php下载大文件的方法
假设一个场景:
当用户需要通过我们提供的下载服务,来下载一个较大的文件(200M-2G)时,我们服务端应该如何来满足这个服务呢?
且当我们的服务端是采用nginx+php的架构时,该如何解决呢。
作为服务端接口层,我们需要从数据层(可能是云存储,可能是类似于亚马逊S3的存储服务)下载较大文件(200M--2G),然后将下载得到的文件,返回给请求客户端。
且当我们的服务端接口层是采用nginx+php的架构时,该如何解决呢。
如下图所示:

最初的解决方法(但无法彻底解决):
很多同学最初的解决办法,可能会直接采用curl函数,得到返回内容之后,echo 这个返回内容,结束php程序,然后nginx收到php的echo结果,再返回给请求端。
如下图所示:

这段下载代码很简单,如下:
$ch = \curl_init($url);
\curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); // 获取数据返回
\curl_setopt($ch, CURLOPT_BINARYTRANSFER, true); // 在启用 CURLOPT_RETURNTRANSFER 时候将获取数据返回
\curl_setopt($ch, CURLOPT_HTTPHEADER, $headerArr);
\curl_setopt($ch, CURLOPT_HEADER, 1);
\curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
\curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 60);
\curl_setopt($ch, CURLOPT_TIMEOUT, 60);
$output = \curl_exec($ch);
echo $output;
这样做,对下载较小的文件,不会有啥问题。但是当需要下载的文教较大时,就会出现许多错误:
1、php进程内存溢出:
由于是将整个文件全部下载,并且放在$output变量里面,该变量是存在于内存中的,所以一旦文件过大,就会导致php内存溢出。(许多同学会想到更改php内存限制,但是这毕竟不是一个长久之计,且不说下载上G的文件,会给服务器带来多少压力;如果并发下载,可能会很快将系统内存消耗殆尽,导致服务挂掉)
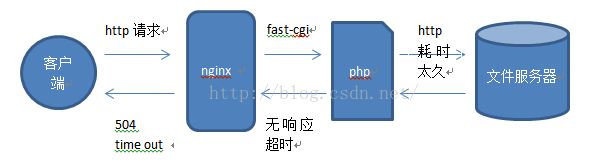
2、下载时间过长,nginx没有得到响应,导致nginx向请求端报错(httpcode 504报错)
由于按照上述方法下载,只有当下载完成后,才会将结果返回响应给nginx,而由于下载文件较大,耗时过长,整个php进程的执行时间就会较大。nginx在接受到客户端请求之后,将请求发送给php-cgi(通过fast-cgi运行)程序,然后等待php进程返回,但nginx并不会一直等待,在nginx中有一个配置项,fastcgi_read_timeout,该配置项决定了nginx等待fast-cgi返回超时阈值,默认是60秒。当一个请求超过60秒没有处理完并且响应的话,nginx就会按照请求超时的逻辑报错(504 timeout报错 )。(当然同样也可以通过修改这个配置项的值来避免超时的出现,但是这仍然不是一种最优的选择,因为这样客户端会等待很久,并且在整个等待过程中,没有任何响应信息)
如图所示:
所以考虑到通过该方法下载,有至少两个较为致命的缺陷,我们给出了第二种解决办法。
第二种解决办法:
简单地说:通过curl_setopt($ch, CURLOPT_WRITEFUNCTION, function($ch ,$str))方法,将文件一段一段返回。
具体如下:
curl_setopt()函数中,有一个配置叫做:CURLOPT_WRITEFUNCTION,通过这个配置,可以实现,一个curl回调方法:php官方手册是这样描述该配置的:A callback accepting two parameters. The first is the cURL resource, and the second is a string with the data to be written. The data must be saved by this callback. It must return the exact number of bytes written or the transfer will be aborted with an error(大致的中文意思就是:该回调接受两个参数。第一个是cURL资源,第二个是具有要写入的数据的字符串。数据必须通过此回调保持。它必须写入确切字节数,否则传输将中止并出现错误)
这样的描述可能会让读者觉得困惑,别急,我们通过代码进行分析:
$ch = \curl_init($url);
\curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
\curl_setopt($ch, CURLOPT_BINARYTRANSFER, true);
\curl_setopt($ch, CURLOPT_HTTPHEADER, $headerArr);
\curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
\curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 60);
\curl_setopt($ch, CURLOPT_TIMEOUT, 3600);
curl_setopt($ch, CURLOPT_BUFFERSIZE, 20971520);
$flag=0;
curl_setopt($ch, CURLOPT_WRITEFUNCTION, function($ch ,$str) use (&$flag){
$len = strlen($str);
$flag++;
$type = \curl_getinfo($ch, CURLINFO_CONTENT_TYPE);
if($flag==1){
$size = \curl_getinfo($ch, CURLINFO_CONTENT_LENGTH_DOWNLOAD);
$type = \curl_getinfo($ch, CURLINFO_CONTENT_TYPE);
$httpcode = \curl_getinfo($ch, CURLINFO_HTTP_CODE);
\header("HTTP/1.1 ".$httpcode);
\header("Content-Type: ".$type);
\header("Content-Length: ".$size);
\header('Content-Transfer-Encoding: binary');
\header('Cache-Control:max-age=2592000');
}
echo $str;
return $len;
});
$output = \curl_exec($ch);
核心部分就在最后一个curl_setopt中,可以看到这里配置了CURLOPT_WRITEFUNCTION,紧接着是一个函数,
function($ch ,$str) use (&$flag){
$len = strlen($str);
$flag++;
if($flag==1){
$size = \curl_getinfo($ch, CURLINFO_CONTENT_LENGTH_DOWNLOAD);
$type = \curl_getinfo($ch, CURLINFO_CONTENT_TYPE);
$httpcode = \curl_getinfo($ch, CURLINFO_HTTP_CODE);
\header("HTTP/1.1 ".$httpcode);
\header("Content-Type: ".$type);
\header("Content-Length: ".$size);
\header('Content-Transfer-Encoding: binary');
\header('Cache-Control:max-age=2592000');
}
echo $str;
return $len;
}
这个函数就是之前讲到的回调函数。
该函数需要传入两个参数,也就是上面提到的,cURL资源,以及字符串。curl资源不必赘述,着重说一下字符串$str。
当程序执行到\curl_exec($ch);处时,整个curl网络请求就开始了,当请求端的数据到达我们服务端的那一刻,数据会被放入一个缓冲区,由于是大文件,所以数据会源源不断的持续到达,当缓冲区收到一定数量的返回值后,就会调用这个回调函数,并将返回得到的数据传入这里的$str变量。我们获取这个$str变量,并将它echo就可以瞬时发送给nginx响应,nginx拿到响应数据,立即会返回到客户端,这样就能很好的解决上面提到的两个致命缺陷,1、php进程内存消耗不会持续增加,2,nginx不会响应超时。回调函数的末尾有一个return $len; 这里的$len是$str的长度;我们需要返回这个长度,也就是之前提到的,必须写入确切的字符串。其实也很好理解,我们将字符串的长度抛出,下一次调用回调函数时,才能正确定位接下来该从哪里传值。
另外,我加入了一个flag作为标记,通过use(&flag)的方式(有点类似于c语言中的引用),可将flag作为变量,并在函数中不断累加,起到标记作用。当flag为1时,我们尝试去获取http的返回头,拿到响应码,文件类型,文件长度,然后进行拼接成我们想要返回给客户端的http响应头信息,这里还加上了缓存时间\header('Cache-Control:max-age=2592000');方便请求端做缓存过期策略。
简单总结:
整个大文件下载过程,策略就到此结束,该方法可以一举解决内存占用过大,nginx响应超时,客户端无响应时间过长三个问题。还需要注意一点,在设置CURLOPT_TIMEOUT,需要适当调大一些,这样对应耗时较长的超大文件下载,才不会在中途断开。至于中途断开该如何进行断点续传,我们下一篇章再接着讲述。