Hadoop学习笔记2-HDFS的安装与部署以及HDFS Shell命令
总结上一次:
1)hadoop是什么? 包含3个组件 HDFS、MapReduce、Common组件
2)HDFS的架构读写操作 包含两个重要的节点NameNode(数据块信息)NataNode 数据块
3) MapReduce框架 input map分 shuffle reduce 汇总 output
4)hadoop的生态系统 hbase hive pig oozie zookeeper 等
5) hadoop版本选择1.x,2.0
namenode ha 0.21.x 0.23.x 2.x
hdfs federation & yarn 0.23.x 2.x
1 HDFS集群环境搭建
hadoop1.x源码和二进制文件混合,2.x只包含二进制包
下载hadoop1.2.1
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
下载到centos home目录解压
查看hadoop目录结构 1.2.1
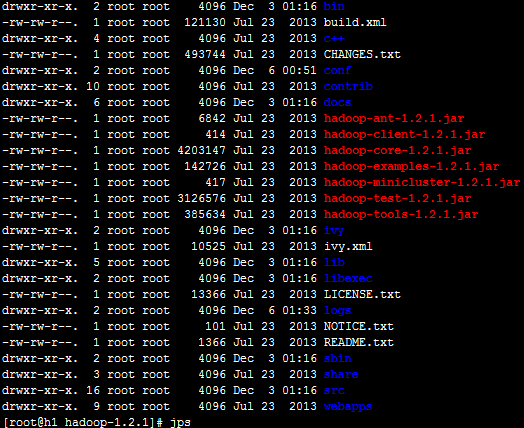
/bin 启动和命令脚本
/conf 配置信息
/sbin 环境配置脚本
/source 源代码
查看hadoop目录结构2.5.2
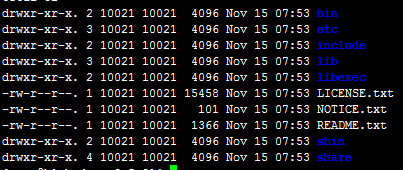
/bin 存放的启动和命令 运行脚本
/etc 存放配置信息
/share 存放hadoop相关的jar包以及对应的一系列的字节码
HDFS部署
独立模式 伪分布式模式 分布式模式
配置
fs.default.name(file:///、hdfs://localhost:port、hdfs://namende:prot)
dfs.replication(、1、3)
mapred.job.tracker (jobtracker监听地址)(local、localhost:8021、jobtracker:8021
hadoop1.x采用ant编译 2.x采用maven编译
配置虚拟机
配置core-site.xml

修改hdfs-site.xml 配置副本个数、name目录、data目录

配置完成后到../bin下 ./start-dfs.sh 启动dfs
如果出现JAVA_HOME error错误需要到../conf/hadoop-evn.sh

添加
停止重新执行 ./start-dfs.sh
jps查看

发现nodenode不存在,需要停掉服务,使用 ./hadoop namenode -format 格式化dfs.name.dir dfs.data.dir创建目录


重新停掉启动过程中出现需要输入密码现象
需要ssh-keygen -t rsa创建秘钥,cat id_rsa.put > authorized_keys
生成秘钥并拷贝到authorized_keys
2 HDFS shell命令
./hadoop fs 命令
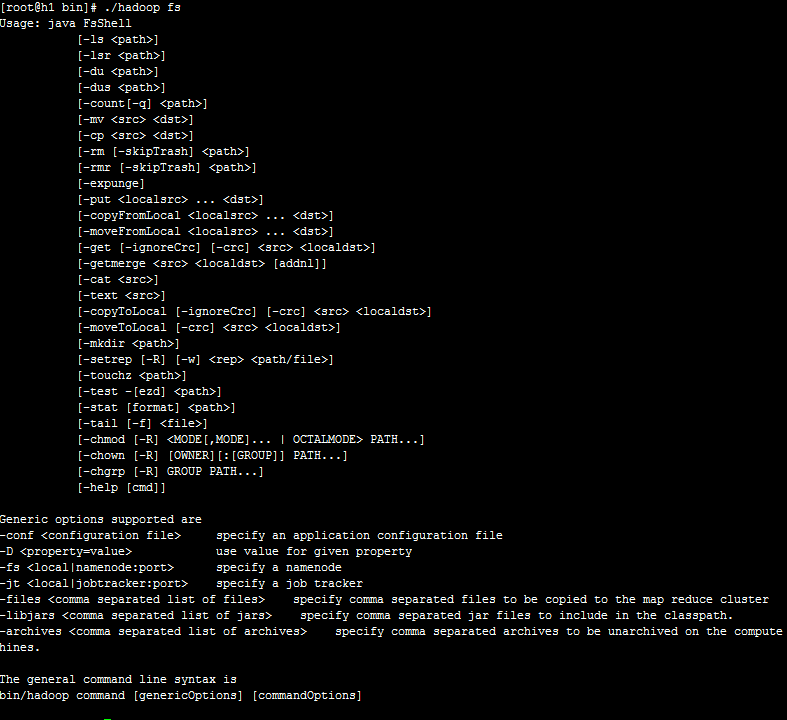
上传文件、空间大小、查看目录结构等
./hadoop dfsadmin -report 报告文件系统信息
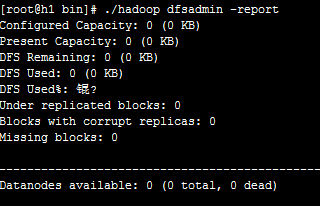
./hadoop dfsadmin -safemode enter 开启只读模式,将不能添加和删除hdfs文件,只有重新关闭只读模式就可以上传了

./hadoop dfsadmin setSpaceQuota设置上传文件大小限制
![]()

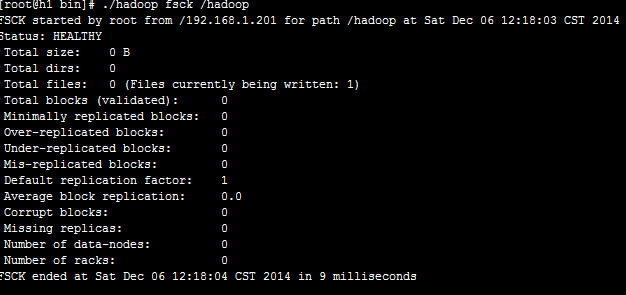
文件系统检测工具fsck作用:
检查文件系统的健康状态;
查看一个文件所在的数据块
删除一个坏块
可以查找一个缺失的块
磁盘均衡器
更具磁盘情况对数据块进行重新布局
./hadoop balancer 或者 ./start-balancer.sh启动

文件归档
将小文件合并查看
其他相关的shell 脚本参考:http://hadoop.apache.org/docs/r1.2.1/file_system_shell.html
3HDFS shell启动脚本分析
./start-dfs.sh启动hadoop-daemon.sh 然后启动hadoop.sh命令然后根据命令行参数执行java程序
hadoop-darmon.sh与hadoop-daemons.sh的区别:前者启动本地后者启动远程