用C++进行hadoop程序开发(hadoop Pipes)
经过几天的努力与查资料,终于实现了分布式模式下运行C++版的MapReduce。下面介绍主要步骤和遇到的问题及解决方案。
系统配置:
在Linux系统上已安装好hadoop 2.5.2版本(本人系统为CentOS7.0(64位系统)。
选择工具:
Hadoop采用java编写,因而Hadoop天生支持java语言编写作业,但在实际应用中,有时候,因要用到非java的第三方库或者其他原因,要采用C/C++或者其他语言编写MapReduce作业,如果用C/C++编写MpaReduce作业,可使用的工具有Hadoop Streaming或者Hadoop Pipes。
Streaming 是利用进程之间的标准输入输出流来进行通信,而 pipes 是利用 socket 来通信。由于 hadoop 是用 java 开发的,所以需要做的就是将其他语言跟 java 进程通信,即跨语言的通信。主要的问题是数据类型的转化问题,因为最低层都是走字节数组的方式。在 pipes 包里面实现了 c/c++ 与 java 之间的通信。故选择了Hadoop Pipes。
步骤:
1、 确保hadoop集群已经搭建了,并已掌握了一些基本的Linux命令。
2、 编写CPP文件
在任意个编辑工具编写CPP文件,我是在Notepad++编写(Notepad++功能强大可以编写与打开各种类型的文件)。编写完后另存为max_temperature.cpp,具体内容附在下面:
#include
#include
#include
#include
#include
#include
#include
class MaxTemperatureMapper : public HadoopPipes::Mapper {
public:
MaxTemperatureMapper(HadoopPipes::TaskContext& context) {
}
void map(HadoopPipes::MapContext& context) {
std::string line = context.getInputValue();
std::string year = line.substr(15, 4);
std::string airTemperature = line.substr(87, 5);
std::string q = line.substr(92, 1);
if (airTemperature != "+9999" &&
(q == "0" || q == "1" || q == "4" || q == "5" || q == "9")) {
context.emit(year, airTemperature);
}
}
};
class MapTemperatureReducer : public HadoopPipes::Reducer {
public:
MapTemperatureReducer(HadoopPipes::TaskContext& context) {
}
void reduce(HadoopPipes::ReduceContext& context) {
int maxValue = INT_MIN;
while (context.nextValue()) {
maxValue = std::max(maxValue, HadoopUtils::toInt(context.getInputValue()));
}
context.emit(context.getInputKey(), HadoopUtils::toString(maxValue));
}
};
int main(int argc, char *argv[]) {
return HadoopPipes::runTask(HadoopPipes::TemplateFactory());
} 3、 编写Makefile文件,也是在Notepad++中编写
编写完后保存并命名为Makefile,注意必须是只有M是大写的,具体内容附在下面。其中,HADOOP_DEV_HOME表示的是hadoop的安装路径;m64是表示64位系统,如果是32位系统,则改为m32。
HADOOP_DEV_HOME = /local/hadoop/hadoop-2.5.2
CC=g++
CPPFLAGS = -m64
SRCS = max_temperature.cpp
PROGRAM = max_temperature
INC_PATH = -I$(HADOOP_DEV_HOME)/include
LIB_PATH = -L$(HADOOP_DEV_HOME)/lib/native
LIBS = -lhadooppipes -lhadooputils -lpthread
$(PROGRAM):$(SRCS)
$(CC) $(CPPFLAGS) $(INC_PATH) $< -lcrypto -lssl -Wall $(LIB_PATH) $(LIBS) -g -O2 -o $@
clean:
rm -f *.o max_temperature4、 安装gcc, g++, 标准C库
1).安装gcc
sudo yum install gcc -y
2).安装g++
sudo yum install gcc-c++ -y
3).安装标准C库
sudo yum install glibc-devel –y
5、 安装openssl
直接选择了系统自带的,没有安装新版本。用openssl version查看版本。也可以根据http://blog.csdn.net/menuconfig/article/details/8796242安装openssl。
6、 make
切换到max_temperature.cpp和Makefile所在路径下,然后make,即命令为make max_temperature。
7、 上传文件到HDFS
1)上传本地可执行文件max_temperature到HDFS的bin/max_temperature目录下: hadoop fs -putmax_temperature bin/max_temperature
2)上传数据到HDFS: hadoop fs -put sample.txt sample.txt
3)sample.txt内容如下:
0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+99999999999
0043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+99999999999
0043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+99999999999
0043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+99999999999
0043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+999999999998、 使用hadoop pipes命令运行作业,命令如下:
hadoop pipes -Dhadoop.pipes.java.recordreader=true -D hadoop.pipes.java.recordwriter=true-input sample.txt -output output -program bin/max_temperature
9、 查看作业执行结果:
hadoop fs -cat output/*
若结果为
1949 111
1950 22
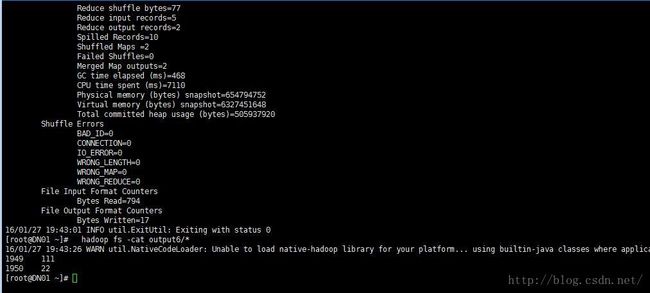
成功啦!
出现问题:
1、make时,若出现这样的错误:
/usr/bin/ld: cannot find –lcrypto
/usr/bin/ld: cannot find –lssl
则需要添加 -lssl,-lcrypto的链接,原因是没有找到 libssl.so。
ll /usr/lib64/libssl*,得到
-rwxr-xr-x.1 root root 242112 Jul 17 2012 /usr/lib64/libssl3.so
lrwxrwxrwx. 1 root root 15 Nov 30 01:31 /usr/lib64/libssl.so.10-> libssl.so.1.0.0
-rwxr-xr-x. 1 root root 372488 Aug 23 2012 /usr/lib64/libssl.so.1.0.0
根本原因是,虽然有libssl的动态库文件,但没有文件名为 libssl.so的文件,ld找不到它,于是添加软链接:
ln-s /usr/lib64/libssl.so.1.0.0 /usr/lib64/libssl.so
ln-s /usr/lib64/libcrypto.so.1.0.0 /usr/lib64/libcrypto.so
然后再重新make时,问题就没有了,并make成功。

参照:http://blog.csdn.net/yasi_xi/article/details/8658191
2、Unauthorizedrequest to start container
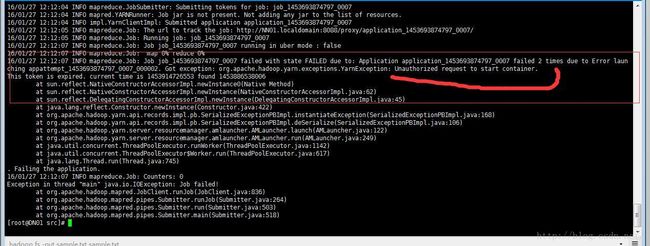
问题原因:namenode,datanode时间同步问题
解决办法:多个datanode与namenode进行时间同步,在每台服务器执行:ntpdate time.nist.gov,确认时间同步成功。
参照:http://www.sharpcloud.cn/thread-4927-1-1.html
主要参考文献:
1、 http://www.bkjia.com/yjs/1003476.html Hadoop实战 Hadoop Pipes运行C++程序问题解决,hadooppipes
2、 http://blog.csdn.net/lxxgreat/article/details/7755369 hadoop下的Pipes(用C++进行hadoop程序开发)
3、 http://blog.csdn.net/yasi_xi/article/details/8658191 关于/usr/bin/ld:cannot find -lcrypto 的错误