「Deep Learning」Note on RetinaNet
Sina Weibo:小锋子Shawn
Tencent E-mail:[email protected]
http://blog.csdn.net/dgyuanshaofeng/article/details/80790128
0 摘要
| 范式 | 候选包围盒 | 速度 | 精度 | 例子 |
|---|---|---|---|---|
| One-stage | dense(~100k) | fast | low | SSD, DSSD, YOLO, RetinaNet(this study) |
| Two-stage | sparse(~1-2k) | low | high | R-CNN, FastR-CNN, FasterR-CNN, MaskR-CNN, FPN |
提出Focal Loss[1]解决extreme foreground-background class imbalance,在生物医学图像上,可解决不同细胞的检测、分割等问题,还可解决MR脑图分割、CT肺图结节检测等。
分析表 1,两阶段式方法虽然包围盒是sparse,但是这些都是难例(hard examples),另外由于主干模型复杂,因此速度较慢,但是精度较高。而一阶段式方法包围盒是dense,easy negatives太多,“训歪”检测器(bias了检测器),速度较快,但是精度较低(低于两阶段式10~40%)。
1 介绍
两阶段:1、proposal stage;2、classification stage
proposal stage有如下候选方法:Selective Search, EdgeBoxes, DeepMask和RPN。
classification stage通常使用sampling heuristics,有两种:1、固定前景-背景比例1:3;2、在线难例挖掘。
一阶段:直接分类规则候选物体位置(包围盒)
解决类别不平衡(class imbalance)方法:1、bootsrapping;2、难例挖掘。
2 相关工作
鲁棒估计 鲁棒损失函数,比如Huber loss,针对outliers会进行降权值down-weghting,因为outliers带来更大的误差。相反,Focal loss针对inliters会进行降权值,因为inliters是easy examples,对总误差贡献较少(而且数量非常大)。
3 焦点损失 Focal Loss
二分类CE损失:
p p 为 y=1 y = 1 时,模型估计概率。
加权CE损失:
p p 为 y=1 y = 1 时,模型估计概率。 α α 为0到1之间的加权因子,通常为类别频率的倒数。
FL损失:
p p 为 y=1 y = 1 时,模型估计概率。 γ γ 为不小于0的调制因子。
其具有两个特点:1、如果一个example被误分,针对 y=1 y = 1 ,p会较小,针对 y=−1 y = − 1 ,p会较大,根据 FL(p,y) F L ( p , y ) 公式,调制因子会接近1,对损失不产生影响。相反(不误分),根据 FL(p,y) F L ( p , y ) 公式,调制因子会接近0,分类较好的例子所贡献的损失会降加权(down-weighted);2、 γ γ 降加权比较平滑。其为0时,FL等价于CE损失。
加权FL损失:
类似加权CE损失
4 RetinaNet检测器
RetinaNet网络示意图如图 1所示,一个主干网络加两个子网络,其一用于物体分类,其二用于包围盒坐标/位置回归。
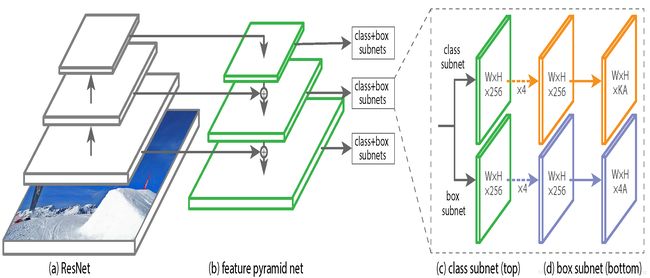
主干网络:类似特征金字塔网络FPN[2]。
候选框:
分类子网络:在每层金字塔水平上,使用4层 3×3 3 × 3 卷积+ReLU激活函数,卷积核个数为 C=256 C = 256 ,再跟着1层 3×3 3 × 3 卷积,卷积核个数为 KA K A ,最后跟着1层sigmoid激活函数。
包围盒回归子网络:小型FCN的网络结构同 分类子网络,但是使用独立的参数,即不shared,而RPN[3]是shared的。
推理和训练:
1、 Inference:在每一金字塔水平上,经过阈值处理0.05,取得大约1000个高分预测,然后所有水平上的预测进行合并merge,再用非最值抑制NMS(0.5)。
2、 Focal Loss: γ=2,α=0.25 γ = 2 , α = 0.25 works best。
3、 Initialization:ResNet和FPN使用预训练模型进行初始化,新添加卷积层使用高斯 σ=0.01 σ = 0.01 和零值 bias=0 b i a s = 0 初始化。分类子网络最后一层卷积使用 bias=−log((1−π)/π),π=0.01 b i a s = − l o g ( ( 1 − π ) / π ) , π = 0.01 。
4、 Optimization:同步(synchronized)SGD,8GPU,每个GPU2幅图像,共16幅图像每minibatch。0k次迭代,学习率为0.01,60k学习率降10倍,80k再降10倍。数据扩充采用水平翻转。 weight decay=0.0001 w e i g h t d e c a y = 0.0001 , momentum=0.9 m o m e n t u m = 0.9 。训练损失为FL损失和smooth L1损失[4]之和。
5 实验
[1] Focal Loss for Dense Object Detection ICCV 2017 [paper]
[2] Feature Pyramid Networks for Object Detection CVPR 2017 [paper]
[3] Faster R-CNN Towards Real-time Object Detection with Region Proposal Networks NIPS 2015 [paper]
[4] Fast R-CNN ICCV 2015 [paper]