【机器学习】主题模型(一):条件概率、矩阵分解
两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让搜索更加智能化。主题模型是对文字隐含主题进行建模的方法,其克服传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。
关键词:主题模型
技术领域:搜索技术、自然语言处理
**********************************************
主题模型训练推理方法主要有2种:
(1) pLSA→EM(期望最大化)
(2) LDA → Gibbs Sampling抽样方法(计算量大,单精确)、变分贝叶斯推断法(计算量小,精度弱)
----------------------------------------------------------------------
概率矩阵:p(词语|文档) =∑p(词语|主题)× p(主题|文档)
C = Φ × Θ
在EM(最大期望)过程中:
(1) E过程:由贝叶斯可从Φ算到Θ
(2) M过程:由贝叶斯可从Θ算到Φ
两者迭代,最终收敛(矩阵趋于均分)
***********************************************
设有两个句子,想知道它们之间是否相关联:
第一个是:“乔布斯离我们而去了。”
第二个是:“苹果价格会不会降?”
如果由人来判断,一看就知道,这两个句子之间虽然没有任何公共词语,但仍然是很相关的。因为虽然第二句中的“苹果”可能是指吃的苹果,但是由于第一句里面有了“乔布斯”,我们会很自然的把“苹果”理解为苹果公司的产品。事实上,这种文字语句之间的相关性、相似性问题在搜索引擎算法中经常遇到。例如,一个用户输入了一个query,我们要从海量的网页库中找出和它最相关的结果。这里就涉及到如何衡量query和网页之间相似度的问题。对于这类问题,人是可以通过上下文语境来判断的。但是,机器可以么?
在传统信息检索领域里,实际上已经有了很多衡量文档相似性的方法,比如经典的VSM模型。然而这些方法往往基于一个基本假设:文档之间重复的词语越多越可能相似。这一点在实际中并不尽然。很多时候相关程度取决于背后的语义联系,而非表面的词语重复。
那么,这种语义关系应该怎样度量呢?事实上在自然语言处理领域里已经有了很多从词、词组、句子、篇章角度进行衡量的方法。本文要介绍的是其中一个语义挖掘的利器:主题模型。
一、主题模型定义
主题模型,顾名思义,就是对文字中隐含主题的一种建模方法。还是上面的例子,“苹果”这个词的背后既包含是苹果公司这样一个主题,也包括了水果的主题。当我们和第一句进行比较时,苹果公司这个主题就和“乔布斯”所代表的主题匹配上了,因而我们认为它们是相关的。
关于主题定义:主题就是一个概念、一个方面。它表现为一系列相关的词语。比如一个文章如果涉及到“百度”这个主题,那么“中文搜索”、“李彦宏”等词语就会以较高的频率出现,而如果涉及到“IBM”这个主题,那么“笔记本”等就会出现的很频繁。如果用数学来描述一下的话,主题就是词汇表上词语的条件概率分布 。与主题关系越密切的词语,它的条件概率越大,反之则越小。
例如:

通俗来说,一个主题就好像一个“桶”,它装了若干出现概率较高的词语。这些词语和这个主题有很强的相关性,或者说正是这些词语共同定义了这个主题。对于一段话,有些词语可以出自这个“桶”,有些可能来自那个“桶”,一段文本往往是若干个主题的杂合体。举个简单的例子,见下图。

以上是从互联网新闻中摘抄下来的一段话。划分了4个桶(主题),百度(红色),微软(紫色)、谷歌(蓝色)和市场(绿色)。段落中所包含的每个主题的词语用颜色标识出来。从颜色分布上我们就可以看出,文字的大意是在讲百度和市场发展。在这里面,谷歌、微软这两个主题也出现了,但不是主要语义。值得注意的是,像“搜索引擎”这样的词语,在百度、微软、谷歌这三个主题上都是很可能出现的,可以认为一个词语放进了多个“桶”。当它在文字中出现的时候,这三个主题均有一定程度的体现。
如何得到这些主题?对文章中的主题又是如何进行分析?这正是主题模型要解决的问题。主题模型如何工作?
二、主题模型工作原理
首先,用生成模型的视角来看文档和主题这两件事。所谓生成模型就是认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。那么如果要生成一篇文档,它里面的每个词语出现的概率为:
上面这个式子,可以矩阵乘法来表示,如下图所示:
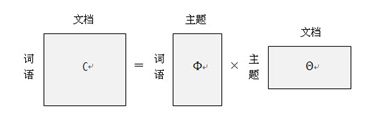
左边的C矩阵表示每篇文章中每次词语出现的概率;中间的Φ矩阵表示的是每个主题中每个词语出现的概率P(词语|主题),也就是每个“桶”表示的是每篇文档中各个主题出现的概率p(主题|文档) ,可以理解为一段话中每个主题所占的比例。
假如有很多的文档,比如大量的网页,先对所有文档进行分词,得到一个词汇列表。这样每篇文档就可以表示为一个词语的集合。对于每个词语,可以用它在文档中出现的次数除以文档中词语的数目作为它在文档中出现的概率p(词语|文档) 。这样对任意一篇文档,左边的C矩阵是已知的,右边的两个矩阵未知。而主题模型就是用大量已知的“词语-文档”C矩阵 ,通过一系列的训练,推理出右边的“词语-主题”矩阵Φ 和“主题文档”矩阵Θ 。
主题模型训练推理的方法主要有两种,一个是pLSA(Probabilistic Latent Semantic Analysis),另一个是LDA(Latent Dirichlet Allocation)。pLSA主要使用的是EM(期望最大化)算法;LDA采用的是Gibbssampling方法。由于它们都较为复杂且篇幅有限,这里就只简要地介绍一下pLSA的思想,其他具体方法和公式,读者可以查阅相关资料。
pLSA采用的方法叫做EM(期望最大化)算法,它包含两个不断迭代的过程:E(期望)过程和M(最大化)过程。用一个形象的例子来说吧:比如说食堂的大师傅炒了一盘菜,要等分成两份给两个人吃,显然没有必要拿天平去一点点去精确称量,最简单的办法是先随意的把菜分到两个碗中,然后观察是否一样多,把比较多的那一份取出一点放到另一个碗中,这个过程一直重复下去,直到大家看不出两个碗里的菜有什么差别为止。
对于主题模型训练来说,“计算每个主题里的词语分布”和“计算训练文档中的主题分布”就好比是在往两个人碗里分饭。在E过程中,我们通过贝叶斯公式可以由“词语-主题”矩阵计算出“主题-文档”矩阵。在M过程中,我们再用“主题-文档”矩阵重新计算“词语-主题”矩阵。这个过程一直这样迭代下去。EM算法的神奇之处就在于它可以保证这个迭代过程是收敛的。也就是说,我们在反复迭代之后,就一定可以得到趋向于真实值的Φ和Θ。
三、主题模型应用
有了主题模型,如何使用?以及优缺点?主要是以下几点:
(1) 可以衡量文档之间的语义相似性。对于一篇文档,我们求出来的主题分布可以看作是对它的一个抽象表示。对于概率分布,我们可以通过一些距离公式(比如KL距离)来计算出两篇文档的语义距离,从而得到它们之间的相似度。
(2) 可以解决多义词的问题。回想最开始的例子,“苹果”可能是水果,也可能指苹果公司。通过求出来的“词语-主题”概率分布,就可以知道“苹果”都属于哪些主题,就可以通过主题的匹配来计算它与其他文字之间的相似度。
(3) 可以排除文档中噪音的影响。一般来说,文档中的噪音往往处于次要主题中,我们可以把它们忽略掉,只保持文档中最主要的主题。
(4) 它是无监督、完全自动化。只需要提供训练文档,它就可以自动训练出各种概率,无需任何人工标注过程。
(5) 跟语言无关。任何语言只要能够对它进行分词,就可以进行训练,得到它的主题分布。
综上所述,主题模型是一个能够挖掘语言背后隐含信息的利器。近些年来各大搜索引擎公司都已经开始重视这方面的研发工作。语义分析的技术正在逐步深入到搜索领域的各个产品中去。以后的搜索会趋于更加智能化。
--------------------------------------------------------------------------------------------------------------------
LSA(潜在语义分析)
鉴于TF-IDF存在一些缺点,Deerwester等人于1990年提出潜在语义分析(LatentSemanticAnalysis)模型,用于挖掘文档与词语之间隐含的潜在语义关联。LSA的理论基础是数学中的奇异值矩阵分解(SVD)技术。
PLSA(基于概率的潜在语义分析)
鉴于LSA存在一些缺点,Hofmann等人于1999年提出一种基于概率的潜在语义分析(Probabilistic Latent SemanticAnalysis)模型。PLSA继承了“潜在语义”的概念,通过“统一的潜在语义空间”(也就是Blei等人于2003年正式提出Topic概念)来关联词与文档;通过引入概率统计的思想,避免了SVD的复杂计算。在PLSA中,各个因素(文档、潜在语义空间、词)之间的概率分布求解是最重要的,EM算法是常用的方法。PLSA也存在一些缺点:概率模型不够完备;随着文档和词的个数的增加,模型变得越来越庞大;在文档层面没有一个统计模型;EM算法需要反复迭代,计算量也很大。
LDA(潜在狄瑞雷克模型)
鉴于PLSA的缺点,Blei等人于2003年进一步提出新的主题模型LDA(LatentDirichletAllocation),它是一个层次贝叶斯模型,把模型的参数也看作随机变量,从而可以引入控制参数的参数,实现彻底的“概率化”。
是LDA模型的Dirichlet的先验分布,表示整个文档集上主题的分布;表示文档d上主题的多项式分布;Z表示文档d的第n个词的主题;W表示文档d的第n个词;N表示文档d所包含词的个数;D表示文档集;K表示主题集;表示主题k上词语的多项式分布;表示所有主题上次的先验分布。事实上,去掉和 ,LDA就变成了PLSA。目前,参数估计是LDA最重要的任务,主要有两种方法:Gibbs抽样法(计算量大,但相对简单和精确)和变分贝叶斯推断法(计算量小,精度度弱)。
其他基于topic model的演变
a) 考虑上下文信息:例如,“上下文相关的概率潜在语义分析模型(ContextualProbabilistic LatentSemantic Analysis,CPLSA)”将词语上下文信息引入PLSA;也有研究人员考虑“地理位置”上下文信息,从地理位置相关的文档中发现地理位置关联的Topic。
b) 主题模型演化:引入文本语料的时间信息,研究主题随时间的演化,例如DTM、CTDTM、DMM、OLDA等模型。
c)并行主题模型:在大规模数据处理的需求下,基于并行计算的主题模型也开始得到关注。现有的解决方案有:Mallet、GPU-LDA、Async-LDA、N.C.L、pLDA、Y!LDA、Mahout、Mr.LDA等;其中pLDA、Y!LDA、Mahout、Mr.LDA等基于Hadoop/MapReduce框架,其他方案则基于传统的并行编程模型;参数估算方面,Mallet、Async-LDA、pLDA、Y!LDA等使用Gibbs抽样方法,Mr.LDA、Mahout、N.C.L等使用变分贝叶斯推断法,GPU-LDA同时支持两种方法。