部署Faster-RCNN TensorFlow版本
部署Faster-RCNN TensorFlow版本
- 创建Anaconda环境
- Conda命令创建新环境
- Conda安装所需包
- gcc降级
- 下载tf-faster-rcnn和数据集
- 克隆代码
- 根据你的显卡更新setup脚本中的arch参数
- 编译Cython
- 安装COCO API
- 下载PASCAL VOC数据集
- 用预训练模型演示并测试
- 下载并解压预训练模型
- 创建一个文件夹和一个软链接以使用预训练模型
- 对示例图片的测试演示
- 用预训练好的Resnet101模型对数据进行测试
- 训练你的模型
- 下载预训练模型和权重
- 训练(测试和评估)
- 用Tensorboard可视化
- 测试与评估
- 再评估
- 补充说明
- 自己标注数据集
- XML格式
- 安装conda包
- 下载标注工具labelImg
- 使用labelImg进行标注
- 准备自己的数据集并进行训练
- 建立数据集
- 改程序
- 训练与测试
- 应用
创建Anaconda环境
首先利用Anaconda创建并配置一个独立的Python环境,在此我的环境名字为tf-faster-rcnn 。
Conda命令创建新环境
打开终端,通过conda命令创建名为tf-faster-rcnn的新环境,同时指定python版本为3.6:
su@Laptop-su:~$ conda create -n tf-faster-rcnn python=3.6
若想删除conda环境,可采用下面命令:
su@Laptop-su:~$ conda remove -n tf-faster-rcnn --all
Conda安装所需包
在终端内使用下面命令进入tf-faster-rcnn环境:
su@Laptop-su:~$ source activate tf-faster-rcnn
可以通过下面指令确认自己所在的环境位置:
(tf-faster-rcnn) su@Laptop-su:~$ conda env list
若要退出tf-faster-rcnn环境,返回默认环境,使用下面命令:
(tf-faster-rcnn) su@Laptop-su:~$ source deactivate
在tf-faster-rcnn环境下,使用conda命令逐一安装所需包:
1.tensorflow-gpu
(tf-faster-rcnn) su@Laptop-su:~$ conda install tensorflow-gpu
会自动将最新版本的tensorflow-gpu版本以及其依赖的包比如cudatoolkit、cudnn、scipy、scikit-learn、numpy安装完毕,我安装时如果不指定版本自动安装会安装tensorflow-gpu=1.12,cudatoolkit=9.2,cudnn=7.2.1,注意cuda的版本是要跟你的N卡驱动匹配的,看下图
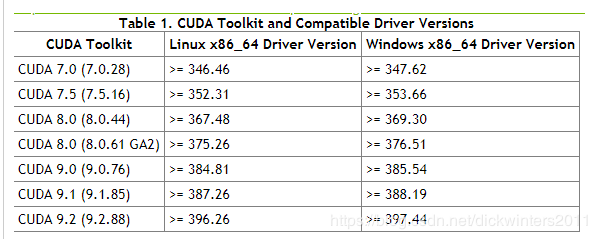
我的N卡驱动版本是390.77,并且不想升级显卡驱动,因此CUDA最高可选择9.1,我决定先安装CUDA9.0
可以通过下面命令安装指定版本的包:
(tf-faster-rcnn) su@Laptop-su:~$ conda install cudatoolkit=9.0
再安装tensorflow,会自动将匹配CUDA9.0的cudnn版本附带安装完毕
(tf-faster-rcnn) su@Laptop-su:~$ conda install tensorflow-gpu
这样安装完成后,我的环境里是tensorflow-gpu=1.12,cudatoolkit=9.0,cudnn=7.1.2
2.py-opencv
(tf-faster-rcnn) su@Laptop-su:~$ conda install py-opencv
我安装时自动安装的是py-opencv=3.4.2
3.matplotlib
(tf-faster-rcnn) su@Laptop-su:~$ conda install matplotlib
4.cython
(tf-faster-rcnn) su@Laptop-su:~$ conda install cython
5.pillow
(tf-faster-rcnn) su@Laptop-su:~$ conda install pillow
6.pyyaml
(tf-faster-rcnn) su@Laptop-su:~$ conda install pyyaml
7.easydict
conda库中不提供easydict的安装,需要使用pip命令进行安装:
(tf-faster-rcnn) su@Laptop-su:~$ pip install easydict
我安装时,自动安装的是easydict=1.9
gcc降级
我们要git的tf-faster-rcnn不支持6以上版本的gcc,因此要对gcc进行降级或者改变不同版本的优先级.
- 查看gcc版本
在终端中输入如下命令:
su@Laptop-su:~$ gcc -v
会显示gcc version
在此我的gcc版本为7
- 查看安装有哪些版本的gcc
在终端中输入如下命令:
su@Laptop-su:~$ ls /usr/bin/gcc*
如果没有需要的版本,则需要进行第3步安装指定版本
- 安装指定版本gcc
以安装gcc5为例,在终端中输入如下命令:
su@Laptop-su:~$ sudo apt-get install gcc-5 g++-5
- 配置gcc优先级
在终端中输入如下命令调整优先级,数值越低优先级越高:
su@Laptop-su:~$ sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 50
su@Laptop-su:~$ sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 40
输入如下命令,确认配置:
su@Laptop-su:~$ sudo update-alternatives --config gcc
同样也要设置一下g++的:
su@Laptop-su:~$ sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 50
su@Laptop-su:~$ sudo update-alternatives --install /usr/bin/g++ gc++/usr/bin/g++-5 40
如果想删除可选项的话可以键入以下指令:
su@Laptop-su:~$ sudo update-alternatives --remove gcc /usr/bin/gcc-7
- 检查当前gcc版本
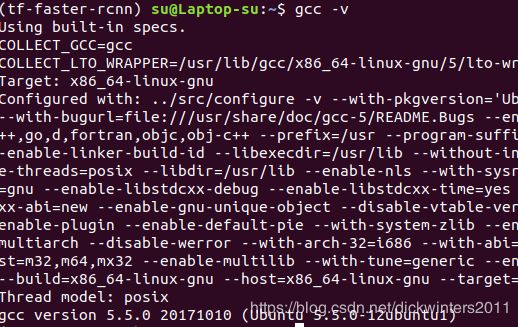
在终端中输入如下命令:
su@Laptop-su:~$ gcc -v
显示如下:
下载tf-faster-rcnn和数据集
克隆代码
在想要下载的位置下通过终端输入下列命令:
su@Laptop-su:~/GitHub$ git clone https://github.com/endernewton/tf-faster-rcnn.git
根据你的显卡更新setup脚本中的arch参数
修改tf-faster-rcnn/lib/setup.py中第130行的arch参数
比如我的显卡是1070,算力是6.1,所以是sm_61
你显卡的算力可以查询下面网址:
https://developer.nvidia.com/cuda-gpus#collapseOne
编译Cython
在tf-faster-rcnn/lib路径下,在tf-faster-rcnn环境下输入终端命令:
# 清除之前编译结果
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/lib$ make clean
# 编译
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/lib$ make
安装COCO API
这是为了使用COCO数据库
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ cd data
# 下载COCO API
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data$ git clone https://github.com/pdollar/coco.git
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data$ cd coco/PythonAPI
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/coco/PythonAPI$ make
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/coco/PythonAPI$ cd ../../..
下载PASCAL VOC数据集
- 下载训练集,验证集,测试集以及VOCdevkit
在想要存放数据集的位置打开终端,输入下列命令:
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
- 将所有压缩包解压到一个名为VOCdevkit的文件夹中
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC$ tar xvf VOCtrainval_06-Nov-2007.tar
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC$ tar xvf VOCtest_06-Nov-2007.tar
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC$ tar xvf VOCdevkit_08-Jun-2007.tar
- VOCdevkit文件夹应由如下构成
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC/VOCdevkit$ # development kit
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC/VOCdevkit/VOCdevkit/VOCcode$ # VOC utility code
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC/VOCdevkit/VOCdevkit/VOC2007$ # image sets, annotations, etc.
- 创建数据集的软连接
su@Laptop-su:/media/su/学习/数据集/样本库/PASCAL VOC/VOCdevkit$ cd ~/GitHub/tf-faster-rcnn/data
su@Laptop-su:~/GitHub/tf-faster-rcnn/data$ ln -s "/media/su/学习/数据集/样本库/PASCAL VOC/VOCdevkit" VOCdevkit2007
用预训练模型演示并测试
下载并解压预训练模型
# Resnet101 for voc pre-trained on 07+12 set
su@Laptop-su:~/GitHub/tf-faster-rcnn$ ./data/scripts/fetch_faster_rcnn_models.sh
该sh文件中提供了两个下载地址,但是由于是外网可能下载很慢,可以直接从百度网盘下载并解压到 ./data/下
感谢下文博主传到百度云的链接:预训练模型 密码:8ahl
https://blog.csdn.net/char_QwQ/article/details/80980505
#解压
su@Laptop-su:~/GitHub/tf-faster-rcnn/data$ tar zxvf voc_0712_80k-110k.tgz
解压完如下图

创建一个文件夹和一个软链接以使用预训练模型
在tf-faster-rcnn根目录创建一个output文件夹并且在其中存放预训练模型的软链接,output文件夹中会在每次训练后存放训练好的模型
su@Laptop-su:~/GitHub/tf-faster-rcnn$ NET=res101
su@Laptop-su:~/GitHub/tf-faster-rcnn$ TRAIN_IMDB=voc_2007_trainval+voc_2012_trainval
su@Laptop-su:~/GitHub/tf-faster-rcnn$ mkdir -p output/${NET}/${TRAIN_IMDB}
su@Laptop-su:~/GitHub/tf-faster-rcnn$ cd output/${NET}/${TRAIN_IMDB}
su@Laptop-su:~/GitHub/tf-faster-rcnn/output/res101/voc_2007_trainval+voc_2012_trainval$ ln -s ../../../data/voc_2007_trainval+voc_2012_trainval ./default
su@Laptop-su:~/GitHub/tf-faster-rcnn/output/res101/voc_2007_trainval+voc_2012_trainval$ cd ../../..
如下图
对示例图片的测试演示
上面的Res101网络预训练模型是已经经过imagenet和voc0712数据集训练好的,用demo来调用output文件夹下的该模型,展示其实际检测效果
注意切到tf-faster-rcnn的python环境下
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ GPU_ID=0
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ CUDA_VISIBLE_DEVICES=${GPU_ID} ./tools/demo.py

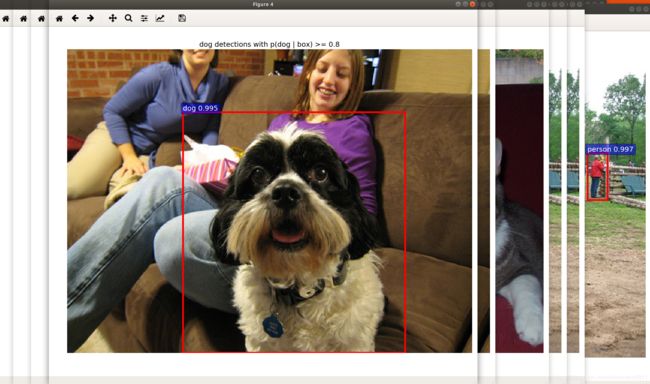
用预训练好的Resnet101模型对数据进行测试
同样采用上面在ImageNet和VOC0712上训练过的Resnet101预训练模型,对其用VOC0712的test测试集进行测试(查阅test_faster_rcnn.sh会发现,其实所用的就是VOC07的test测试集)
感谢这位博主提供的参考
把tf-faster-rcnn/lib/datasets/voc_eval.py的第121行的
with open(cachefile,'w') as f
改成:
with open(cachefile,'wb') as f
同时还要把第105行的
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
改为
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile.split("/")[-1].split(".")[0])
然后在终端中输入下面命令
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ GPU_ID=0
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ ./experiments/scripts/test_faster_rcnn.sh $GPU_ID pascal_voc_0712 res101
结果如图所示
 测试完毕后同样会在output文件夹下建立一个路径为
测试完毕后同样会在output文件夹下建立一个路径为
/output/res101/voc_2007_test/default/res101_faster_rcnn_iter_110000/
的文件夹,res101代表网络名称,voc_2007_test代表数据集,与训练不同,该文件夹下不再是模型文件
训练你的模型
下载预训练模型和权重
该程序目前支持VGG16和ResnetV1(包括50\101\152)网络结构,这4种网络结构都经过了ImageNet数据集的预训练,其预训练模型由slim提供,可以在这里下载。将其下载并放在data/imagenet_weights文件夹下。下面将以VGG16模型为例,讲解VGG16如何利用VOC数据集进行训练。
# 建立imagenet_weights文件夹
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ mkdir -p data/imagenet_weights
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ cd data/imagenet_weights
# 下载vgg16模型到imagenet_weights文件夹下并解压缩,你也可以到本小节上面的网址里下载
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/imagenet_weights$ wget -v http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz
tar -xzvf vgg_16_2016_08_28.tar.gz
# 模型重命名,这是为了给test_faster_rcnn.sh传入参数NET时符合其候选项命名
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/imagenet_weights$ mv vgg_16.ckpt vgg16.ckpt
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/imagenet_weights$ cd ../..
同理,下载ResNet101的方式如下:
# 建立imagenet_weights文件夹
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ mkdir -p data/imagenet_weights
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ cd data/imagenet_weights
# 下载vgg16模型到imagenet_weights文件夹下并解压缩,你也可以到本小节上面的网址里下载
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/imagenet_weights$ wget -v http://download.tensorflow.org/models/resnet_v1_101_2016_08_28.tar.gz
tar -xzvf resnet_v1_101_2016_08_28.tar.gz
# 模型重命名,这是为了给test_faster_rcnn.sh传入参数NET时符合其候选项命名
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/imagenet_weights$ resnet_v1_101.ckpt res101.ckpt
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn/data/imagenet_weights$ cd ../..
训练(测试和评估)
训练的格式如下
./experiments/scripts/train_faster_rcnn.sh [GPU_ID] [DATASET] [NET]
# GPU_ID 是你要使用的GPU编号
# NET 是你采用的网络类型, 可选范围为{vgg16, res50, res101, res152}
# DATASET 是数据集,在train_faster_rcnn.sh中预先定义过{pascal_voc, pascal_voc_0712, coco} ,还可以根据自己需要进行添加
# Examples:
./experiments/scripts/train_faster_rcnn.sh 0 pascal_voc vgg16
./experiments/scripts/train_faster_rcnn.sh 1 coco res101
上面在演示demo时,在output中建立了一个经过VOC0712数据集训练好的Res101模型的软链接
如果有再次使用VOC0712数据集对Res101进行训练的需要,记得删除掉该软链接
下面使用VOC07数据集训练VGG16(,并测试):
为了节省时间并排除错误,我把迭代次数只设置了20次,即在./experiments/scripts/train_faster_rcnn.sh里的第22行把ITERS=70000改成ITERS=20,同时由于train_faster_rcnn.sh中最后有调用test_faster_rcnn.sh,因此记得把./experiments/scripts/test_faster_rcnn.sh的ITERS也改成20。
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ ./experiments/scripts/train_faster_rcnn.sh 0 pascal_voc vgg16
结果如图
 可见由于只训练了20代,准确度是非常之差的
可见由于只训练了20代,准确度是非常之差的
运行train_faster_rcnn.sh后会自动运行test_faster_rcnn.sh,即训练完会自动进行测试
用Tensorboard可视化
训练完成后,可以使用Tensorboard对训练过程的log进行可视化
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ tensorboard --logdir=tensorboard/vgg16/voc_2007_trainval/ --port=7001 &
logdir用来设置想要把Tensorboard的event文件存放在哪里,port用来设置通过哪个端口显示Tensorboard界面

上述命令在tensorboard文件夹下创建了如下文件
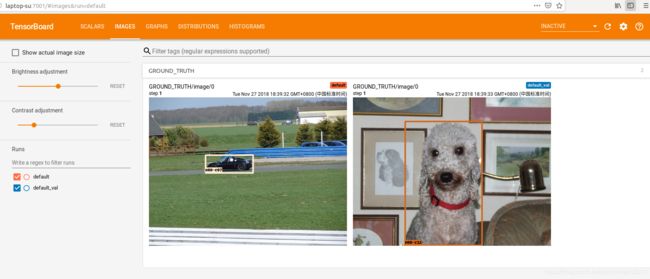
在浏览器中输入对应网址打开tensorboard界面如下(我只训练了20代所以仅做参考)
测试与评估
类似训练的过程,只不过是调用test_faster_rcnn.sh而不是train_faster_rcnn.sh,即只用测试集进行测试,并不进行训练
./experiments/scripts/test_faster_rcnn.sh [GPU_ID] [DATASET] [NET]
# GPU_ID 是你要使用的GPU编号
# NET 是你采用的网络类型, 可选范围为{vgg16, res50, res101, res152}
# DATASET 是数据集,在train_faster_rcnn.sh中预先定义过{pascal_voc, pascal_voc_0712, coco} ,还可以根据自己需要进行添加
# Examples:
./experiments/scripts/test_faster_rcnn.sh 0 pascal_voc vgg16
./experiments/scripts/test_faster_rcnn.sh 1 coco res101
再评估
可以使用tools/reval.sh进行在评估
补充说明
默认情况下,训练好的网络存放在:
output/[NET]/[DATASET]/default/
如
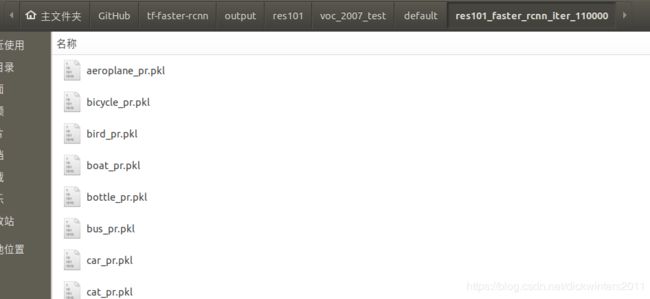
测试的输出结果存放在:
output/[NET]/[DATASET]/default/[SNAPSHOT]/
如
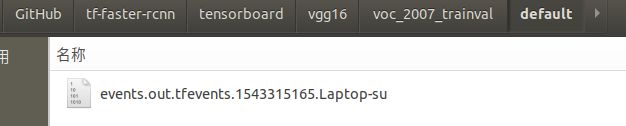
训练和验证的Tensorboard信息存放在:
tensorboard/[NET]/[DATASET]/default/
tensorboard/[NET]/[DATASET]/default_val/
如
自己标注数据集
推荐使用下面工具按照VOC数据集采用的xml格式标注
XML格式
安装conda包
- lxml
(tf-faster-rcnn) su@Laptop-su:~/GitHub$ conda install lxml
- qt
(tf-faster-rcnn) su@Laptop-su:~/GitHub$ conda install qt
下载标注工具labelImg
git到哪个路径无所谓,后面执行标注工具时切到该路径即可
su@Laptop-su:~/GitHub$ git clone https://github.com/tzutalin/labelImg.git
共计200+M大小,下载速度较慢,大概1小时,耐心等候,若断网需要删除重下
下载好后,到标注工具文件夹下输入如下代码配置完毕:
(tf-faster-rcnn) su@Laptop-su:~/GitHub/labelImg$ pyrcc5 -o resources.py resources.qrc
输入下面代码调用标注工具:
(tf-faster-rcnn) su@Laptop-su:~/GitHub/labelImg$ python labelImg.py
界面如图
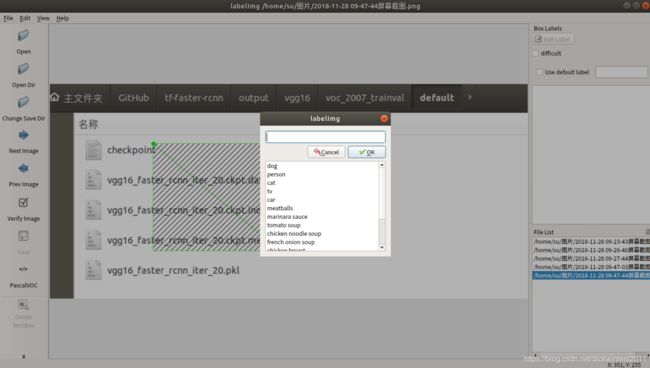
使用labelImg进行标注
-
改变标注文件夹位置
点击Menu/File中的Change default saved annotation folder -
选择图片路径
点击Open Dir -
创建矩形框
点击Create RectBox -
点击和松开鼠标左键来选择一个要标注的区域
-
可以使用鼠标右键拖拽矩形框来进行复制或移动
| 快捷键 | 用途 |
|---|---|
| Ctrl + u | 载入某路径下的所有图片 |
| Ctrl + r | 改变标注文件存放默认路径 |
| Ctrl + s | 保存 |
| Ctrl + d | 复制当前标签与矩形框 |
| Space | Flag the current image as verified |
| w | 创建矩形框 |
| d | 下一张图片 |
| a | 上一张图片 |
| del | 删除选中的矩形框 |
| Ctrl++ | 放大 |
| Ctrl– | 缩小 |
| ↑→↓← | 键盘方向键移动选中的矩形框 |
准备自己的数据集并进行训练
建立数据集
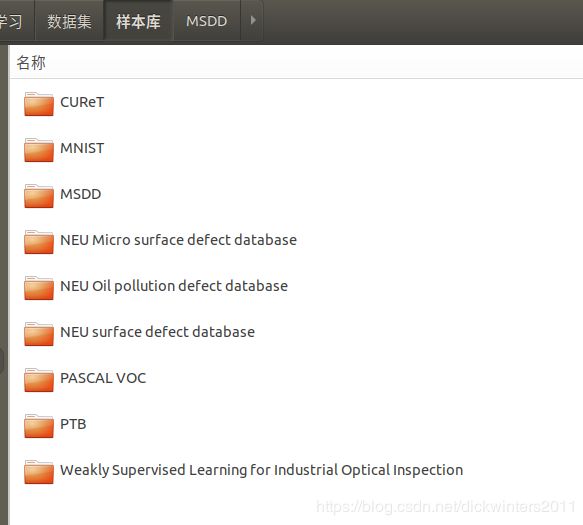
我们将仿照VOC2007的格式建立自己的数据集
-
找到你存放PASCAL VOC数据集的位置建立一个文件夹,我的数据集命名为"MSDD"
-
在MSDD文件夹下,建立3个文件夹
ananotations_cache里存放的是标注缓存数据,如果你对数据集有改动,记得清除缓存数据,否则的话依旧加载的是原始数据 -
results文件夹下依次创建如下路径

-
VOC2007文件夹下创建如下3个子文件夹
在Annotations目录下存放所有的xml标签文件,名字格式为000001.xml
在JPEGImages目录下存放所有的jpg图片,名字格式为000001.jpg -
在ImageSets文件夹下创建3个子文件夹
其中Main文件夹下存放的是记录各个子集所包含样本编号的txt文件
可以有很多子集,运行程序时指定哪个子集就会使用哪个子集
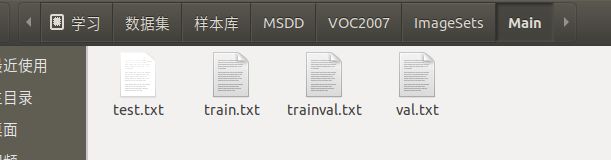
在这里我做了4个子集
txt中的格式如下

建议在筛选训练集、验证集、测试集时使用随机方法,在此我仅做演示
- 在data文件夹下建立软链接
建立软链接的方式上面提到过了
其实完全可以直接把数据集放在data文件夹下,但是因为有时一个数据集可能为多个代码重复使用,因此,使用软链接不失为一种更佳的方式
改程序
- 新建msdd.py
在lib/dataset/目录下复制pascal_voc.py并以自己的数据集命名
该文件会生成该各个子数据集的imdb,如msdd_train、msdd_val等
改了哪些位置注意看下面的对照
# pascal_voc.py
class pascal_voc(imdb):
def __init__(self, image_set, year, use_diff=False):
name = 'voc_' + year + '_' + image_set
if use_diff:
name += '_diff'
imdb.__init__(self, name)
self._year = year
self._image_set = image_set
self._devkit_path = self._get_default_path()
self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
self._class_to_ind = dict(list(zip(self.classes, list(range(self.num_classes)))))
self._image_ext = '.jpg'
self._image_index = self._load_image_set_index()
# Default to roidb handler
self._roidb_handler = self.gt_roidb
self._salt = str(uuid.uuid4())
self._comp_id = 'comp4'
# PASCAL specific config options
self.config = {'cleanup': True,
'use_salt': True,
'use_diff': use_diff,
'matlab_eval': False,
'rpn_file': None}
# msdd.py
class msdd(imdb):
def __init__(self, image_set):
name = 'msdd_' + image_set
imdb.__init__(self, name)
self._year = '2007'
self._image_set = image_set
self._devkit_path = self._get_default_path()
self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year) # 数据位置 data/MSDD/VOC2007
self._classes = ('__background__', # always index 0
'cr', 'ln', 'pa', 'ps', # 改成自己的类别
'rs', 'sc')
self._class_to_ind = dict(list(zip(self.classes, list(range(self.num_classes)))))
self._image_ext = '.jpg' # 建议使用jpg格式
self._image_index = self._load_image_set_index()
# Default to roidb handler
self._roidb_handler = self.gt_roidb
self._salt = str(uuid.uuid4())
self._comp_id = 'comp4'
# PASCAL specific config options
self.config = {'cleanup': True,
'use_salt': True,
'use_diff': False, # 关闭use_diff
'matlab_eval': False,
'rpn_file': None}
# pascal_voc.py
def _get_default_path(self):
"""
Return the default path where PASCAL VOC is expected to be installed.
"""
return os.path.join(cfg.DATA_DIR, 'VOCdevkit' + self._year)
# msdd.py
def _get_default_path(self):
"""
Return the default path where PASCAL VOC is expected to be installed.
"""
return os.path.join(cfg.DATA_DIR, 'MSDD')
# 开发包位置 data/MSDD
- 修改factory.py
该文件同样在lib/dataset/目录下
该文件生成由各个子数据集(xxx_train、xxx_test)的imdb格式组成的字典,其中会调用如pascal_voc.py、msdd.py等文件,以按各个数据集的指定格式生成各个子数据集的imdb
仿照其他格式在相应位置插入下面代码
# factory.py
# Set up mssd_- 修改train_faster_rcnn.sh
仿照其他数据集,添加自己数据集,可选的IMDB都是在factory.py中生成的
# train_faster_rcnn.sh
msdd)
TRAIN_IMDB="msdd_trainval" # 训练所用IMDB
TEST_IMDB="msdd_test" # 测试所用IMDB
STEPSIZE="[50000]"
ITERS=20
ANCHORS="[8,16,32]"
RATIOS="[0.5,1,2]"
;;
- 修改test_faster_rcnn.sh
仿照其他数据集,添加自己数据集,可选的IMDB都是在factory.py中生成的
# test_faster_rcnn.sh
msdd)
TRAIN_IMDB="msdd_trainval" # 训练所用IMDB
TEST_IMDB="msdd_test" # 测试所用IMDB
ITERS=20
ANCHORS="[8,16,32]"
RATIOS="[0.5,1,2]"
;;
训练与测试
(tf-faster-rcnn) su@Laptop-su:~/GitHub/tf-faster-rcnn$ ./experiments/scripts/train_faster_rcnn.sh 0 msdd vgg16
应用
修改tools/demo.py里面的’CLASSES‘、’NETS’以及’DATASETS’变量为和自己的数据集相关,修改main函数里面测试图片名,即可利用训练好的模型对几张图片进行检测应用