1 | att2 | val2
3 | test1 | att3 | val3
4 | test1 | att4 | val4
5 | test2 | att1 | val5
6 | test2 | att2 | val6
7 | test2 | att3 | val7
8 | test2 | att4 | val8这里返回attribute=att2 和attribute=att3的一个二维表,参照原表标红的记录比较直观。
connectby:
语法结构:
connectby(text relname, text keyid_fld, text parent_keyid_fld
[, text orderby_fld ], text start_with, int max_depth
[, text branch_delim ])| Parameter | Description |
|---|---|
| relname | Name of the source relation --源表名称 |
| keyid_fld | Name of the key field --键值名称 |
| parent_keyid_fld | Name of the parent-key field --父节点键值名称 |
| orderby_fld | Name of the field to order siblings by (optional) --排序兄弟的字段名 |
| start_with | Key value of the row to start at --键值开始值 |
| max_depth | Maximum depth to descend to, or zero for unlimited depth --最大深度,0表示无限深度 |
| branch_delim | String to separate keys with in branch output (optional) --分支输出时的分隔符 |
官方文档的例子看一下
CREATE TABLE connectby_tree(keyid text, parent_keyid text, pos int);
INSERT INTO connectby_tree VALUES('row1',NULL, 0);
INSERT INTO connectby_tree VALUES('row2','row1', 0);
INSERT INTO connectby_tree VALUES('row3','row1', 0);
INSERT INTO connectby_tree VALUES('row4','row2', 1);
INSERT INTO connectby_tree VALUES('row5','row2', 0);
INSERT INTO connectby_tree VALUES('row6','row4', 0);
INSERT INTO connectby_tree VALUES('row7','row3', 0);
INSERT INTO connectby_tree VALUES('row8','row6', 0);
INSERT INTO connectby_tree VALUES('row9','row5', 0);
-- with branch, without orderby_fld (order of results is not guaranteed)
SELECT * FROM connectby('connectby_tree', 'keyid', 'parent_keyid', 'row2', 0, '~')
AS t(keyid text, parent_keyid text, level int, branch text);
keyid | parent_keyid | level | branch
-------+--------------+-------+---------------------
row2 | | 0 | row2
row4 | row2 | 1 | row2~row4
row6 | row4 | 2 | row2~row4~row6
row8 | row6 | 3 | row2~row4~row6~row8
row5 | row2 | 1 | row2~row5
row9 | row5 | 2 | row2~row5~row9
(6 rows)
-- without branch, without orderby_fld (order of results is not guaranteed)
SELECT * FROM connectby('connectby_tree', 'keyid', 'parent_keyid', 'row2', 0)
AS t(keyid text, parent_keyid text, level int);
keyid | parent_keyid | level
-------+--------------+-------
row2 | | 0
row4 | row2 | 1
row6 | row4 | 2
row8 | row6 | 3
row5 | row2 | 1
row9 | row5 | 2
(6 rows)
-- with branch, with orderby_fld (notice that row5 comes before row4)
SELECT * FROM connectby('connectby_tree', 'keyid', 'parent_keyid', 'pos', 'row2', 0, '~')
AS t(keyid text, parent_keyid text, level int, branch text, pos int);
keyid | parent_keyid | level | branch | pos
-------+--------------+-------+---------------------+-----
row2 | | 0 | row2 | 1
row5 | row2 | 1 | row2~row5 | 2
row9 | row5 | 2 | row2~row5~row9 | 3
row4 | row2 | 1 | row2~row4 | 4
row6 | row4 | 2 | row2~row4~row6 | 5
row8 | row6 | 3 | row2~row4~row6~row8 | 6
(6 rows)
-- without branch, with orderby_fld (notice that row5 comes before row4)
SELECT * FROM connectby('connectby_tree', 'keyid', 'parent_keyid', 'pos', 'row2', 0)
AS t(keyid text, parent_keyid text, level int, pos int);
keyid | parent_keyid | level | pos
-------+--------------+-------+-----
row2 | | 0 | 1
row5 | row2 | 1 | 2
row9 | row5 | 2 | 3
row4 | row2 | 1 | 4
row6 | row4 | 2 | 5
row8 | row6 | 3 | 6
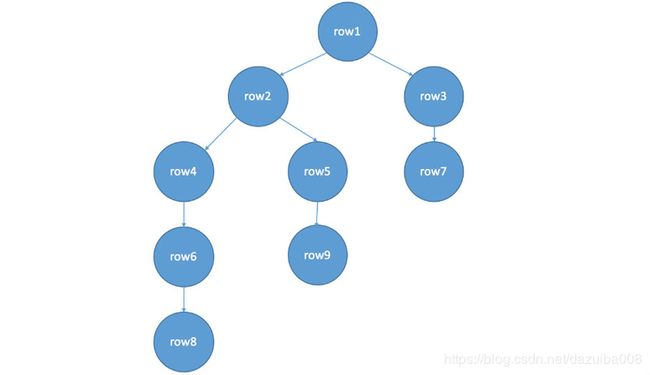
(6 rows)hank=> select * from connectby_tree ;
keyid | parent_keyid | pos
-------+--------------+-----
row1 | | 0
row2 | row1 | 0
row3 | row1 | 0
row4 | row2 | 1
row5 | row2 | 0
row6 | row4 | 0
row7 | row3 | 0
row8 | row6 | 0
row9 | row5 | 0
hank=> SELECT * FROM connectby('connectby_tree', 'keyid', 'parent_keyid', 'row1', 0, '~')
AS t(keyid text, parent_keyid text, level int, branch text) order by 1;
keyid | parent_keyid | level | branch
-------+--------------+-------+--------------------------
row1 | | 0 | row1
row2 | row1 | 1 | row1~row2
row3 | row1 | 1 | row1~row3
row4 | row2 | 2 | row1~row2~row4
row5 | row2 | 2 | row1~row2~row5
row6 | row4 | 3 | row1~row2~row4~row6
row7 | row3 | 2 | row1~row3~row7
row8 | row6 | 4 | row1~row2~row4~row6~row8
row9 | row5 | 3 | row1~row2~row5~row9
以上2个对比起来看比较直观一些,以下是树形图
参考:https://www.postgresql.org/docs/current/static/tablefunc.html